paxml
paxml release 1.4.0
Pax é uma estrutura para configurar e executar experimentos de aprendizado de máquina em cima do Jax.
Consulte esta página para obter uma documentação mais completa sobre como iniciar um projeto do Cloud TPU. O comando a seguir é suficiente para criar uma VM do Cloud TPU com oito núcleos em uma máquina corporativa.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Se você estiver usando fatias de TPU Pod, consulte este guia. Execute todos os comandos de uma máquina local usando gcloud com a opção --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "As seções de início rápido a seguir pressupõem que você execute em uma TPU de host único, para que você possa fazer ssh na VM e executar os comandos lá.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEDepois de fazer ssh na VM, você pode instalar a versão estável do paxml do PyPI ou a versão dev do github.
Para instalar a versão estável do PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Se você encontrar problemas com dependências transitivas e estiver usando o ambiente nativo de VM do Cloud TPU, navegue até a ramificação de lançamento correspondente rX.YZ e faça download paxml/pip_package/requirements.txt . Este arquivo inclui as versões exatas de todas as dependências transitivas necessárias no ambiente nativo da VM do Cloud TPU, no qual criamos/testamos a versão correspondente.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtPara instalar a versão dev do github e para facilitar a edição do código:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueVisite nossa pasta de documentos para documentações e tutoriais do Jupyter Notebook. Consulte a seção a seguir para obter instruções sobre como executar Jupyter Notebooks em uma VM Cloud TPU.
Você pode executar os notebooks de exemplo na VM TPU na qual acabou de instalar o paxml. ####Etapas para ativar um notebook em uma v4-8
ssh na VM TPU com encaminhamento de porta gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
instale o notebook jupyter no TPU vm e faça downgrade do markupsafe
pip install notebook
pip install markupsafe==2.0.1
exportar caminho jupyter export PATH=/home/$USER/.local/bin:$PATH
scp os notebooks de exemplo para sua VM TPU gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
inicie o notebook jupyter a partir da VM TPU e observe o token gerado pelo notebook jupyter jupyter notebook --no-browser --port=8080
em seguida, em seu navegador local, acesse: http://localhost:8080/ e insira o token fornecido
Nota: Caso você precise começar a usar um segundo notebook enquanto o primeiro notebook ainda estiver ocupando as TPUs, você pode executar pkill -9 python3 para liberar as TPUs.
Observação: a NVIDIA lançou uma versão atualizada do Pax com suporte para H100 FP8 e amplas melhorias de desempenho de GPU. Visite o repositório NVIDIA Rosetta para obter mais detalhes e instruções de uso.
O fluxo de trabalho do Profile Guided Latency Estimator (PGLE) mede o tempo de execução real da computação e dos coletivos, e as informações do perfil são realimentadas no compilador XLA para uma melhor decisão de agendamento.
O Estimador de Latência Guiado por Perfil pode ser usado manualmente ou automaticamente. No modo automático, o JAX coletará informações de perfil e recompilará um módulo em uma única execução. Enquanto estiver no modo manual, você precisa executar uma tarefa duas vezes, a primeira para coletar e salvar perfis e a segunda para compilar e executar com os dados fornecidos.
O PGLE automático pode ser ativado definindo as seguintes variáveis de ambiente:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Ou no JAX isso pode ser definido da seguinte forma:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Você pode controlar a quantidade de novas execuções usadas para coletar dados de perfil alterando JAX_PGLE_PROFILING_RUNS . Aumentar este parâmetro levaria a melhores informações de perfil, mas também aumentaria a quantidade de etapas de treinamento não otimizadas.
Os parâmetros JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY permitem usar retornos de chamada de host com o PGLE automático.
Diminuir o parâmetro JAX_PGLE_AGGREGATION_PERCENTILE pode ajudar caso o desempenho entre as etapas seja muito barulhento para filtrar medidas não relevantes.
Atenção: O Auto PGLE não funciona para módulos pré-compilados. Como o JAX precisa recompilar o módulo durante a execução, o auto PGLE não funcionará nem para AoT nem para o seguinte caso:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Se você ainda quiser usar um Estimador de Latência Guiado por Perfil manual, o fluxo de trabalho em XLA/GPU é:
Você poderia fazer isso definindo:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) Após esta etapa, você obterá um arquivo profile.pb no rundir impresso no código.
Você precisa passar o arquivo profile.pb para o sinalizador --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Para ativar o log no XLA e verificar se o perfil está bom, defina o nível de log para incluir INFO :
export TF_CPP_MIN_LOG_LEVEL=0Execute o fluxo de trabalho real, se você encontrou esses registros no log em execução, significa que o criador de perfil é usado no agendador de ocultação de latência:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax é executado no Jax, você pode encontrar detalhes sobre a execução de jobs do Jax no Cloud TPU aqui, também pode encontrar detalhes sobre a execução de jobs do Jax em um pod do Cloud TPU aqui
Se você encontrar erros de dependência, consulte o arquivo requirements.txt na ramificação correspondente à versão estável que você está instalando. Por exemplo, para a versão estável 0.4.0, use o branch r0.4.0 e consulte o arquivo requirements.txt para obter as versões exatas das dependências usadas para a versão estável.
