multimedia gpt
1.0.0
Multimedia GPT conecta seu OpenAI GPT com visão e áudio. Agora você pode enviar imagens, gravações de áudio e documentos PDF usando sua chave de API OpenAI e obter uma resposta em formatos de texto e imagem. No momento, estamos adicionando suporte para vídeos. Tudo é possível graças a um gerenciador de prompt inspirado e desenvolvido no Microsoft Visual ChatGPT.
Além de todos os modelos de base de visão mencionados no Microsoft Visual ChatGPT, o Multimedia GPT oferece suporte a OpenAI Whisper e OpenAI DALLE! Isso significa que você não precisa mais de suas próprias GPUs para reconhecimento de voz e geração de imagens (embora ainda possa!)
O modelo básico de chat pode ser configurado como qualquer OpenAI LLM , incluindo ChatGPT e GPT-4. O padrão é text-davinci-003 .
Você está convidado a bifurcar este projeto e adicionar modelos adequados ao seu caso de uso. Uma maneira simples de fazer isso é através do llama_index. Você terá que criar uma nova classe para o seu modelo em model.py e adicionar um método executor run_<model_name> em multimedia_gpt.py . Veja run_pdf para ver um exemplo.
Nesta demonstração, o ChatGPT é alimentado com a gravação de uma pessoa contando a história da Cinderela.
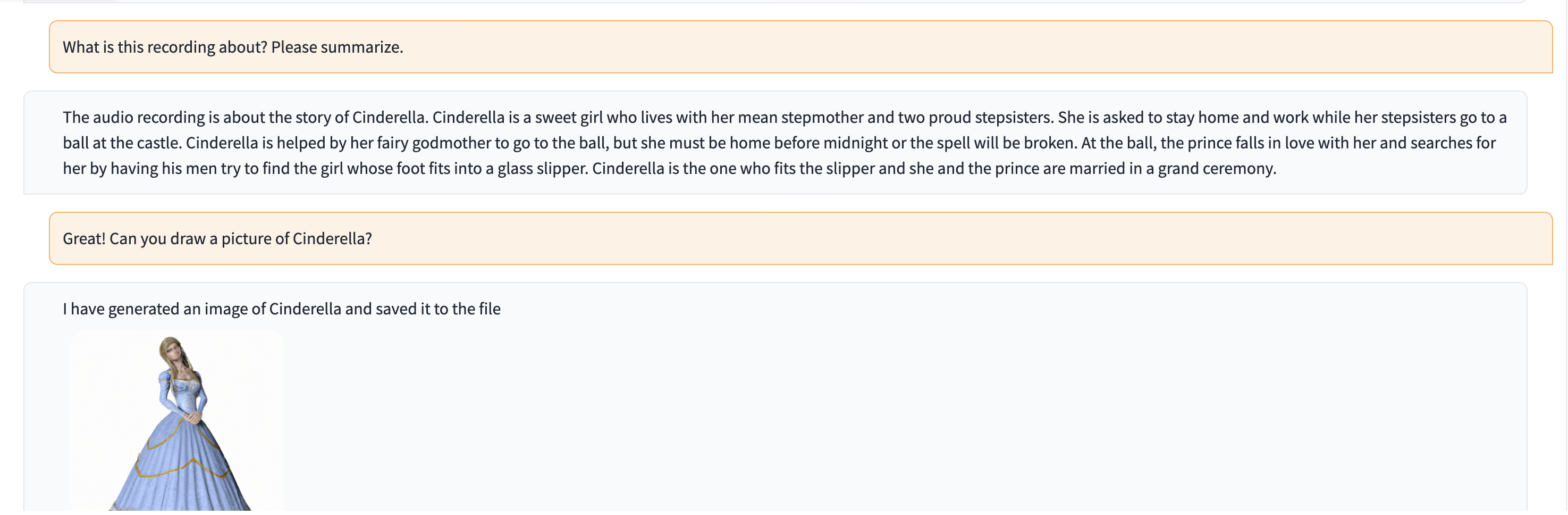
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Este projeto é um trabalho experimental e não será implantado em um ambiente de produção. Nosso objetivo é explorar o poder da inspiração.


