BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT é um projeto exploratório projetado para construir de forma incremental um modelo de linguagem semelhante ao GPT. O projeto começa com um modelo Bigram simples e gradualmente incorpora conceitos avançados da arquitetura do modelo Transformer.
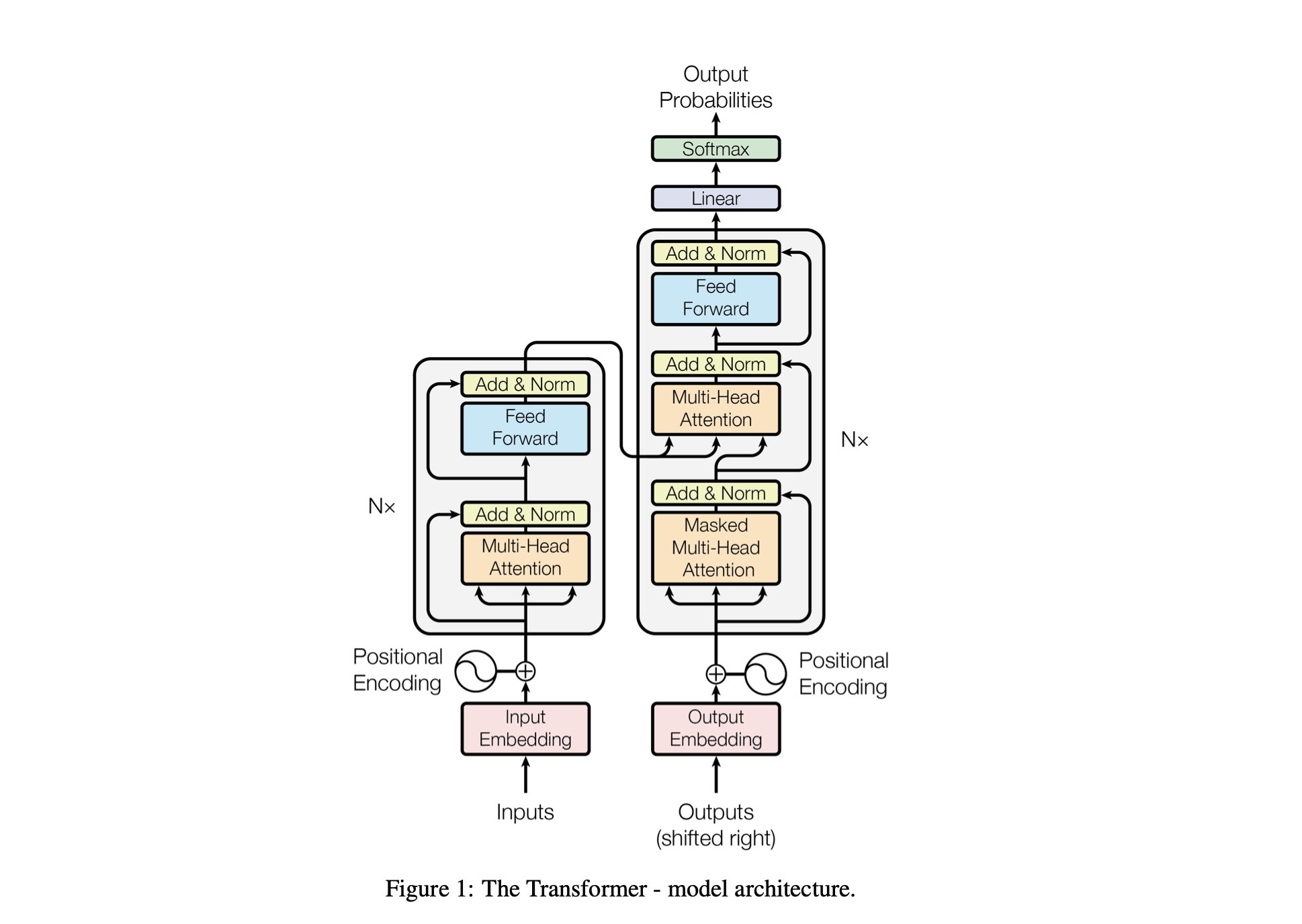
O desempenho do modelo é ajustado usando os seguintes hiperparâmetros:
batch_size : o número de sequências processadas em paralelo durante o treinamentoblock_size : O comprimento das sequências que estão sendo processadas pelo modelod_model : O número de recursos no modelo (o tamanho dos embeddings)d_k : O número de recursos por cabeçalho de atenção.num_iter : o número total de iterações de treinamento que o modelo executaráNx : O número de blocos transformadores, ou camadas, no modelo.eval_interval : O intervalo em que a perda do modelo é calculada e avaliadalr_rate : A taxa de aprendizado para o otimizador Adamdevice : definido automaticamente como 'cuda' se uma GPU compatível estiver disponível, caso contrário, o padrão é 'cpu' .eval_iters : o número de iterações sobre as quais será calculada a média da perda de avaliaçãoh : O número de cabeças de atenção no mecanismo de atenção multi-cabeçasdropout_rate : A taxa de abandono usada durante o treinamento para evitar overfittingEsses hiperparâmetros foram cuidadosamente escolhidos para equilibrar a capacidade do modelo de aprender com os dados sem ajuste excessivo e de gerenciar recursos computacionais de maneira eficaz.
