Indian LawyerGPT
1.0.0
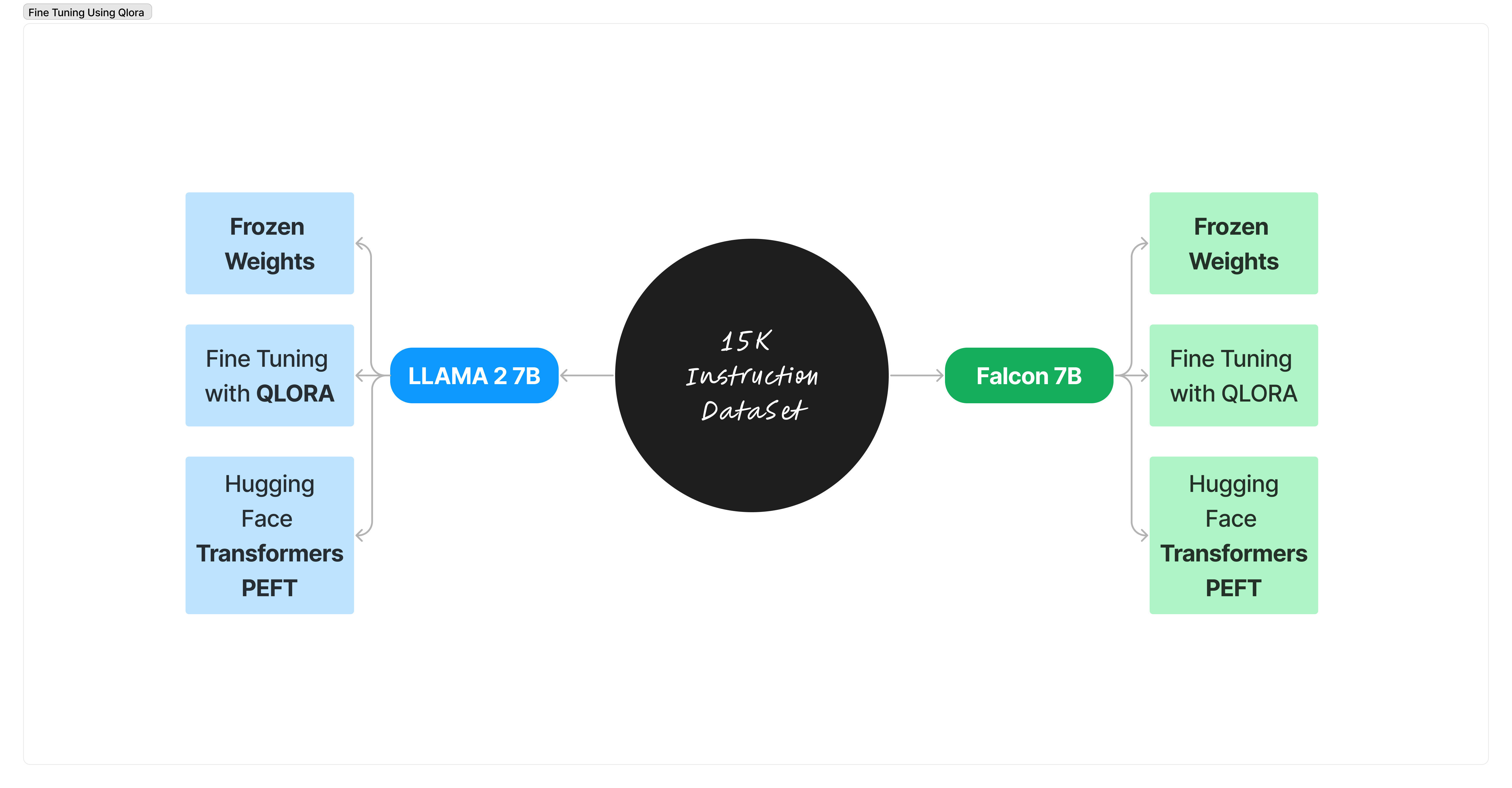
Bem-vindo ao nosso emocionante projeto onde estamos adaptando dois modelos de linguagem de ponta, Falcon-7B e LLAMA 2, para nos tornarmos proficientes na legislação indiana.
