SwiftInfer
1.0.0
Streaming-LLM é uma técnica para suportar comprimento de entrada infinito para inferência LLM. Ele aproveita o Attention Sink para evitar o colapso do modelo quando a janela de atenção muda. O trabalho original é implementado em PyTorch, oferecemos SwiftInfer , uma implementação TensorRT para tornar o StreamingLLM mais de nível de produção. Nossa implementação foi baseada no projeto TensorRT-LLM lançado recentemente.
Usamos a API no TensorRT-LLM para construir o modelo e executar a inferência. Como a API do TensorRT-LLM não é estável e muda rapidamente, vinculamos nossa implementação ao commit 42af740db51d6f11442fd5509ef745a4c043ce51 cuja versão é v0.6.0 . Podemos atualizar este repositório à medida que as APIs do TensorRT-LLM se tornam mais estáveis.
Se você construiu o TensorRT-LLM V0.6.0 , simplesmente execute:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .Caso contrário, você deve instalar o TensorRT-LLM primeiro.
Se estiver usando o docker, você pode seguir a instalação do TensorRT-LLM para instalar o TensorRT-LLM V0.6.0 .
Usando o docker, você pode instalar o SwiftInfer simplesmente executando:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Se não estiver usando o docker, fornecemos um script para instalar o TensorRT-LLM automaticamente.
Pré-requisitos
Certifique-se de ter instalado os seguintes pacotes:
Certifique-se de que a versão do TensorRT >= 9.1.0 e do kit de ferramentas CUDA >= 12.2.
Para instalar o tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Para baixar o nccl, siga a página de download do NCCL.
Para baixar o cudnn, siga a página de download do cuDNN.
Comandos
Antes de executar os comandos a seguir, certifique-se de ter configurado nvcc corretamente. Para verificar, execute:
nvcc --versionPara instalar TensorRT-LLM e SwiftInfer, execute:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Para executar o exemplo Llama, você precisa primeiro clonar o repositório Hugging Face para o modelo meta-llama/Llama-2-7b-chat-hf ou outras variantes baseadas em Llama, como lmsys/vicuna-7b-v1.3. Em seguida, você pode executar o seguinte comando para construir o mecanismo TensorRT. Você precisa substituir <model-dir> pelo caminho real para o modelo Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1Em seguida, você precisa baixar os dados do MT-Bench fornecidos pelo LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlFinalmente, você está pronto para executar o exemplo do Llama com o seguinte comando.
❗️❗️❗️ Antes disso, observe que:
only_n_first é usado para controlar o número de amostras a serem avaliadas. Se você quiser avaliar todas as amostras, remova este argumento. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Você deve esperar ver a geração sair da seguinte forma:
Comparamos nossas implementações de Streaming-LLM com a versão original do PyTorch. O comando de benchmark para nossa implementação é fornecido na seção Executar exemplo de Llama, enquanto o da implementação original do PyTorch é fornecido na pasta torch_streamingllm. O hardware utilizado está listado abaixo:
Os resultados (20 rodadas de conversas) são:
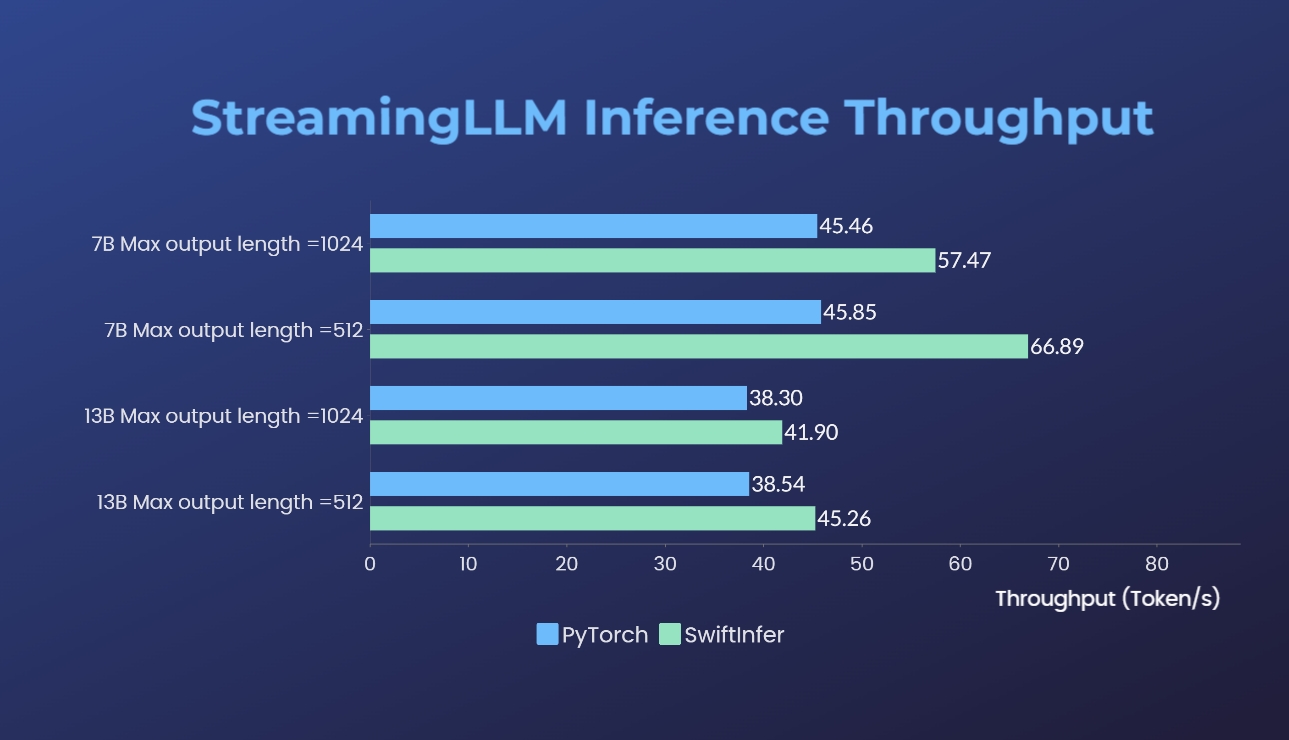
Ainda estamos trabalhando em melhorias adicionais de desempenho e na adaptação às APIs TensorRT V0.7.1. Também notamos que o TensorRT-LLM integrou o StreamingLLM em seu exemplo, mas parece que é mais adequado para geração de texto único em vez de conversas multi-rodadas.
Este trabalho é inspirado no Streaming-LLM para torná-lo utilizável para produção. Ao longo do desenvolvimento, referenciamos os seguintes materiais e desejamos reconhecer seus esforços e contribuições para a comunidade de código aberto e a academia.
Se você achar o StreamingLLM e nossa implementação do TensorRT úteis, por favor, cite nosso repositório e o trabalho original proposto por Xiao et al. do Laboratório Han do MIT.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

