ke dialogue
1.0.0


Esta é a implementação do artigo:
Aprendendo Bases de Conhecimento com Parâmetros para Sistemas de Diálogo Orientados a Tarefas . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung Descobertas do EMNLP 2020 [PDF]
Se você usar algum código-fonte ou conjunto de dados incluído neste kit de ferramentas em seu trabalho, cite o artigo a seguir. O bibtex está listado abaixo:
@artigo{madotto2020aprendizado,
title={Aprendendo Bases de Conhecimento com Parâmetros para Sistemas de Diálogo Orientados a Tarefas},
autor={Madotto, Andrea e Cahyawijaya, Samuel e Winata, Genta Indra e Xu, Yan e Liu, Zihan e Lin, Zhaojiang e Fung, Pascale},
diário = {pré-impressão arXiv arXiv:2009.13656},
ano={2020}
}
Os sistemas de diálogo orientados a tarefas são modularizados com rastreamento de estado de diálogo (DST) e etapas de gerenciamento separados ou podem ser treinados de ponta a ponta. Em ambos os casos, a base de conhecimento (KB) desempenha um papel essencial no atendimento das solicitações dos usuários. Os sistemas modularizados dependem do DST para interagir com a KB, o que é caro em termos de anotação e tempo de inferência. Os sistemas ponta a ponta usam a KB diretamente como entrada, mas não podem ser dimensionados quando a KB for maior que algumas centenas de entradas. Neste artigo, propomos um método para incorporar a KB, de qualquer tamanho, diretamente nos parâmetros do modelo. O modelo resultante não requer nenhum horário de verão ou respostas de modelo, nem KB como entrada, e pode atualizar dinamicamente seu KB por meio de ajuste fino. Avaliamos nossa solução em cinco conjuntos de dados de diálogo orientados a tarefas com tamanhos de KB pequenos, médios e grandes. Nossos experimentos mostram que os modelos ponta a ponta podem incorporar efetivamente bases de conhecimento em seus parâmetros e alcançar desempenho competitivo em todos os conjuntos de dados avaliados.
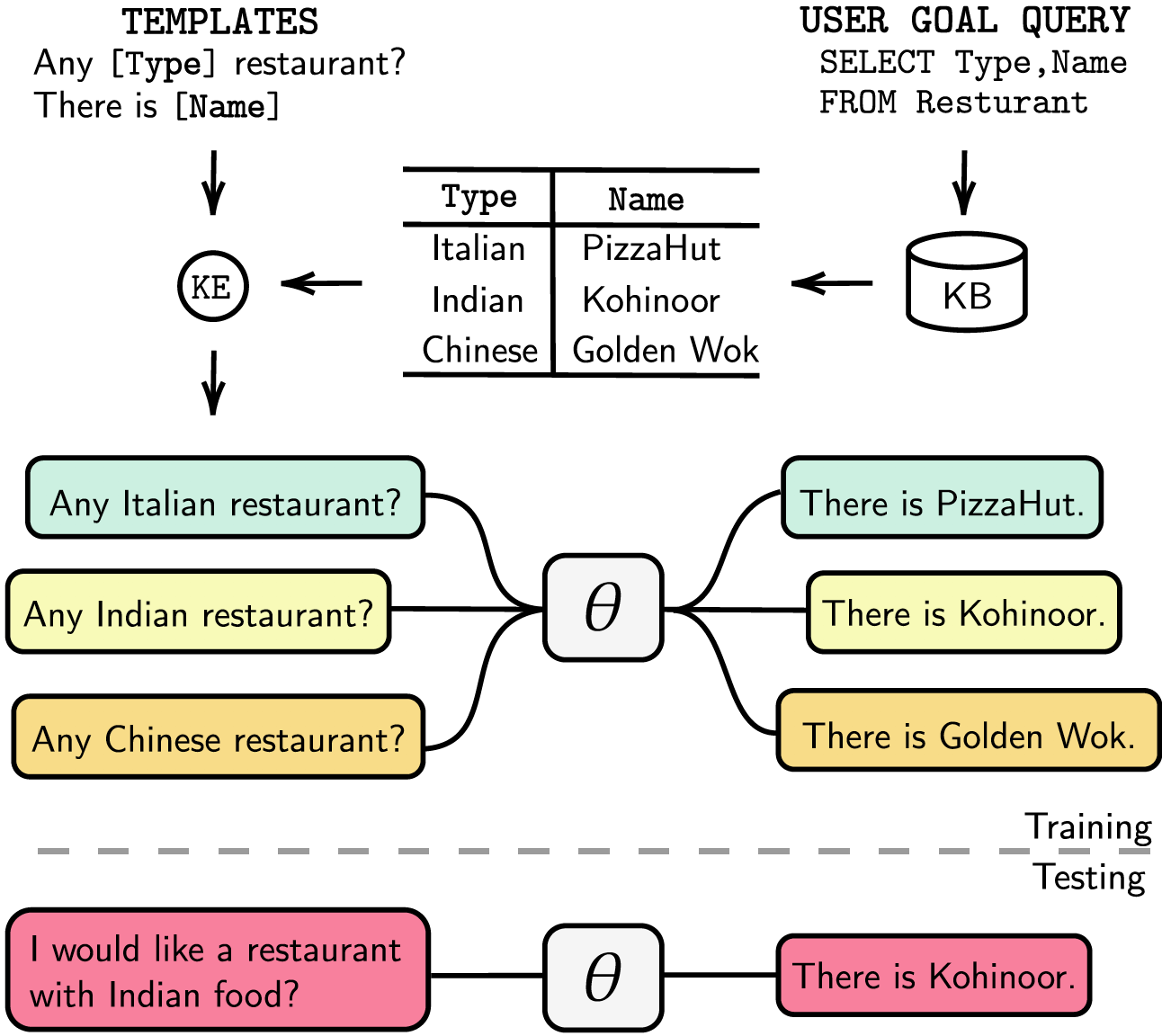
Listamos nossas dependências em requirements.txt , você pode instalar as dependências executando
❱❱❱ pip install -r requirements.txt Além disso, nosso código também inclui suporte fp16 com apex . Você pode encontrar o pacote em https://github.com/NVIDIA/apex.
Conjunto de dados Baixe o conjunto de dados pré-processado e coloque o arquivo zip dentro da pasta ./knowledge_embed/babi5 . Extraia o arquivo zip executando
