llmjudge
1.0.0
Avaliar LLMs em um cenário aberto é difícil, há um consenso crescente de que faltam benchmarks existentes e profissionais experientes preferem eles próprios verificar os modelos. Recorri a avaliações anedóticas de desenvolvedores e pesquisadores em quem confio, sendo o Chatbot Arena um excelente complemento. A motivação por trás deste repo é o método cada vez mais popular de usar LLMs fortes como juízes de modelos. Este método já existe há alguns meses, com modelos como o JudgeLM e, mais recentemente, o MT-Bench.
Você pode ou não ter visto este tópico. De acordo com os autores do tweet da Arize AI, o uso de LLMs como juiz justifica cautela do servidor, especificamente no que diz respeito ao uso de avaliações de pontuação numérica. Parece que os LLMs são muito ruins no tratamento de intervalos contínuos, o que se torna evidente quando os solicita a avaliar X de 1 a 10. Este repositório é um documento vivo de experimentos que tentam compreender e capturar a fronteira irregular deste problema. Trabalhos recentes estabeleceram uma forte correlação entre MT-Bench e Julgamento Humano (Arena Elo) , o que significa que os LLMs são capazes de ser juízes, então o que está acontecendo aqui?
Abaixo estão os detalhes completos e resultados.
Devido a restrições de custo, inicialmente me concentrarei na tarefa de ortografia/erros ortográficos descrita nos tweets. Estou um pouco preocupado que o X quantitativo desta tarefa contamine os insights deste experimento, mas veremos. Congratulo-me com uma análise mais completa deste fenómeno, os meus resultados devem ser tomados com cautela, dada a experiência limitada
Gerei um conjunto de dados de ortografia ou erros ortográficos, sem saber qual nome é mais apropriado, a partir dos ensaios de Paul Graham. Essa escolha foi principalmente por conveniência, já que usei o conjunto de dados antes ao testar a pressão das janelas de contexto. Extraí um contexto de 3.000 palavras das redações e inseri erros ortográficos em palavras aleatórias com base na proporção de erros ortográficos desejada. Em pseudocódigo:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
O código completo está prontamente disponível como um notebook.