| Hiperparâmetro | Modelo de CPU | Modelo de GPU |
|---|---|---|
device | 'CPU' | 'cuda' se disponível, senão 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10.000 | 10.000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0,2 | 0,2 |
lr_rate | 0,005 (5e-3) | 0,001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int e int_to_chars .encode e vice-versa com a função decode .train_data ) e validação ( valid_data ).get_batch prepara dados em minilotes para treinamento.BigramLM .Minilote é uma técnica de aprendizado de máquina em que os dados de treinamento são divididos em pequenos lotes. Cada minilote é processado separadamente durante o treinamento do modelo. Essa abordagem ajuda em:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Fator | Tamanho de lote pequeno | Tamanho de lote grande |
|---|---|---|
| Ruído gradiente | Maior (mais variação nas atualizações) | Inferior (atualizações mais consistentes) |
| Convergência | Tende a explorar mais soluções, incluindo mínimos mais planos | Muitas vezes converge para mínimos mais nítidos |
| Generalização | Potencialmente melhor (devido aos mínimos mais planos) | Potencialmente pior (devido a mínimos mais nítidos) |
| Viés | Menor (menos probabilidade de se ajustar demais aos padrões de dados de treinamento) | Maior (pode se ajustar demais aos padrões de dados de treinamento) |
| Variância | Maior (devido a mais exploração no espaço de soluções) | Menor (devido à menor exploração no espaço de soluções) |
| Custo Computacional | Maior por época (mais atualizações) | Menor por época (menos atualizações) |
| Uso de memória | Mais baixo | Mais alto |
A função estimate_loss calcula a perda média do modelo em um número especificado de iterações (eval_iters). É utilizado para avaliar o desempenho do modelo sem afetar seus parâmetros. O modelo é configurado para modo de avaliação para desabilitar certas camadas, como dropout, para um cálculo de perda consistente. Após calcular a perda média dos dados de treinamento e validação, o modelo é revertido para o modo de treinamento. Esta função é essencial para monitorar o processo de treinamento e fazer ajustes se necessário.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Codificação posicional : Adicionando informações posicionais ao modelo com positional_encodings_table na classe BigramLM . Adicionamos codificações posicionais às incorporações de nossos personagens, como na arquitetura do transformador.
Aqui configuramos e usamos o otimizador AdamW para treinar um modelo de rede neural em PyTorch. O otimizador Adam é preferido em muitos cenários de aprendizado profundo porque combina as vantagens de duas outras extensões de descida gradiente estocástica: AdaGrad e RMSProp. Adam calcula taxas de aprendizagem adaptativa para cada parâmetro. Além de armazenar uma média em declínio exponencial de gradientes quadrados anteriores, como RMSProp, Adam também mantém uma média em declínio exponencial de gradientes anteriores, semelhante ao momento. Isso permite que o otimizador ajuste a taxa de aprendizado para cada peso da rede neural, o que pode levar a um treinamento mais eficaz em arquiteturas e conjuntos de dados complexos.
