AudioNotes
1.0.0
Ele pode extrair rapidamente o conteúdo de áudio e vídeo e chamar um modelo grande para organizá-lo em uma nota de redução estruturada para leitura fácil e rápida.
FunASR: https://github.com/modelscope/FunASR
Qwen2: https://ollama.com/library/qwen2
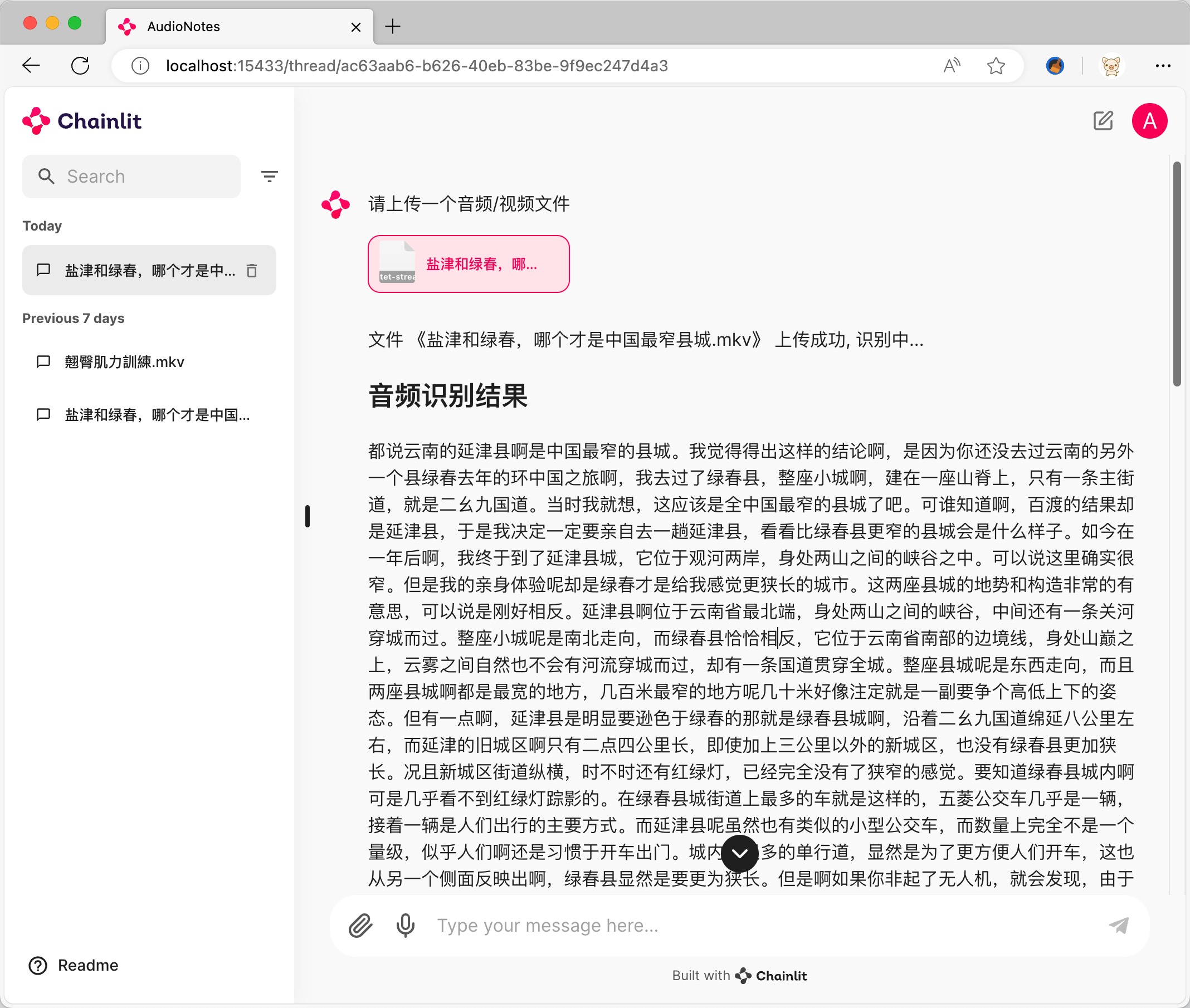
Baixe o pacote de instalação do Ollama correspondente ao sistema e instale-o.
https://ollama.com/download
Tomo阿里的千问2 7b como exemplo https://ollama.com/library/qwen2
ollama pull qwen2:7bExistem dois métodos de implantação, um é implantar usando Docker e o outro é implantar localmente.
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml
docker-compose upDepois que o docker for iniciado, visite http://localhost:15433/
A conta de login é admin e a senha é admin (pode ser modificada no arquivo docker-compose.yml)
É necessário um banco de dados postgresql acessível
conda create -n AudioNotes python=3.10 -y
conda activate AudioNotes
git clone https://github.com/harry0703/AudioNotes.git
cd AudioNotes
pip install -r requirements.txt Renomeie .env.example para .env e modifique as informações de configuração relevantes
chainlit run main.pyApós o serviço ser iniciado, visite http://localhost:8000/
A conta de login é admin e a senha é admin (pode ser modificada no arquivo .env)