Dado o conjunto de dados gerado, solicitamos aos LLMs que avaliem a quantidade de palavras com erros ortográficos em um contexto usando diferentes modelos de pontuação. Estamos usando as seguintes APIs
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
à temperatura = 0.
Teste 1. Vamos confirmar que os LLMs têm dificuldade para lidar com intervalos numéricos em uma configuração de disparo zero. Solicitamos ao GPT-3.5 e ao GPT-4 um modelo de pontuação numérica, variando de pontuação 0 a 10.
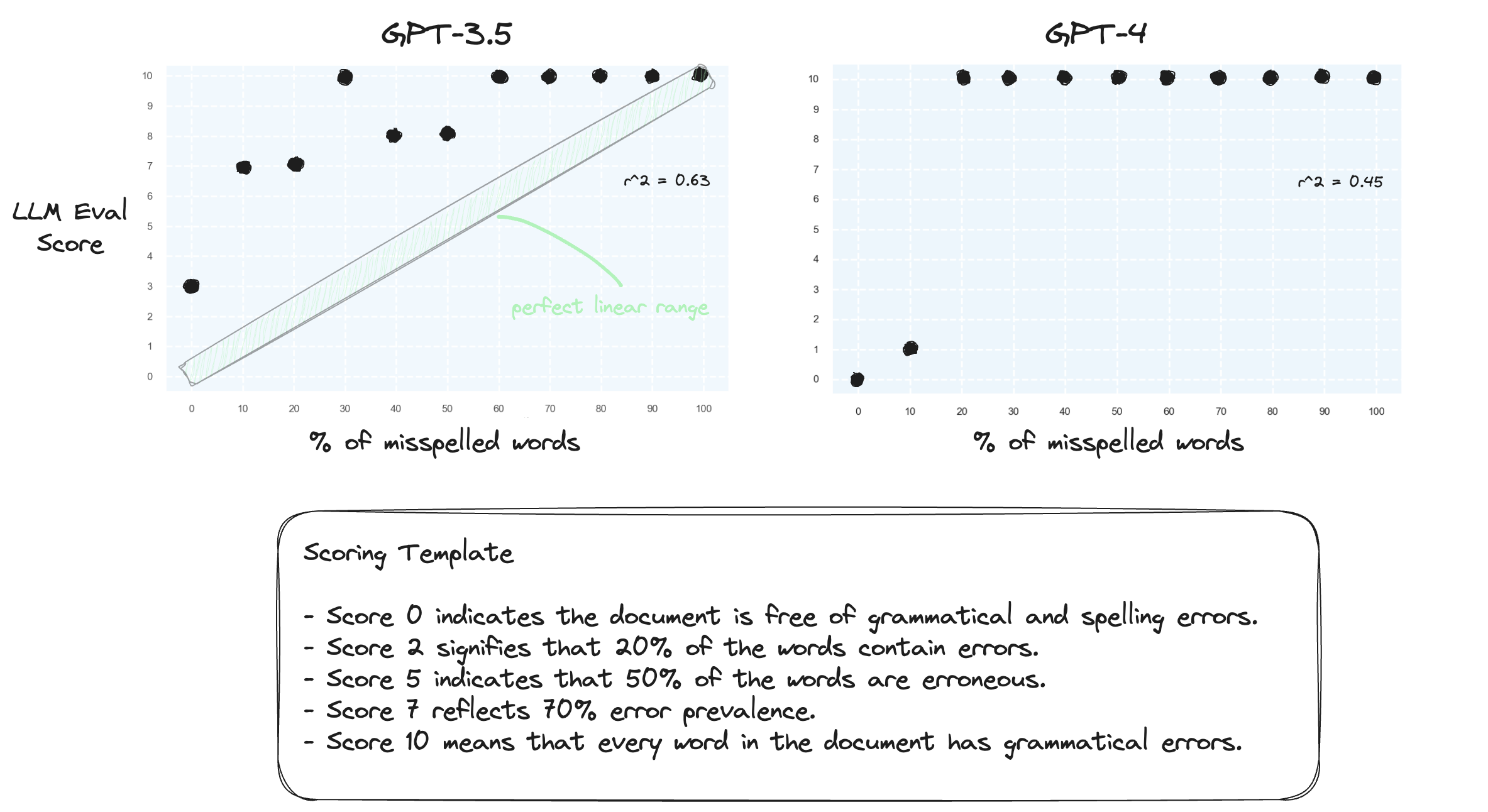
Como esperado, ambos julgam mal severamente.
Teste 2. O que acontece se invertermos o intervalo de pontuação? Agora, uma pontuação de 10 representa um documento com grafia perfeita.
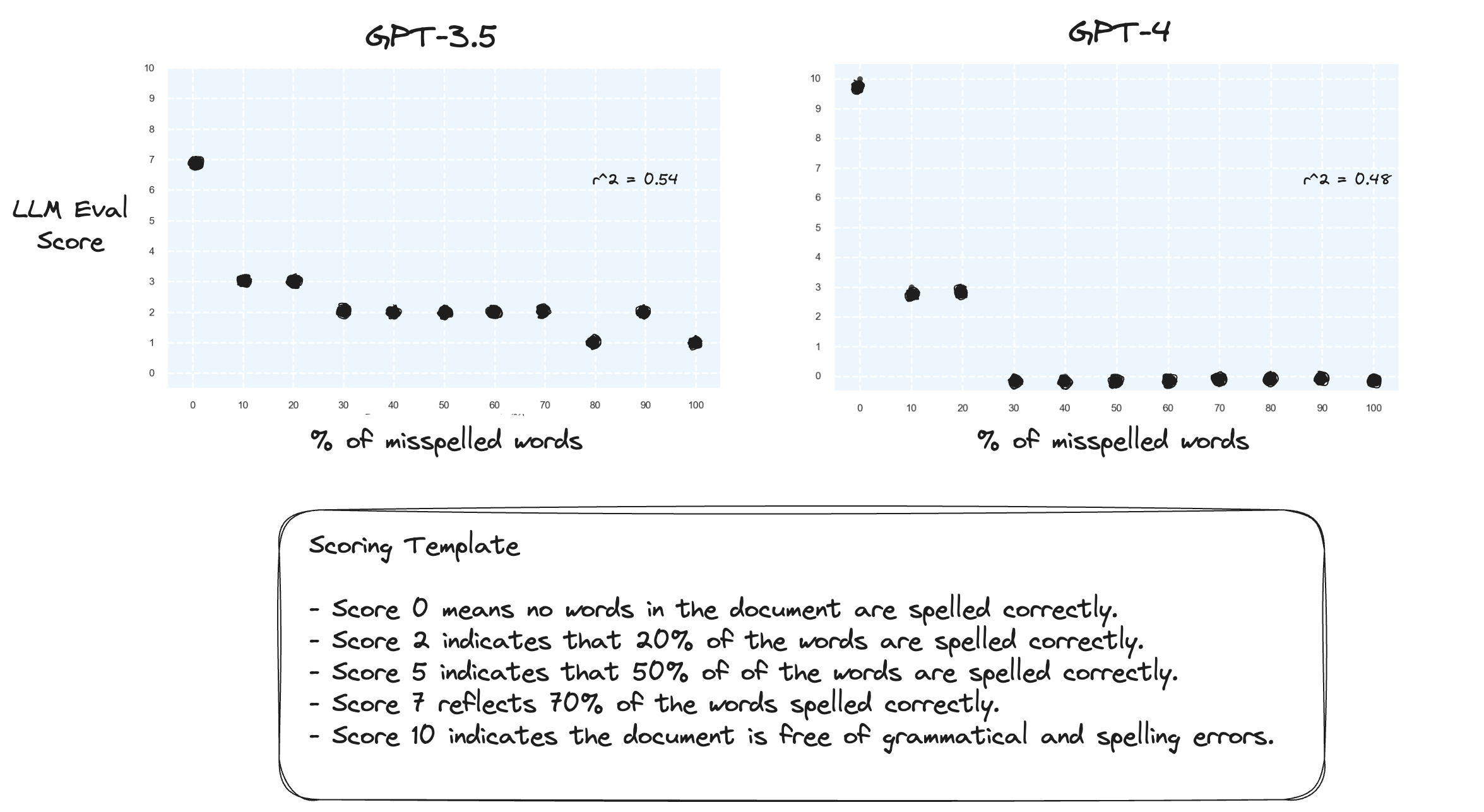
Isso não parece fazer muita diferença.
Teste 3. Se acreditarmos na hipótese de Arize, poderemos ver melhorias se evitarmos uma rubrica de pontuação e, em vez disso, usarmos “notas rotuladas”. Neste caso, decidi descer para uma escala de classificação de 5 pontos.
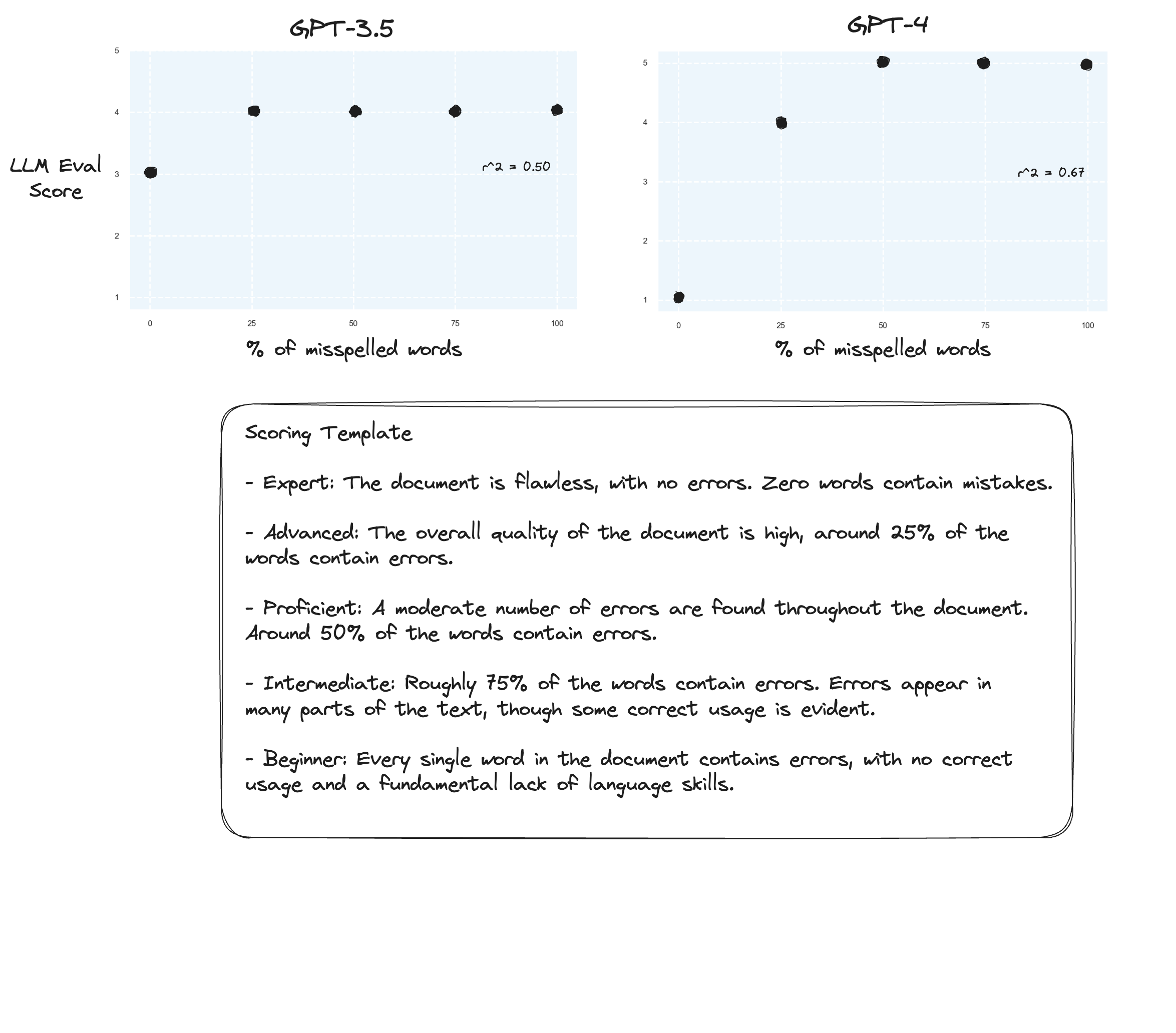
Talvez pequenas melhorias? Difícil dizer honestamente. Não estou impressionado.
Teste 4. E quanto à Cadeia de Pensamento de tiro zero?

gpt-3.5 se transformou em algo sem sentido em dois dos prompts. Como esperado, o gpt-4 apresenta melhorias quando solicitado a pensar em voz alta. Observe como é muito hesitante atribuir uma pontuação de 10.
Teste 5. Conforme sugerido pelo autor de Prometheus; mapear cada pontuação com sua própria explicação provavelmente melhora a capacidade do LLM de avaliar toda a faixa numérica. Isto, combinado com CoT, resulta em:

Melhorias contínuas para gpt-4. Ainda é muito relutante atribuir pontuações limite de 0 e 10.
Teste 6. Depois de ler mais sobre o MT Bench, decidi testar uma abordagem alternativa, usando comparações aos pares em vez de pontuação isolada. Agora, normalmente isso exigiria comparações O(n * log N), mas como já sabemos a ordem, imaginei que testaríamos apenas os casos mais difíceis: comparar 0% de erros ortográficos versus 10% de erros ortográficos, 10% versus 20% e assim por diante para um total de 10 comparações. Observe que também usei CoT de tiro zero.