AdamW modifica a forma como a redução de peso é incorporada ao processo de otimização, resolvendo um problema com o otimizador Adam original, onde a redução de peso não está bem separada das atualizações de gradiente, levando a uma aplicação de regularização abaixo do ideal. O uso do AdamW às vezes pode resultar em melhor desempenho de treinamento e generalização para dados invisíveis. Escolhemos o AdamW por sua capacidade de lidar com a redução de peso de forma mais eficaz do que o otimizador Adam padrão, levando potencialmente a um melhor treinamento e generalização do modelo.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()A autoatenção é um mecanismo que permite ao modelo pesar a importância de diferentes partes dos dados de entrada de maneira diferente. É um componente chave da arquitetura do Transformer, permitindo que o modelo se concentre em partes relevantes da sequência de entrada para fazer previsões.
Atenção do produto escalar : um mecanismo de atenção simples que calcula uma soma ponderada de valores com base no produto escalar entre consultas e chaves.
Atenção ao produto escalar em escala : uma melhoria em relação à atenção ao produto escalar que reduz os produtos escalares pela dimensionalidade das teclas, evitando que os gradientes se tornem muito pequenos durante o treinamento.
OneHeadSelfAttention : Implementação de um mecanismo de autoatenção de cabeça única que permite ao modelo atender diferentes posições da sequência de entrada. A classe SelfAttention mostra a intuição por trás do mecanismo de atenção e sua versão em escala.
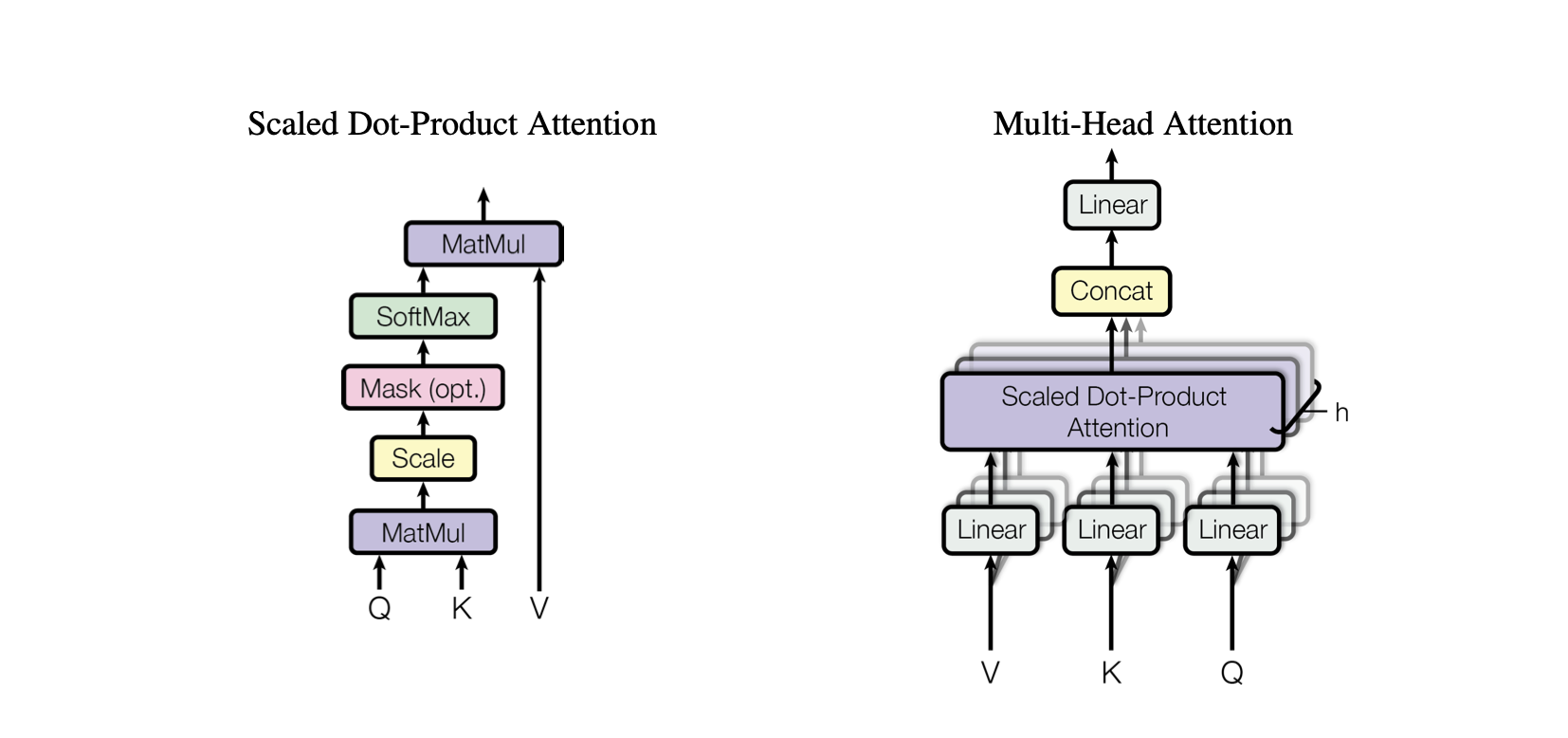
Cada modelo correspondente no projeto Baby GPT se baseia incrementalmente no anterior, começando com a intuição por trás do mecanismo de autoatenção, seguido por implementações práticas de atenções de produto escalar e de produto escalar, e culminando na integração de um modelo único. módulo de autoatenção principal.