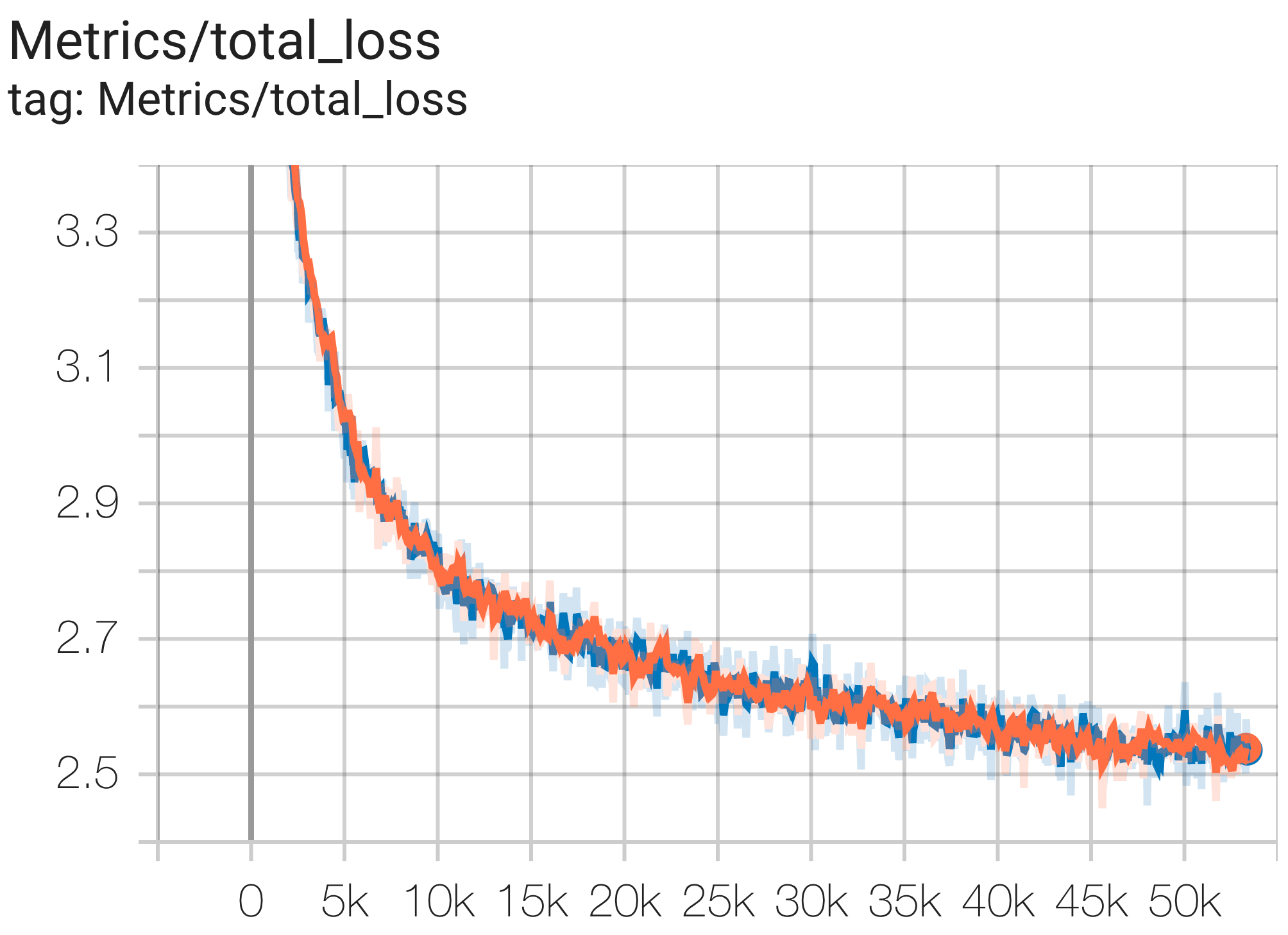
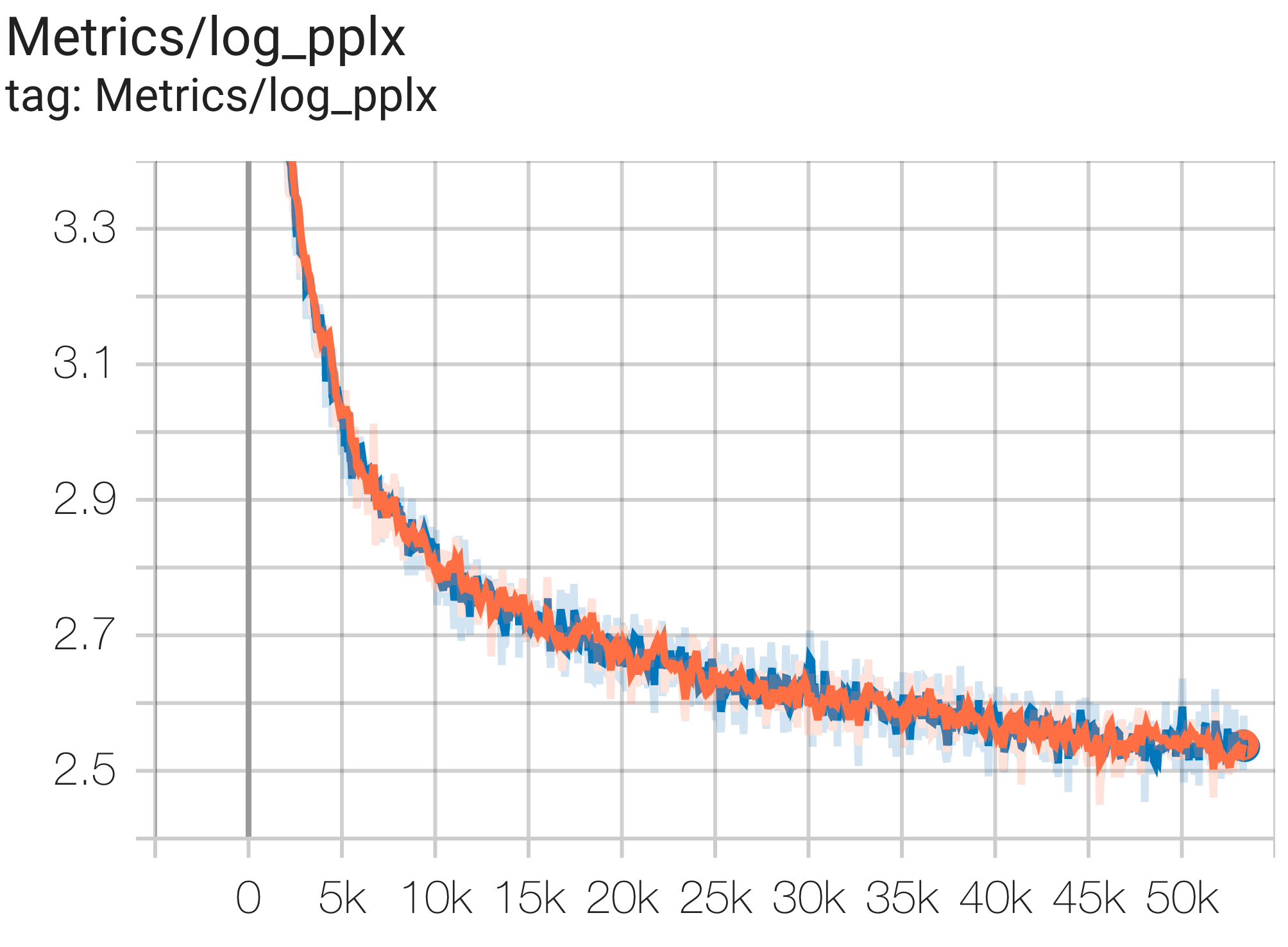
