datalens
1.0.0
Este é um experimento pessoal que usa LLMs para classificar dados de trabalho não estruturados com base em critérios definidos pelo usuário. As plataformas tradicionais de procura de emprego dependem de sistemas de filtragem rígidos, mas muitos utilizadores não possuem esses critérios concretos. Datalens permite que você defina suas preferências de uma forma mais natural e depois classifique cada anúncio de emprego com base na relevância.
Alguns critérios podem ser mais importantes que outros, por isso os "critérios obrigatórios" têm uma ponderação duas vezes maior que os critérios normais.
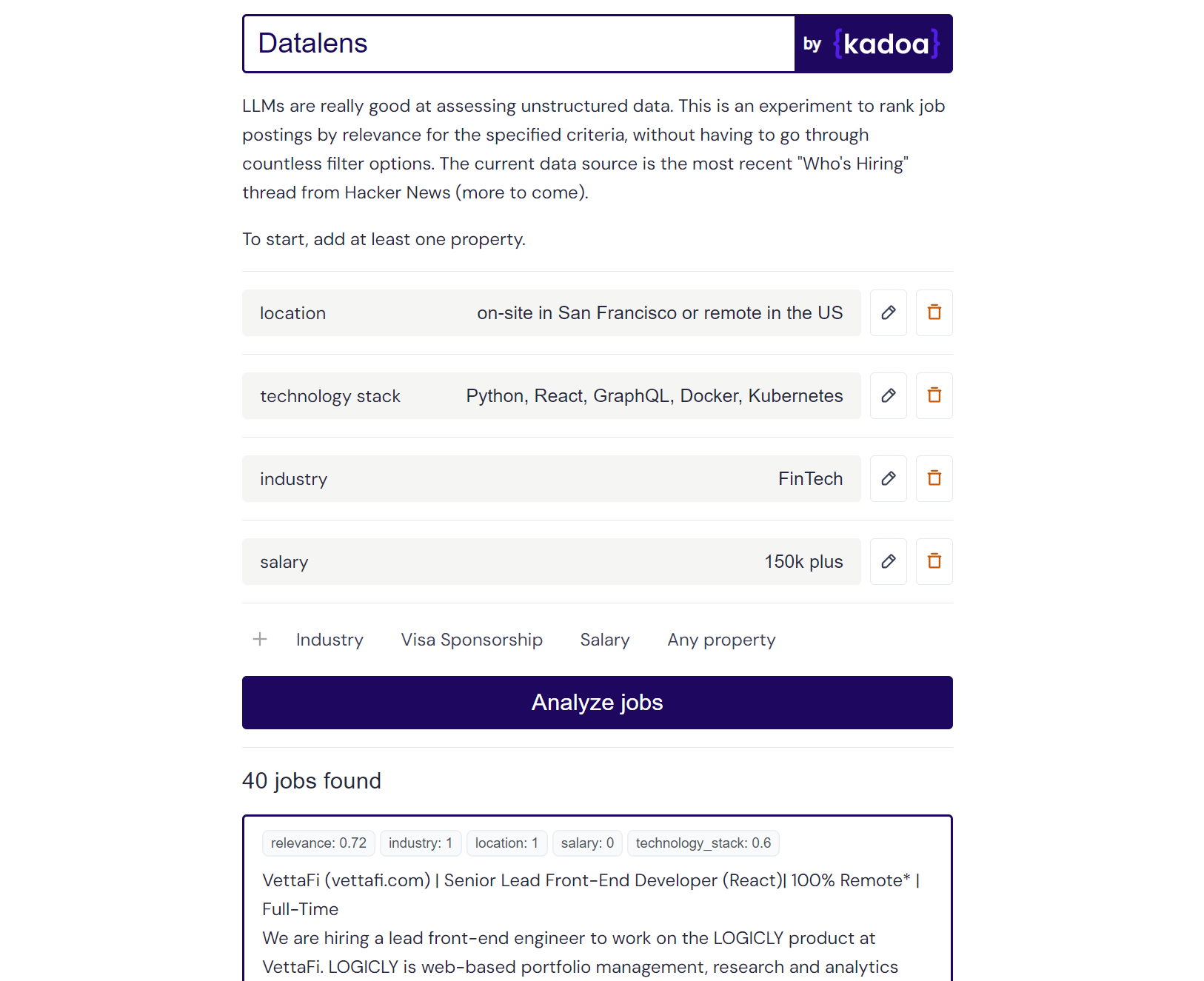
Resultado do exemplo Claude-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Você pode adicionar qualquer fonte de dados de trabalho que desejar. Eu o pré-configurei com o tópico "Quem está contratando" mais recente do Hacker News, mas você pode adicionar suas próprias fontes.
Adicione novas fontes de trabalho atualizando sources_config.json. Exemplo:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
Usei minha própria ferramenta Kadoa para buscar os dados do trabalho nas páginas da empresa, mas você pode usar qualquer outro método tradicional de extração.
Aqui estão alguns endpoints públicos prontos para obter todas as ofertas de emprego dessas empresas (atualizados diariamente):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Deixe-me saber se devo adicionar outras empresas. Além disso, temos o prazer de lhe oferecer acesso experimental ao Kadoa.
A pontuação de relevância funciona melhor com gpt-4-0613 , que retorna pontuações granulares entre 0-1. claude-2 também funciona muito bem se você tiver acesso a ele. gpt-3.5-turbo-0613 pode ser usado, mas geralmente retorna pontuações binárias de 0 ou 1 para critérios, sem a nuance para distinguir entre correspondências parciais e completas.
O modelo padrão é gpt-3.5-turbo-0613 por motivos de custo. Você pode mudar de GPT para Claude substituindo use_claude por use_openai .
A execução contínua deste script pode resultar em alto uso da API, portanto, use-o com responsabilidade. Estou registrando o custo de cada chamada GPT.
Para executar o aplicativo, você precisa de:
Copie o arquivo .env.example e preencha-o.
Execute o servidor Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Navegue até o diretório do cliente e instale as dependências do Node:
cd client
npm install
Execute o cliente Next.js:
cd client
npm run dev