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur A classe SelfAttention representa um bloco de construção fundamental do modelo Transformer, encapsulando o mecanismo de autoatenção em um único cabeçote. Aqui está uma visão de seus componentes e processos:
Inicialização : O construtor __init__(self, d_k) inicializa as camadas lineares para chaves, consultas e valores, todos com a dimensionalidade d_k . Essas transformações lineares projetam a entrada em diferentes subespaços para cálculos de atenção subsequentes.
Buffers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) registra uma matriz triangular inferior como um buffer persistente que não é considerado um parâmetro do modelo. Esta matriz é utilizada para mascarar o mecanismo de atenção para evitar que posições futuras sejam consideradas em cada etapa do cálculo (útil na autoatenção do decodificador).
Forward Pass : O método forward(self, X) define o cálculo realizado em cada chamada do módulo de autoatenção
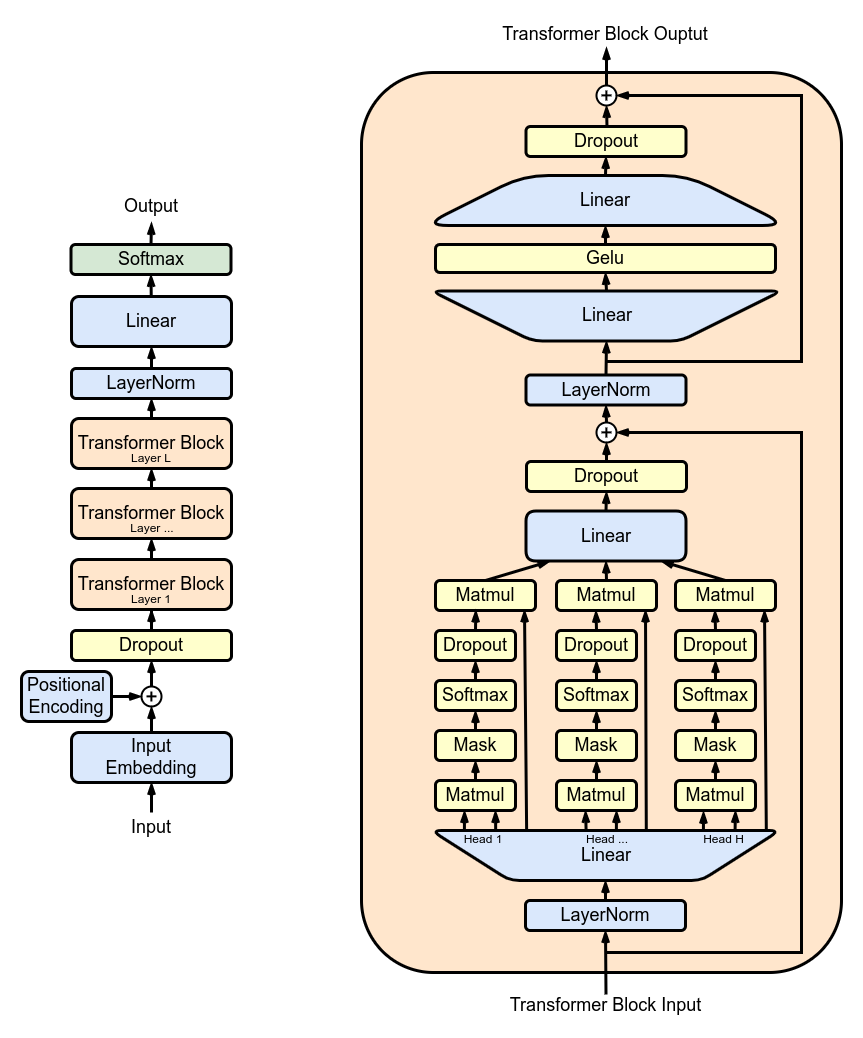
MultiHeadAttention : Combinando saídas de vários cabeçotes SelfAttention na classe MultiHeadAttention . A classe MultiHeadAttention é uma implementação estendida do mecanismo de autoatenção com um cabeçote da etapa anterior, mas agora vários cabeçotes de atenção operam em paralelo, cada um focando em diferentes partes da entrada.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : Implementando rede neural feed-forward com ativação ReLU dentro da classe FeedForward . Para adicionar este feed-forward totalmente conectado ao nosso modelo como no Transformer Model original.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : empilhamento de blocos transformadores usando a classe Block para criar uma arquitetura de rede mais profunda. Profundidade e complexidade: em redes neurais, profundidade se refere ao número de camadas através das quais os dados são processados. Cada camada adicional (ou bloco, no caso dos Transformers) permite que a rede capture características mais complexas e abstratas dos dados de entrada.