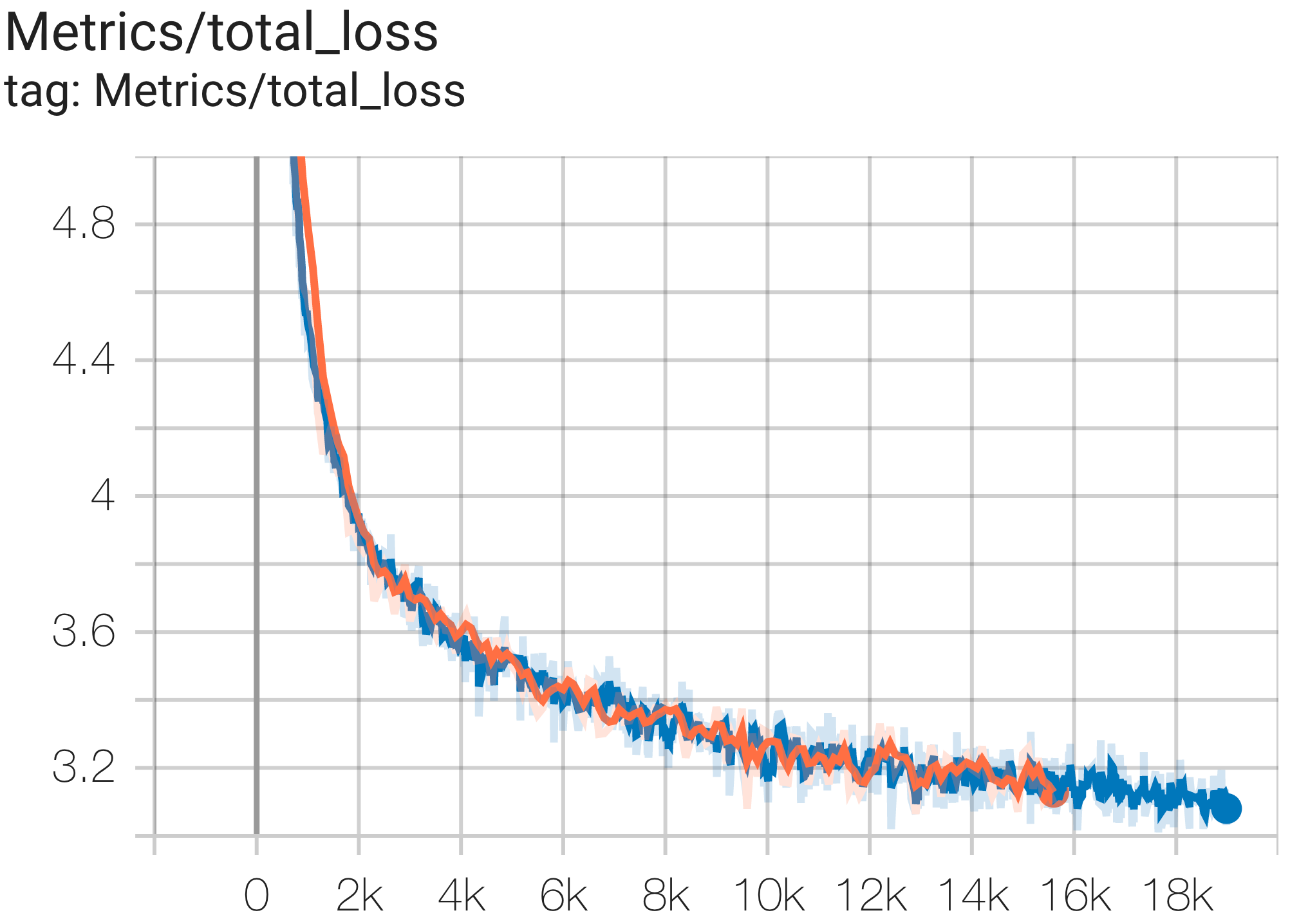
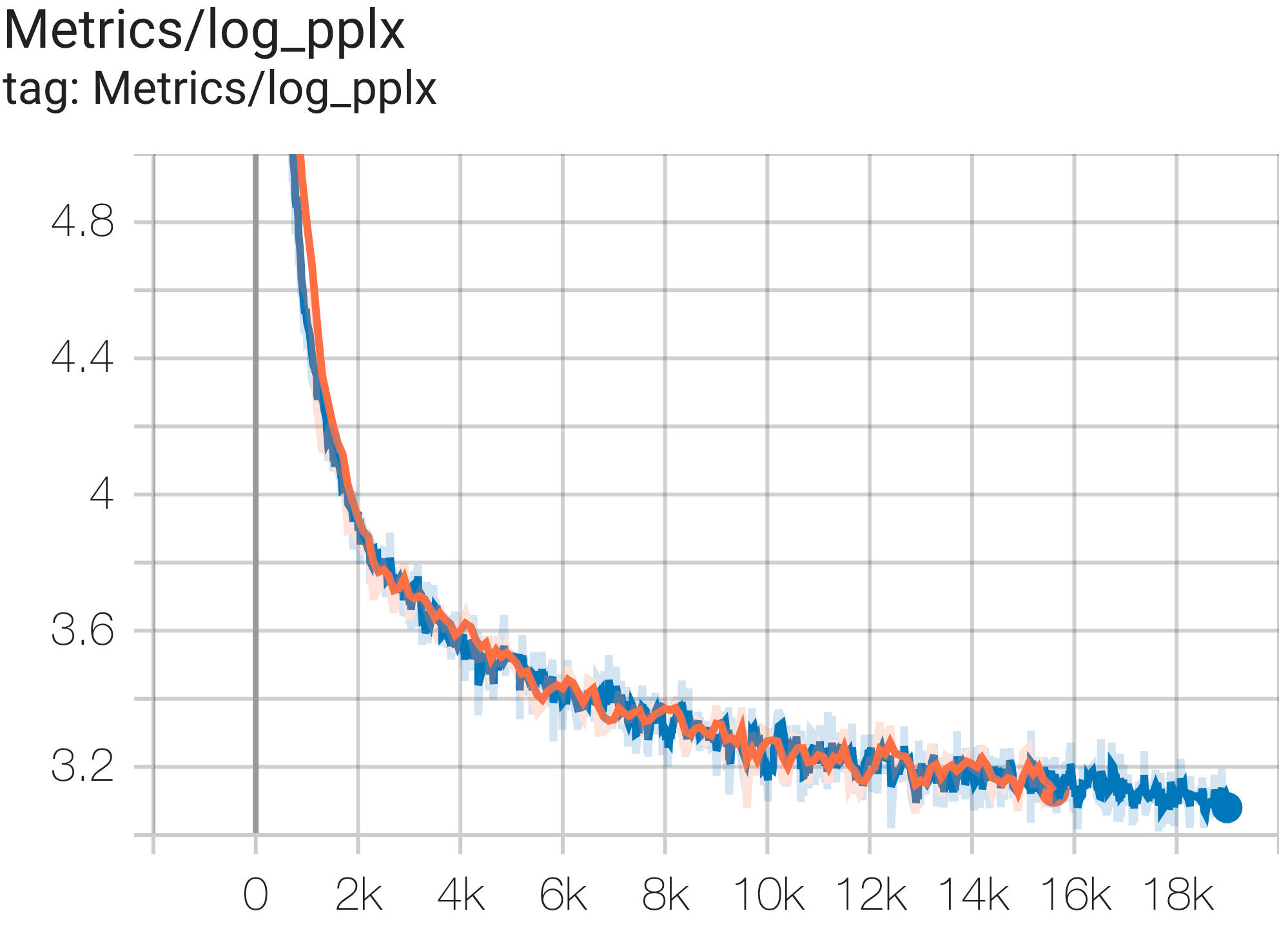
Aqui estão alguns exemplos de execuções de convergência no conjunto de dados c4.