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipGere os diálogos delexicalizados do conjunto de dados bAbI-5 via
❱❱❱ python3 generate_delexicalization_babi.pyGere os dados lexicalizados do conjunto de dados bAbI-5 via
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Onde o máximo <num_augmented_knowledge> é 558 (recomendado) e <num_augmented_dialogues> é 264, pois corresponde ao número de conhecimento e número de diálogos no conjunto de dados bAbI-5.
Ajuste GPT-2
Fornecemos o ponto de verificação do modelo GPT-2 ajustado no conjunto de treinamento bAbI. Você também pode optar por treinar o modelo sozinho usando o comando a seguir.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Observa que o valor de --kbpercentage é igual a <num_augmented_dialogues> aquele que vem da lexicalização. Este parâmetro é usado para selecionar o arquivo de aumento a ser incorporado ao conjunto de dados do trem.
Você pode avaliar o modelo executando o seguinte script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Pontuando bAbI-5 Para executar o marcador para o modelo de tarefa bAbI-5, você pode executar o comando a seguir. O marcador lerá todo o result.json na pasta runs gerada a partir evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Conjunto de dados
Baixe o conjunto de dados pré-processado e coloque o arquivo zip na pasta ./knowledge_embed/camrest . Descompacte o arquivo zip executando
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipGere os diálogos delexicalizados do conjunto de dados CamRest via
❱❱❱ python3 generate_delexicalization_CAMREST.pyGere os dados lexicalizados do conjunto de dados CamRest via
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Onde o <num_augmented_knowledge> máximo é 201 (recomendado) e <num_augmented_dialogues> é 156 bastante grande, pois corresponde ao número de conhecimento e ao número de diálogos no conjunto de dados CamRest.
Ajuste GPT-2
Fornecemos o ponto de verificação do modelo GPT-2 ajustado no conjunto de treinamento CamRest. Você também pode optar por treinar o modelo sozinho usando o comando a seguir.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Observa que o valor de --kbpercentage é igual a <num_augmented_dialogues> aquele que vem da lexicalização. Este parâmetro é usado para selecionar o arquivo de aumento a ser incorporado ao conjunto de dados do trem.