Processamento Sequencial: Cada bloco Transformer processa a saída do bloco anterior, construindo gradualmente uma compreensão mais sofisticada da entrada. Esse processamento sequencial permite que a rede desenvolva uma representação profunda e em camadas dos dados. Componentes de um bloco transformador
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : Aprimorando a classe Block para incluir conexões residuais, melhorando a eficiência do aprendizado. As conexões residuais, também conhecidas como conexões de salto, são uma inovação crítica no projeto de redes neurais profundas, especialmente em modelos Transformer. Eles abordam um dos principais desafios no treinamento de redes profundas: o problema do gradiente evanescente.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Adicionando normalização de camada às saídas da camada Transformer.Normalizing com nn.LayerNorm(d_model) na classe Block .
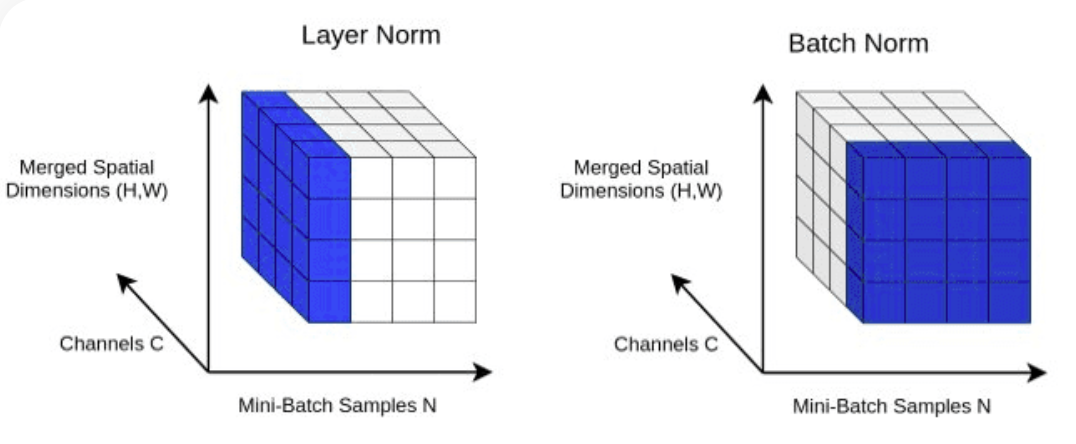
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : Para ser adicionado às camadas SelfAttention e FeedForward como um método de regularização para evitar overfitting. Adicionamos abandono a:
ScaleUp : Aumentando a complexidade do modelo expandindo batch_size , block_size , d_model , d_k e Nx . Você precisará do kit de ferramentas CUDA, bem como de uma máquina com GPU NVIDIA para treinar e testar este modelo maior.
Se você quiser experimentar CUDA para aceleração de GPU, certifique-se de ter a versão apropriada do PyTorch instalada que suporta CUDA.
import torch
torch . cuda . is_available ()Você pode fazer isso especificando a versão CUDA no comando de instalação do PyTorch, como na linha de comando:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