Você pode executar um modelo de parâmetros 1B no conjunto de dados c4 na TPU v4-8 usando a configuração C4Spmd1BAdam4Replicas de c4.py da seguinte forma:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > Você pode observar a curva de perda e o gráfico log perplexity da seguinte forma:
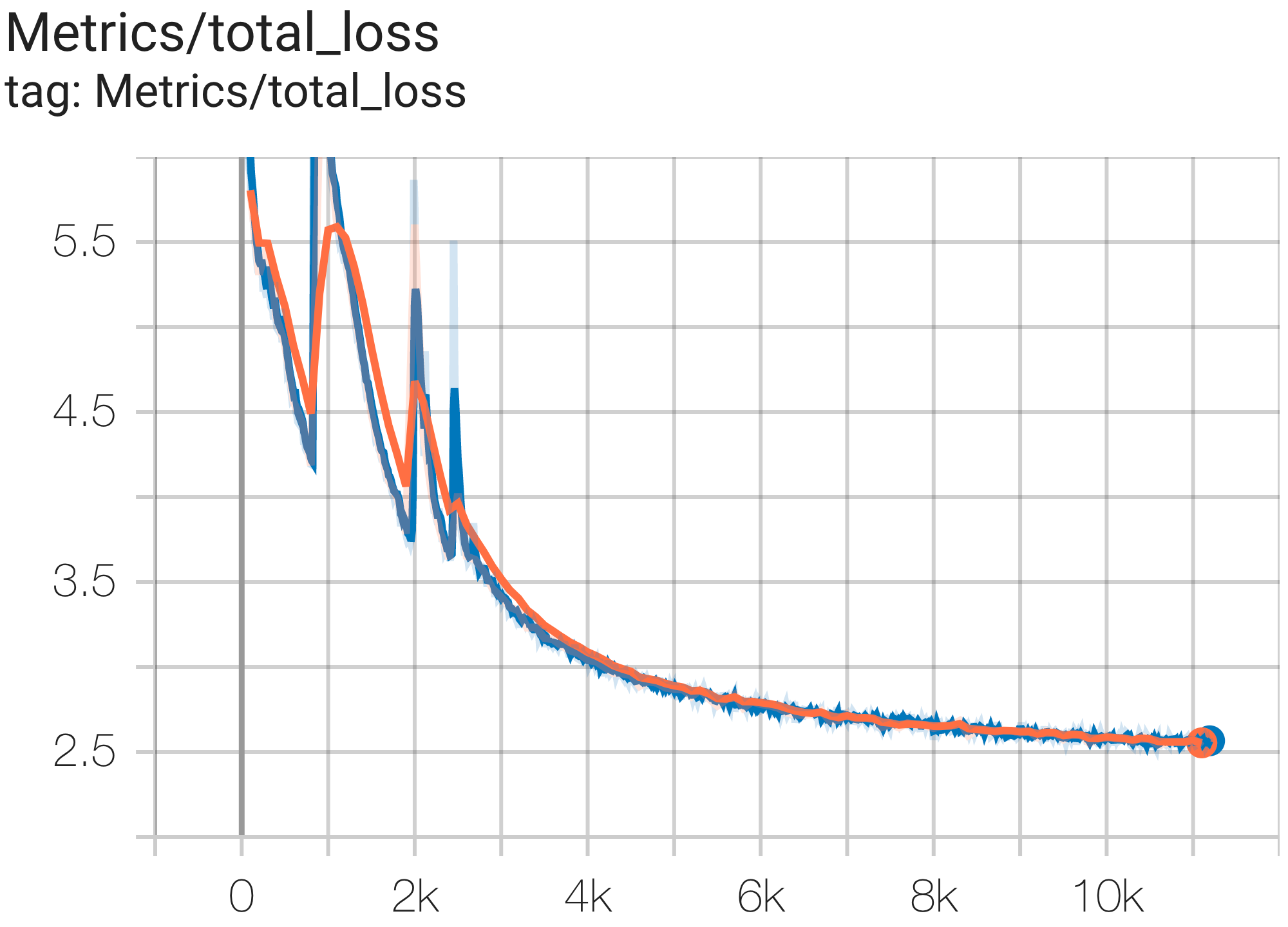
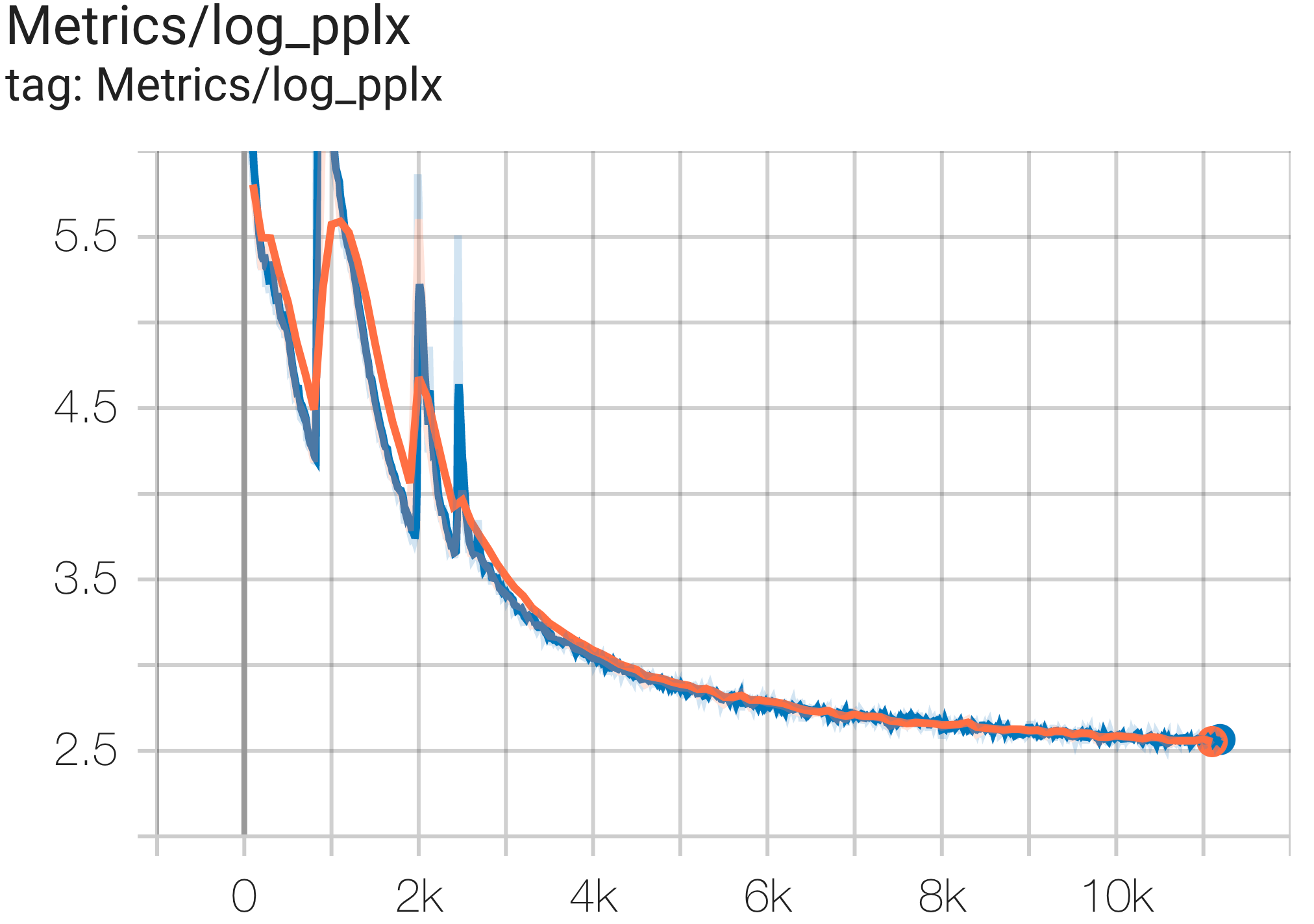
Você pode executar um modelo de parâmetros 16B no conjunto de dados c4 na TPU v4-64 usando a configuração C4Spmd16BAdam32Replicas de c4.py da seguinte forma:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > Você pode observar a curva de perda e o gráfico log perplexity da seguinte forma:
Você pode executar o modelo GPT3-XL no conjunto de dados c4 na TPU v4-128 usando a configuração C4SpmdPipelineGpt3SmallAdam64Replicas de c4.py da seguinte forma:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > Você pode observar a curva de perda e o gráfico log perplexity da seguinte forma:
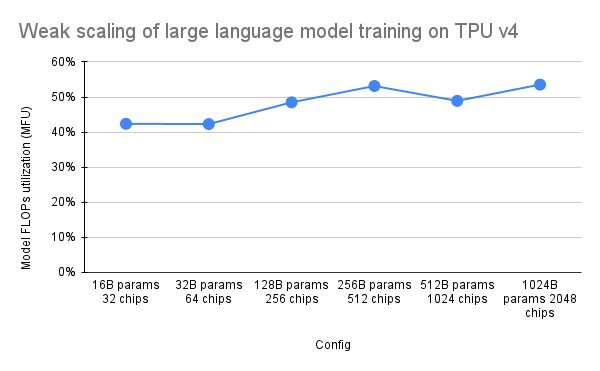
O artigo PaLM introduziu uma métrica de eficiência chamada Model FLOPs Utilization (MFU). Isso é medido como a razão entre o rendimento observado (em, por exemplo, tokens por segundo para um modelo de linguagem) e o rendimento máximo teórico de um sistema que aproveita 100% dos picos de FLOPs. Ele difere de outras formas de medir a utilização da computação porque não inclui FLOPs gastos na rematerialização da ativação durante a passagem para trás, o que significa que a eficiência medida pelo MFU se traduz diretamente na velocidade de treinamento de ponta a ponta.
Para avaliar o MFU de uma classe chave de cargas de trabalho em pods TPU v4 com Pax, realizamos uma campanha de benchmark aprofundada em uma série de configurações de modelo de linguagem Transformer (GPT) somente decodificador que variam em tamanho de bilhões a trilhões de parâmetros no conjunto de dados c4. O gráfico a seguir mostra a eficiência do treinamento usando o padrão de “escala fraca”, onde aumentamos o tamanho do modelo proporcionalmente ao número de chips usados.