Nossa aventura começou com modestas 150 perguntas e respostas sobre a legislação indiana. Agora, estamos avançando com um conjunto de dados impressionante de 3.300 instruções! Este projeto jurídico de IA combina:

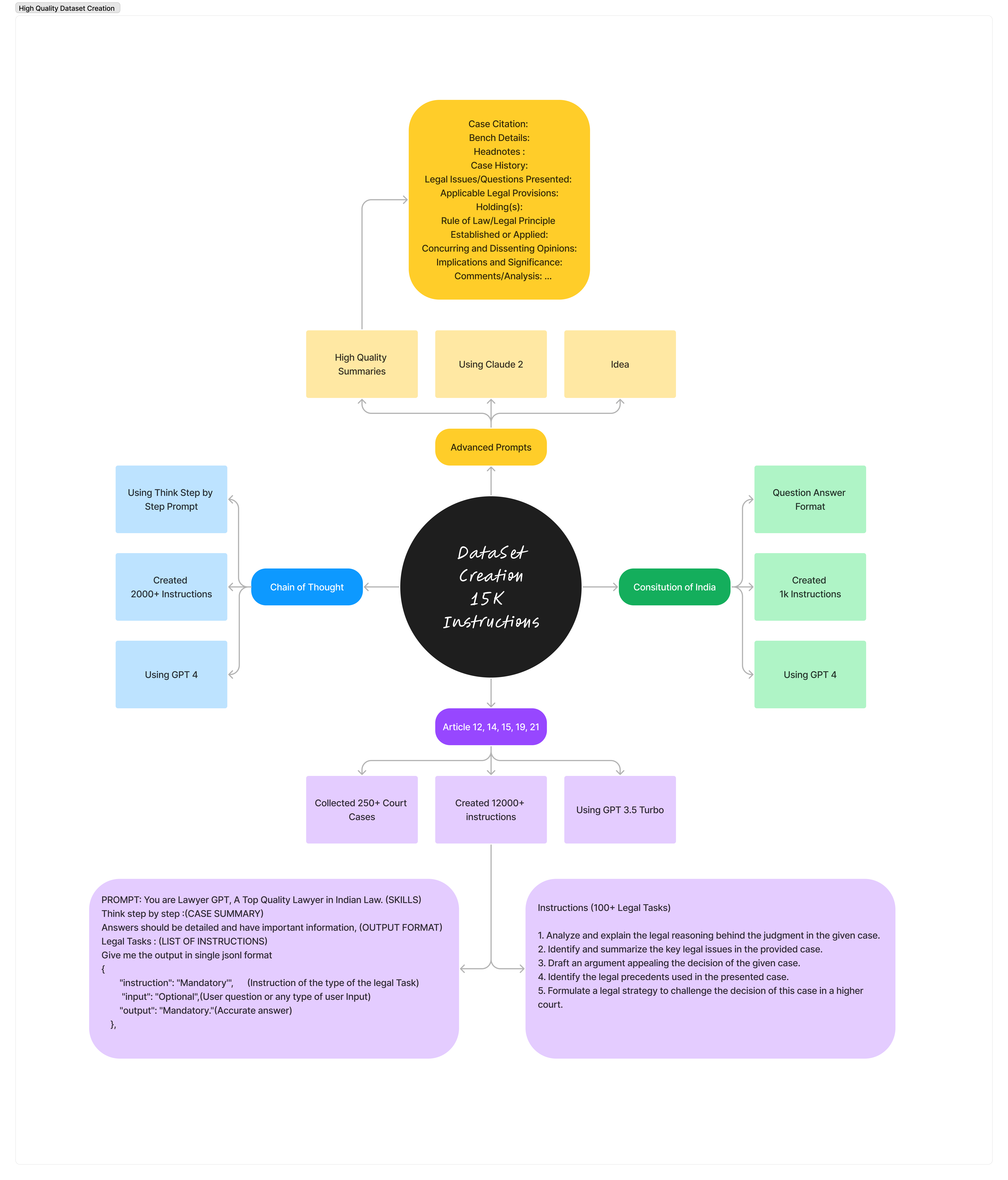
Nosso conjunto de dados foi projetado com quatro recursos principais: instruction , input , output e prompt . Criado para transformar nossos modelos em especialistas em direito de IA! Conjunto de dados sobre Hugging Face: https://huggingface.co/datasets/nisaar/Constitution_Of_India_Instruction_Set https://huggingface.co/datasets/nisaar/Articles_Constitution_3300_Instruction_Set https://huggingface.co/datasets/nisaar/LLAMA2_Legal_Dataset_4.4k_Instructions
Obtenha um lugar na primeira fila para acompanhar o progresso do treinamento com o TensorBoard. Inicie-o, navegue até o link localhost fornecido e testemunhe o aprendizado dos modelos:


