ShapeGPT
1.0.0

Página do projeto • Artigo Arxiv • Demonstração • Perguntas frequentes • Citação
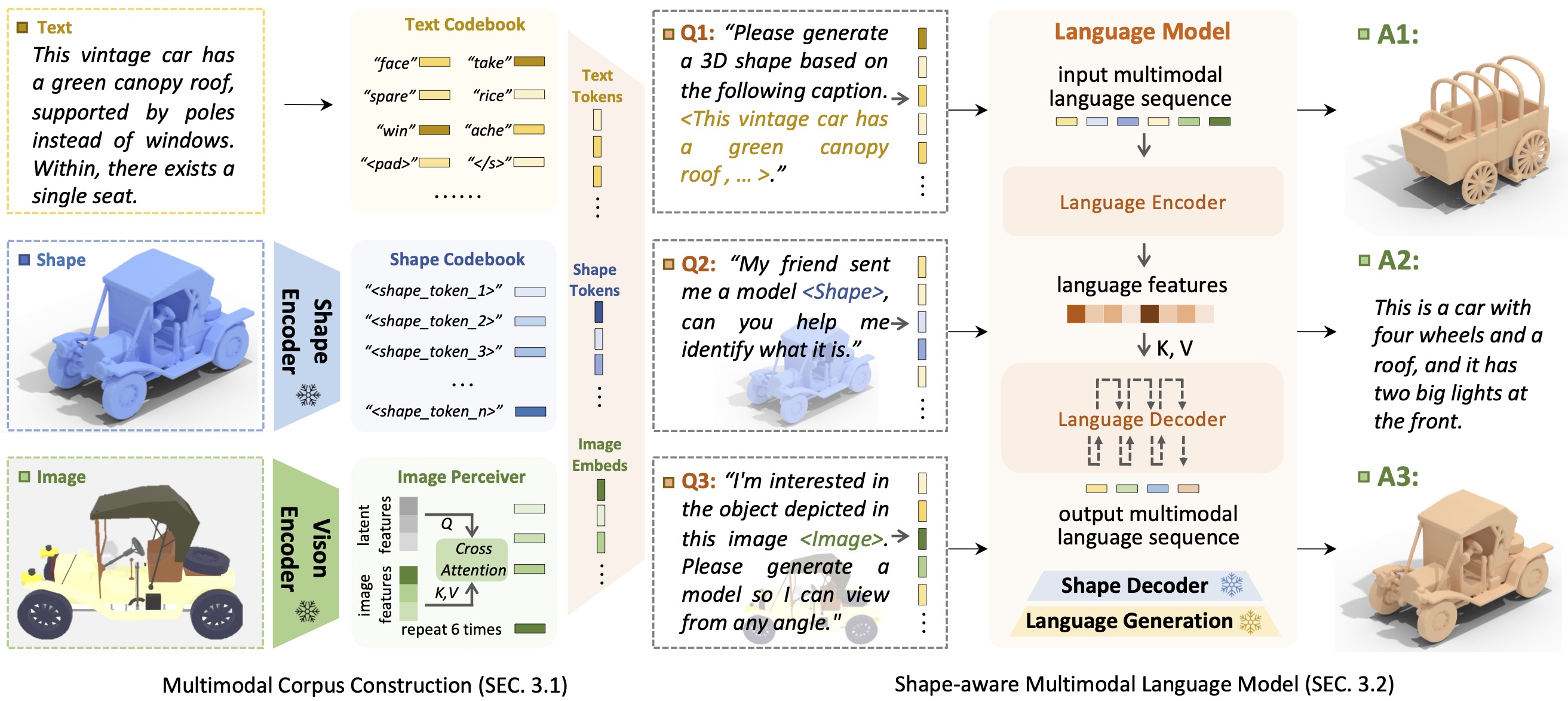
Forma de introduçãoGPTShapeGPT é um modelo de linguagem multimodal centrado na forma unificado e fácil de usar para estabelecer um corpus multimodal e desenvolver modelos de linguagem com reconhecimento de forma em múltiplas tarefas de forma .
O advento de grandes modelos de linguagem, permitindo flexibilidade através de abordagens orientadas para a instrução, revolucionou muitas tarefas generativas tradicionais, mas grandes modelos para dados 3D, particularmente no tratamento abrangente de formas 3D com outras modalidades, ainda são pouco explorados. Ao alcançar gerações de formas baseadas em instruções, modelos versáteis de formas generativas multimodais podem beneficiar significativamente vários campos, como construção virtual 3D e design auxiliado por rede. Neste trabalho, apresentamos o ShapeGPT, uma estrutura multimodal incluída na forma para aproveitar modelos de linguagem pré-treinados fortes para abordar múltiplas tarefas relevantes para a forma. Especificamente, o ShapeGPT emprega uma estrutura palavra-frase-parágrafo para discretizar formas contínuas em palavras moldadas, monta ainda mais essas palavras para formar sentenças, bem como integra a forma com texto instrucional para parágrafos multimodais. Para aprender esse modelo de linguagem de forma, usamos um esquema de treinamento de três estágios, incluindo representação de forma, alinhamento multimodal e geração baseada em instruções, para alinhar livros de código de linguagem de forma e aprender as intrincadas correlações entre essas modalidades. Extensos experimentos demonstram que o ShapeGPT alcança desempenho comparável em tarefas relevantes para formas, incluindo texto para forma, forma para texto, conclusão de forma e edição de forma.
Se você achar que nosso código ou artigo ajuda, considere citar:
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Graças ao modelo T5, Motion-GPT, Perceiver-IO e SDFusion, nosso código é parcialmente emprestado deles. Nossa abordagem é inspirada em Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox e 3DShape2VecSet.
Este código é distribuído sob uma LICENÇA MIT.
Observe que nosso código depende de outras bibliotecas, incluindo PyTorch3D e PyTorch Lightning, e usa conjuntos de dados, cada um com suas respectivas licenças que também devem ser seguidas.