As configurações multislice neste repositório referem-se a 1. Configurações de fatia única para sintaxe/arquitetura de modelo e 2. Repositório MaxText para valores de configuração.
Fornecemos exemplos de execução em c4_multislice.py` como ponto de partida para Pax em multislice.
Consulte esta página para obter uma documentação mais completa sobre o uso de recursos em fila para um projeto do Cloud TPU com vários segmentos. Veja a seguir as etapas necessárias para configurar TPUs para executar configurações de exemplo neste repositório.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Digamos que, para executar C4Spmd22BAdam2xv4_128 em 2 fatias da v4-128, você precisaria configurar TPUs da seguinte maneira:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Os comandos de configuração descritos anteriormente precisam ser executados em TODOS os trabalhadores em TODAS as fatias. Você pode 1) fazer ssh em cada trabalhador e em cada fatia individualmente; ou 2) use o loop for com o sinalizador --worker=all como o comando a seguir.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Para executar as configurações multislice, abra o mesmo número de terminais que seu $NODE_COUNT. Para nossos experimentos em 2 fatias ( C4Spmd22BAdam2xv4_128 ), abra dois terminais. Em seguida, execute cada um desses comandos individualmente em cada terminal.
No Terminal 0, execute o comando de treinamento para a fatia 0 da seguinte forma:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "No Terminal 1, execute simultaneamente o comando de treinamento para a fatia 1 da seguinte forma:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Esta tabela cobre detalhes sobre como os nomes das variáveis MaxText foram traduzidos para Pax.
Observe que MaxText possui uma "escala" que é multiplicada por vários parâmetros (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) para valores finais.
Outra coisa a mencionar é que enquanto Pax cobre DCN e ICN MESH_SHAPE como um array, em MaxText existem variáveis separadas de data_parallelism, fsdp_parallelism e tensor_parallelism para DCN e ICI. Como esses valores são definidos como 1 por padrão, apenas as variáveis com valor maior que 1 são registradas nesta tabela de tradução.
Ou seja, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] e DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Pax C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (após a aplicação da escala) | ||
|---|---|---|---|---|
| escala (aplicada às próximas 4 variáveis) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (=base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | tamanho_do_vocabulário | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | tipo d | bfloat16 | |
| USE_REPEATED_LAYER | verdadeiro | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelismo | 2 |
Input é uma instância da classe BaseInput para obter dados no modelo para treinar/avaliar/decodificar.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Ele atua como um iterador: get_next() retorna um NestedMap , onde cada campo é uma matriz numérica com o tamanho do lote como dimensão principal.
Cada entrada é configurada por uma subclasse de BaseInput.HParams . Nesta página, usamos p para denotar uma instância de BaseInput.Params e ele instancia para input .
No Pax, os dados são sempre multihost: cada processo Jax terá uma input separada e independente instanciada. Seus parâmetros terão diferentes p.infeed_host_index , definidos automaticamente pelo Pax.
Portanto, o tamanho do lote local visto em cada host é p.batch_size e o tamanho do lote global é (p.batch_size * p.num_infeed_hosts) . Freqüentemente veremos p.batch_size definido como jax.local_device_count() * PERCORE_BATCH_SIZE .
Devido a esta natureza multihost, input deve ser fragmentada corretamente.
Para treinamento, cada input nunca deve emitir lotes idênticos e, para avaliação em um conjunto de dados finito, cada input deve terminar após o mesmo número de lotes. A melhor solução é fazer com que a implementação de entrada fragmente os dados adequadamente, de modo que cada input em hosts diferentes não se sobreponha. Caso contrário, também é possível usar sementes aleatórias diferentes para evitar lotes duplicados durante o treinamento.
input.reset() nunca é chamado em dados de treinamento, mas pode ser usado para avaliar (ou decodificar) dados.
Para cada execução de avaliação (ou decodificação), Pax busca N lotes de input chamando input.get_next() N vezes. O número de lotes utilizados, N , pode ser um número fixo especificado pelo usuário, via p.eval_loop_num_batches ; ou N pode ser dinâmico ( p.eval_loop_num_batches=None ), ou seja, chamamos input.get_next() até esgotarmos todos os seus dados (aumentando StopIteration ou tf.errors.OutOfRange ).
Se p.reset_for_eval=True , p.eval_loop_num_batches será ignorado e N será determinado dinamicamente como o número de lotes para esgotar os dados. Nesse caso, p.repeat deve ser definido como False, caso contrário levaria a decodificação/avaliação infinita.
Se p.reset_for_eval=False , Pax irá buscar lotes p.eval_loop_num_batches . Isso deve ser definido com p.repeat=True para que os dados não se esgotem prematuramente.
Observe que as entradas do LingvoEvalAdaptor requerem p.reset_for_eval=True .
