DreamerGPT
1.0.0
 DreamerGPT: ajuste fino das instruções do modelo em chinês
DreamerGPT: ajuste fino das instruções do modelo em chinês? DreamerGPT é um projeto de ajuste fino de instrução de modelo de língua chinesa iniciado por Xu Hao, Chi Huixuan, Bei Yuanchen e Liu Danyang.
Leia na versão em inglês .

 1. Introdução do projeto
1. Introdução do projetoO objetivo deste projeto é promover a aplicação de modelos chineses de grandes línguas em cenários de campo mais verticais.
Nosso objetivo é diminuir os modelos grandes e ajudar todos a treinar e ter um assistente especializado personalizado em sua área vertical. Ele pode ser um conselheiro psicológico, um assistente de código, um assistente pessoal ou seu próprio professor de idioma, o que significa que. DreamerGPT é um modelo de idioma que apresenta os melhores resultados possíveis, o menor custo de treinamento e é mais otimizado para chinês. O projeto DreamerGPT continuará a abrir o treinamento inicial a quente do modelo de linguagem iterativa (incluindo LLaMa, BLOOM), treinamento de comando, aprendizagem por reforço, ajuste fino de campo vertical e continuará a iterar dados de treinamento confiáveis e alvos de avaliação. Devido ao pessoal e recursos limitados do projeto, a versão V0.1 atual é otimizada para LLaMa chinês para LLaMa-7B e LLaMa-13B, adicionando recursos chineses, alinhamento de idioma e outros recursos. Atualmente, ainda existem deficiências nas capacidades de diálogo longo e no raciocínio lógico. Consulte a próxima versão da atualização para obter mais planos de iteração.
A seguir está uma demonstração de quantização baseada em 8b (o vídeo não está acelerado, a aceleração de inferência e a otimização de desempenho também estão sendo iteradas):
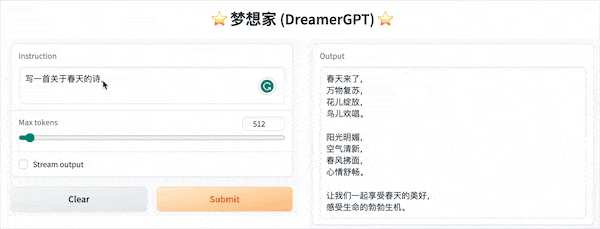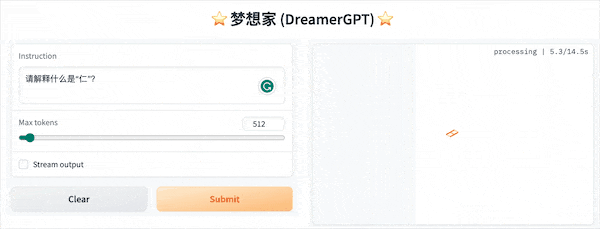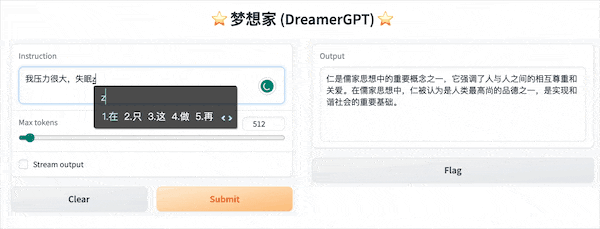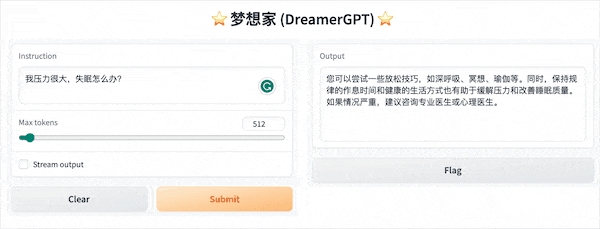
Mais exibições de demonstração:
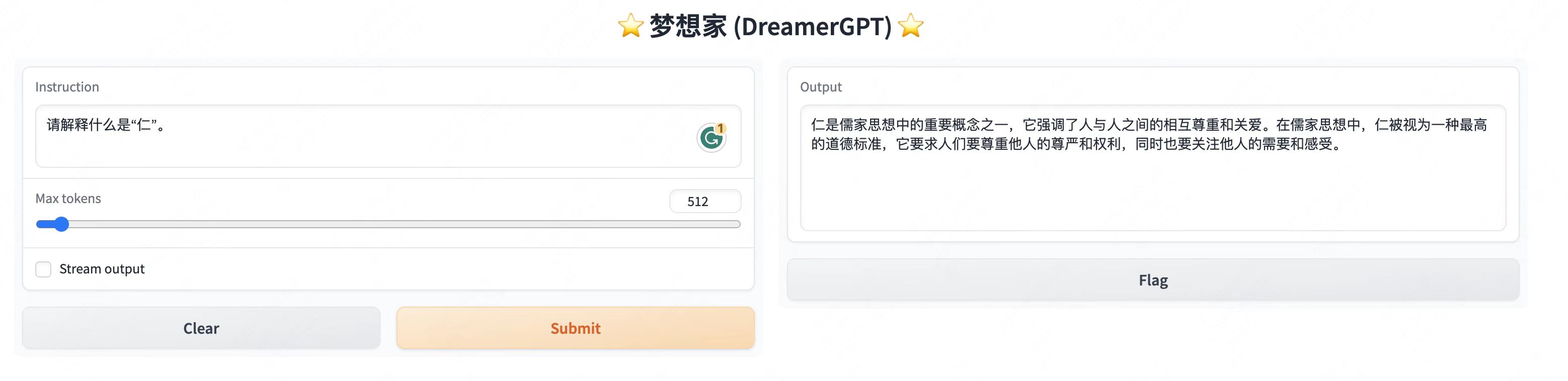

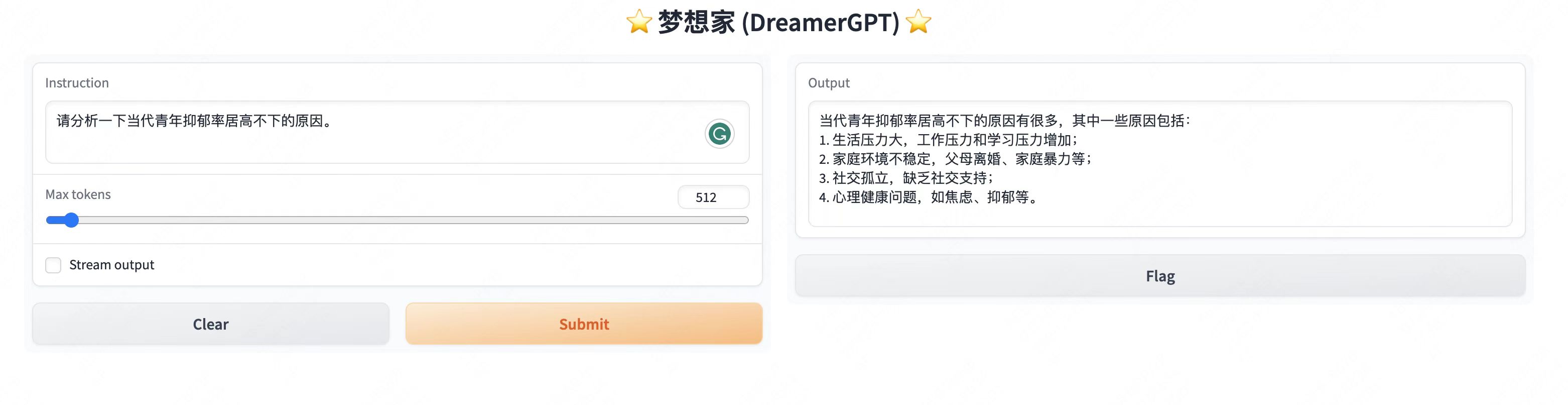
 2. Última atualização
2. Última atualização  [2023/06/17] Atualização da versão V0.2: versão de treinamento incremental LLaMa firefly, versão BLOOM-LoRA (
[2023/06/17] Atualização da versão V0.2: versão de treinamento incremental LLaMa firefly, versão BLOOM-LoRA ( finetune_bloom.py , generate_bloom.py ).