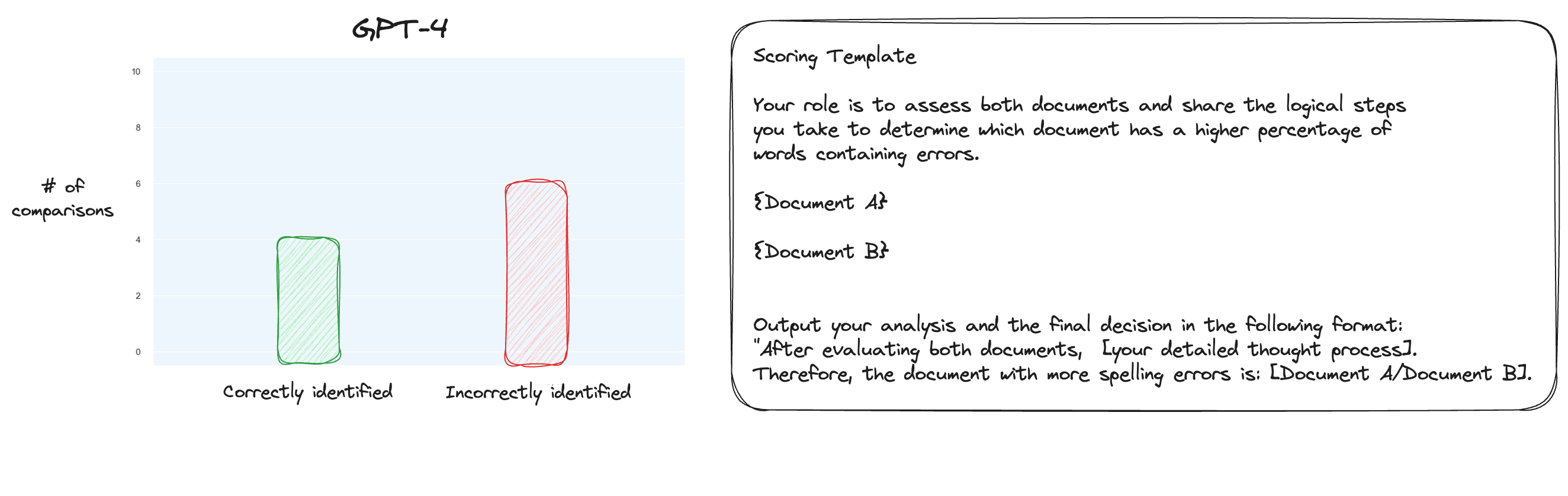
Minha hipótese era que o GPT-4 teria se destacado em um cenário em que comparasse dois textos dentro de sua janela de contexto, mas eu estava errado. Para minha surpresa, isso realmente não melhorou em nada as coisas. Claro, esta é a mais difícil de todas as comparações possíveis, mas no geral ainda é uma tarefa simples. Talvez os aspectos quantitativos desta tarefa sejam inerentemente muito difíceis para os LLMs. Hmm, talvez eu precise encontrar uma tarefa de proxy melhor...
(31/1) Estive examinando os detalhes internos do MT-Bench e fiquei muito surpreso ao descobrir que eles simplesmente pedem ao GPT-4 para pontuar os resultados em uma escala de 1 a 10. Eles fornecem opções alternativas de classificação, como comparações aos pares em relação a uma linha de base, mas a opção recomendada é a numérica. O prompt de julgamento também é inesperadamente simples:
Aja como um juiz imparcial e avalie a qualidade da resposta fornecida por um assistente de IA à pergunta do usuário exibida abaixo. Sua avaliação deve considerar fatores como utilidade, relevância, precisão, profundidade, criatividade e nível de detalhe da resposta. Comece sua avaliação fornecendo uma breve explicação. Seja o mais objetivo possível. Após fornecer sua explicação, você deverá avaliar a resposta em uma escala de 1 a 10 seguindo rigorosamente este formato: [classificação], por exemplo: “Classificação: 5”. [Pergunta] {pergunta} [O início da resposta do assistente] {resposta} [O fim da resposta do assistente]
Se alguém acredita que isso é tudo para julgar no MT-Bench, então estou começando a questionar o uso da tarefa de erro ortográfico como uma tarefa de proxy...
(2/2) Estou interessado em fazer com que o GPT-4 julgue os textos com erros ortográficos por meio de uma comparação aos pares, em vez de uma pontuação isolada. Este é um dos métodos de julgamento alternativos para o MT Bench (embora recomende pontuação isolada), e suspeito que seja mais adequado para esta tarefa. Os resultados do mapeamento completo do CoT + são definitivamente uma melhoria, mas ainda acho que há trabalho a ser feito. A desvantagem da pontuação aos pares é que você precisará de significativamente mais chamadas de API para estabelecer a classificação completa (na prática).