N : estático | N : dinâmico | |
|---|---|---|
p.reset_for_eval=True | Cada execução de avaliação usa o | Uma época por execução de avaliação. |
: : primeiros N lotes. Não: eval_loop_num_batches : | ||
| : : suportado ainda. : é ignorado. A entrada deve: | ||
| : : : ser finito : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Cada execução de avaliação usa | Não suportado. |
: : não sobreposto N : : | ||
| : : lotes contínuos : : | ||
| : : base, de acordo com : : | ||
: : eval_loop_num_batches : : | ||
| : : . A entrada deve repetir:: | ||
| : : indefinidamente : : | ||
: : ( p.repeat=True ) ou : : | ||
| : : caso contrário pode aumentar : : | ||
| : : exceção : : |
Se estiver executando decode/eval em exatamente uma época (ou seja, quando p.reset_for_eval=True ), a entrada deverá lidar com a fragmentação corretamente, de modo que cada fragmento aumente na mesma etapa após exatamente o mesmo número de lotes serem produzidos. Isso geralmente significa que a entrada deve preencher os dados de avaliação. Isso é feito automaticamente por SeqIOInput e LingvoEvalAdaptor (veja mais abaixo).
Para a maioria das entradas, apenas chamamos get_next() nelas para obter lotes de dados. Um tipo de dados de avaliação é uma exceção a isso, onde "como calcular métricas" também é definido no objeto de entrada.
Isso só é compatível com SeqIOInput que define algum benchmark de avaliação canônico. Especificamente, Pax usa predict_metric_fns e score_metric_fns() definidos na tarefa SeqIO para calcular métricas de avaliação (embora Pax não dependa diretamente do avaliador SeqIO).
Quando um modelo usa múltiplas entradas, seja entre treinamento/avaliação ou diferentes dados de treinamento entre pré-treinamento/ajuste fino, os usuários devem garantir que os tokenizadores usados pelas entradas sejam idênticos, especialmente ao importar diferentes entradas implementadas por outros.
Os usuários podem verificar a sanidade dos tokenizers decodificando alguns ids com input.ids_to_strings() .
É sempre uma boa ideia verificar a integridade dos dados observando alguns lotes. Os usuários podem reproduzir facilmente o parâmetro em um colab e inspecionar os dados:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) Os dados de treinamento normalmente não devem usar uma semente aleatória fixa. Isso ocorre porque se o trabalho de treinamento for interrompido, os dados de treinamento começarão a se repetir. Em particular, para entradas do Lingvo, recomendamos definir p.input.file_random_seed = 0 para dados de treinamento.
Para testar se a fragmentação é tratada corretamente, os usuários podem definir manualmente valores diferentes para p.num_infeed_hosts, p.infeed_host_index e ver se as entradas instanciadas emitem lotes diferentes.
Pax suporta 3 tipos de entradas: SeqIO, Lingvo e custom.
SeqIOInput pode ser usado para importar conjuntos de dados.
As entradas SeqIO lidam com a fragmentação e o preenchimento corretos dos dados de avaliação automaticamente.
LingvoInputAdaptor pode ser usado para importar conjuntos de dados.
A entrada é totalmente delegada à implementação do Lingvo, que pode ou não lidar com a fragmentação automaticamente.
Para implementação de entrada Lingvo baseada em GenericInput usando um packing_factor fixo, recomendamos usar LingvoInputAdaptorNewBatchSize para especificar um tamanho de lote maior para a entrada interna do Lingvo e colocar o tamanho de lote desejado (geralmente muito menor) em p.batch_size .
Para dados de avaliação, recomendamos o uso de LingvoEvalAdaptor para lidar com fragmentação e preenchimento para executar eval em uma época.
Subclasse personalizada de BaseInput . Os usuários implementam sua própria subclasse, normalmente com tf.data ou SeqIO.
Os usuários também podem herdar uma classe de entrada existente para personalizar apenas o pós-processamento de lotes. Por exemplo:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchOs hiperparâmetros são uma parte importante da definição de modelos e da configuração de experimentos.
Para se integrar melhor às ferramentas Python, Pax/Praxis usa um estilo de configuração baseado em classe de dados python para hiperparâmetros.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0Também é possível aninhar dataclasses HParams, no exemplo abaixo, o atributo linear_tpl é um Linear.HParams aninhado.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Uma camada representa uma função arbitrária, possivelmente com parâmetros treináveis. Uma camada pode conter outras camadas como filhas. As camadas são os blocos de construção essenciais dos modelos. As camadas herdam do Flax nn.Module.
Normalmente as camadas definem dois métodos:
Este método cria pesos treináveis e camadas secundárias.
Este método define a função de propagação direta, calculando alguma saída com base nas entradas. Além disso, o fprop pode adicionar resumos ou rastrear perdas auxiliares.
Fiddle é uma biblioteca de configuração Python de código aberto projetada para aplicativos de ML. Pax/Praxis suporta interoperabilidade com Fiddle Config/Partial(s) e alguns recursos avançados, como verificação de erros e parâmetros compartilhados.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Usando o Fiddle, as camadas podem ser configuradas para serem compartilhadas (por exemplo: instanciadas apenas uma vez com pesos treináveis compartilhados).
Um modelo define apenas a rede, normalmente uma coleção de camadas e define interfaces para interagir com o modelo, como decodificação, etc.
Alguns exemplos de modelos básicos incluem:
Uma tarefa contém mais um modelo e aluno/otimizador. A subclasse Task mais simples é uma SingleTask que requer os seguintes Hparams:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| Versão PyPI | Comprometer-se |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