[2023/04/23] Comando chinês de código aberto oficialmente para ajuste fino do grande modelo Dreamer (DreamerGPT) , atualmente fornecendo experiência de download da versão V0.1
Modelos existentes (treinamento incremental contínuo, mais modelos a serem atualizados):
| Nome do modelo | dados de treinamento = | Baixar peso |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + trem-vaga-lume-1 | [Abraçando o rosto] |
| D7b-5-1 | D7b-4-1 + trem-vaga-lume-1 | [Abraçando o rosto] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chinese-alpaca-lora-13b-hot start + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D13b-2-2-2 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate | [Google Drive] [HuggingFace] |
| D13b-2-3 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D7b-4-1 | Chinês-alpaca-lora-7b-hotstart+firefly-train-0 | [Google Drive] [HuggingFace] |
Visualização da avaliação do modelo
 3. Modelo e preparação de dados
3. Modelo e preparação de dadosDownload do peso do modelo:
Os dados são processados uniformemente no seguinte formato JSON:
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Script de download e pré-processamento de dados:
| dados | tipo |
|---|---|
| Alpaca-GPT4 | Inglês |
| Firefly (pré-processado em múltiplas cópias, alinhamento de formato) | chinês |
| COIG | Chinês, código, chinês e inglês |
| PsyQA (pré-processado em múltiplas cópias, alinhado ao formato) | Aconselhamento psicológico chinês |
| BELA | chinês |
| baeta | Conversa chinesa |
| Dísticos (pré-processados em múltiplas cópias, alinhados ao formato) | chinês |
Nota: Os dados vêm da comunidade de código aberto e podem ser acessados através de links.
 4. Código e scripts de treinamento
4. Código e scripts de treinamentoIntrodução de código e script:
finetune.py : Instruções para ajustar o código de inicialização a quente/treinamento incrementalgenerate.py : código de inferência/testescripts/ : executa scriptsscripts/rerun-2-alpaca-13b-2.sh , consulte scripts/README.md para obter explicação de cada parâmetro.  5. Como usar
5. Como usarConsulte Alpaca-LoRA para obter detalhes e perguntas relacionadas.
pip install -r requirements.txtFusão de peso (tomando alpaca-lora-13b como exemplo):
cd scripts/
bash merge-13b-alpaca.shSignificado do parâmetro (modifique você mesmo o caminho relevante):
--base_model , peso original da lhama--lora_model , peso de lhama chinesa/alpaca-lora--output_dir , caminho para gerar pesos de fusãoTome o seguinte processo de treinamento como exemplo para mostrar o script em execução.
| começar | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaca-lora-13b-hot start, número do experimento: 2 | Dados: firefly-train-0 | Dados: COIG-part1, COIG-translate | Dados: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shExplicação de parâmetros importantes (modifique você mesmo os caminhos relevantes):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 Se o conjunto de dados em si for relativamente pequeno, ele pode ser reduzido adequadamente, como 500, 200Observe que se quiser baixar diretamente os pesos ajustados para inferência, você pode ignorar 5.3 e prosseguir diretamente para 5.4.
Por exemplo, quero avaliar os resultados do ajuste fino rerun-2-alpaca-13b-2.sh :
1. Interação da versão web:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Inferência em lote e salvamento de resultados:
cd scripts/
bash save-generate-2-alpaca-13b-2.shExplicação de parâmetros importantes (modifique você mesmo os caminhos relevantes):
--is_ui False : Quer seja uma versão web, o padrão é True--test_input_path 'xxx.json' : caminho da instrução de entradatest.json no diretório de peso LoRA correspondente por padrão.  6. Relatório de avaliação
6. Relatório de avaliação Existem atualmente 8 tipos de tarefas de teste nas amostras de avaliação (ética numérica e diálogo Duolun a serem avaliados), cada categoria tem 10 amostras, e a versão quantificada de 8 bits é pontuada de acordo com a interface que chama GPT-4/GPT 3.5 ( versão não quantificada tem uma pontuação mais alta), cada amostra é pontuada em um intervalo de 0 a 10. Consulte test_data/ para exemplos de avaliação.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Nota: A pontuação é apenas para referência (em comparação com GPT 3.5). A pontuação do GPT 4 é mais precisa e informativa.