Você pode avaliar o modelo executando o seguinte script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Pontuação CamRest Para executar o marcador para o modelo de tarefa bAbI 5, você pode executar o seguinte comando. O marcador lerá todo o result.json na pasta runs gerada a partir evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Conjunto de dados
Baixe o conjunto de dados pré-processado e coloque-o na pasta ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipAjuste GPT-2
Fornecemos o ponto de verificação do modelo GPT-2 ajustado no conjunto de treinamento SMD. Baixe o ponto de verificação e coloque-o na pasta ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsVocê também pode optar por treinar o modelo sozinho usando o comando a seguir.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Prepare diálogos incorporados ao conhecimento
Em primeiro lugar, precisamos construir bancos de dados para consultas SQL.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Em seguida, geramos diálogos baseados em modelos pré-desenhados por domínios. O comando a seguir permite gerar diálogos no domínio weather . Substitua weather por navigate ou schedule nos argumentos dialogue_path e domain se desejar gerar diálogos nos outros dois domínios. Você também pode alterar o número de modelos usados no processo de relexicalização alterando o argumento num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testAdapte o modelo GPT-2 ajustado ao conjunto de teste
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""Você também pode acelerar o processo de ajuste executando experimentos paralelamente. Modifique a configuração da GPU em #L14 do código.
❱❱❱ python runner_expe_SMD.py Conjunto de dados
Baixe o conjunto de dados pré-processado e coloque-o na pasta ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipPrepare diálogos incorporados ao conhecimento (você pode pular esta etapa se tiver baixado o arquivo zip acima)
Você pode preparar os conjuntos de dados executando
❱❱❱ bash generate_MWOZ_all_data.shO shell script gera os diálogos delexicalizados do conjunto de dados MWOZ chamando
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyAjuste GPT-2
Fornecemos o ponto de verificação do modelo GPT-2 ajustado no conjunto de treinamento MWOZ. Baixe o ponto de verificação e coloque-o na pasta ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsVocê também pode optar por treinar o modelo sozinho usando o comando a seguir.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Primeiros passos Usamos a edição do servidor da comunidade neo4j e a biblioteca apoc para processar dados gráficos. apoc é usado para paralelizar a consulta em neo4j , para que possamos processar gráficos em grande escala com mais rapidez
Antes de prosseguir para a seção do conjunto de dados, você precisa garantir que possui neo4j (https://neo4j.com/download-center/#community) e apoc (https://neo4j.com/developer/neo4j-apoc/) instalados em seu sistema.
Se você não está familiarizado com as sintaxes CYPHER e apoc , pode seguir o tutorial em https://neo4j.com/developer/cypher/ e https://neo4j.com/blog/intro-user-defined-procedures-apoc/
Conjunto de dados Baixe o conjunto de dados original e coloque o arquivo zip dentro da pasta ./knowledge_embed/opendialkg . Extraia o arquivo zip executando
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipGere os diálogos delexicalizados do conjunto de dados opendialkg via ( AVISO : isso requer cerca de 12 horas para ser executado)
❱❱❱ python3 generate_delexicalization_DIALKG.py Este script produzirá ./opendialkg/dialogkg_train_meta.pt que será usado para gerar o diálogo lexicalizado. Você pode então gerar o diálogo lexicalizado do conjunto de dados opendialkg via
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Este script produzirá amostras de diálogos no máximo amostras batch_size * max_iter , mas em cada lote existe a possibilidade de não haver nenhum candidato válido e resultar em menos amostras. O número de geração é limitado por outro fator chamado stop_count que interromperá a geração se o número de amostras geradas for maior que o stop_count especificado. O arquivo produzirá 4 arquivos: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv e ./opendialkg/generation_iteration_{random_seed}.csv que são usados para verificar a mudança de distribuição do contar no banco de dados; e ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json que contém as amostras geradas.
Notas :
neo4j dentro de generate_delexicalization_DIALKG.py e generate_dialogues_DIALKG.py manualmente.Ajuste GPT-2
Fornecemos o ponto de verificação do modelo GPT-2 ajustado no conjunto de treinamento opendialkg. Você também pode optar por treinar o modelo sozinho usando o comando a seguir.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Observa que o valor de --kbpercentage é igual a <random_seed> aquele que vem da lexicalização. Este parâmetro é usado para selecionar o arquivo de aumento a ser incorporado ao conjunto de dados do trem.
Você pode avaliar o modelo executando o seguinte script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Pontuação OpenDialKG Para executar o marcador para o modelo de tarefa bAbI-5, você pode executar o seguinte comando. O marcador lerá todo o result.json na pasta runs gerada a partir evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Para detalhes sobre os experimentos, hiperparâmetros e resultados da avaliação você pode encontrá-los no artigo principal e materiais complementares do nosso trabalho.