| Tarefas de teste | Exemplo detalhado | Número de amostras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | Bate-papoGPT |
|---|---|---|---|---|---|---|---|
| Pontuação total para cada item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Curiosidades | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| traduzir | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| geração de texto | 03generate.json | 10 | 56 | 65* | 55 | 61 | 91 |
| análise de sentimento | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| compreensão de leitura | 05entendimento.json | 10 | 74* | 74* | 74* | 76,5 | 96,5 |
| Características chinesas | 06chinês.json | 10 | 69* | 69* | 69* | 43 | 86 |
| geração de código | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Ética, Recusa em Responder | 08alignment.json | 10 | 87* | 87* | 87* | 71 | 95,5 |
| raciocínio matemático | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
| Múltiplas rodadas de diálogo | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
| Tarefas de teste | Exemplo detalhado | Número de amostras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | Bate-papoGPT |
|---|---|---|---|---|---|---|---|
| Pontuação total para cada item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Curiosidades | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| traduzir | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| geração de texto | 03generate.json | 10 | 65 | 73* | 63 | 71 | 92 |
| análise de sentimento | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| compreensão de leitura | 05entendimento.json | 10 | 75 | 77 | 76 | 85* | 91 |
| Características chinesas | 06chinês.json | 10 | 82* | 83 | 82* | 40 | 68 |
| geração de código | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Ética, Recusa em Responder | 08alignment.json | 10 | 71* | 70 | 67 | 71* | 94 |
| raciocínio matemático | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
| Múltiplas rodadas de diálogo | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
No geral, o modelo tem bom desempenho em tradução , análise de sentimento , compreensão de leitura , etc.
Duas pessoas pontuaram manualmente e depois tiraram a média.
| Tarefas de teste | Exemplo detalhado | Número de amostras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | Bate-papoGPT |
|---|---|---|---|---|---|---|---|
| Pontuação total para cada item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Curiosidades | 01qa.json | 10 | 83* | 82 | 82 | 69,75 | 96,25 |
| traduzir | 02translate.json | 10 | 76,5* | 76,5* | 76,5* | 62,5 | 84 |
| geração de texto | 03generate.json | 10 | 44 | 51,5* | 43 | 47 | 81,5 |
| análise de sentimento | 04analyse.json | 10 | 89* | 89* | 89* | 85,5 | 91 |
| compreensão de leitura | 05entendimento.json | 10 | 69* | 69* | 69* | 75,75 | 96 |
| Características chinesas | 06chinês.json | 10 | 55* | 55* | 55* | 37,5 | 87,5 |
| geração de código | 07code.json | 10 | 61,5* | 61,5* | 61,5* | 57 | 88,5 |
| Ética, Recusa em Responder | 08alignment.json | 10 | 84* | 84* | 84* | 70 | 95,5 |
| ética numérica | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
| Múltiplas rodadas de diálogo | (a ser avaliado) | -- | -- | -- | -- | -- | -- |
 7. Conteúdo de atualização da próxima versão
7. Conteúdo de atualização da próxima versãoLista de tarefas:
 Limitações, restrições de uso e isenções de responsabilidade
Limitações, restrições de uso e isenções de responsabilidadeO modelo SFT treinado com base em dados atuais e modelos básicos ainda apresenta os seguintes problemas em termos de eficácia:
Instruções factuais podem levar a respostas incorretas que vão contra os fatos.
Instruções prejudiciais não podem ser devidamente identificadas, o que pode levar a comentários discriminatórios, prejudiciais e antiéticos.
As capacidades do modelo ainda precisam ser melhoradas em alguns cenários que envolvem raciocínio, codificação, múltiplas rodadas de diálogo, etc.
Com base nas limitações do modelo acima, exigimos que o conteúdo deste projeto e subsequentes derivados gerados por este projeto só possam ser utilizados para fins de pesquisa acadêmica e não para fins comerciais ou usos que causem danos à sociedade. O desenvolvedor do projeto não assume qualquer dano, perda ou responsabilidade legal causada pelo uso deste projeto (incluindo, mas não se limitando a dados, modelos, códigos, etc.).
 Citar
CitarSe você usar o código, dados ou modelos deste projeto, cite este projeto.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Contate-nos
Contate-nosAinda existem muitas deficiências neste projeto. Por favor, deixe suas sugestões e dúvidas e faremos o possível para melhorar este projeto.
E-mail: [email protected]



