PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtTodos os modelos serão baixados automaticamente. Você também pode optar por fazer o download manualmente a partir deste URL.
| Modelo | #Params | url | Baixe no OpenXLab |
|---|---|---|---|
| T5 | 4,3B | T5 | T5 |
| VAE | 80 milhões | VAE | VAE |
| PixArt-α-SAM-256 | 0,6B | PixArt-XL-2-SAM-256x256.pth ou versão difusores | 256-SAM |
| PixArt-α-256 | 0,6B | Versão PixArt-XL-2-256x256.pth ou difusores | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6B | Versão PixArt-XL-2-512x512.pth ou difusores | 512 |
| PixArt-α-1024 | 0,6B | PixArt-XL-2-1024-MS.pth ou versão difusores | 1024 |
| PixArt-δ-1024-LCM | 0,6B | versão difusores | |
| Codificador ControlNet-HED | 30 milhões | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
TAMBÉM encontre todos os modelos em OpenXLab_PixArt-alpha
Em primeiro lugar.
Graças ao @kopyl, você pode reproduzir o fluxo de treinamento completo no conjunto de dados Pokémon do HugginFace com notebooks:
Depois, para mais detalhes.
Aqui tomamos a configuração de treinamento do conjunto de dados SAM como exemplo, mas é claro, você também pode preparar seu próprio conjunto de dados seguindo este método.
Você SÓ precisa alterar o arquivo de configuração em config e o dataloader no conjunto de dados.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256A estrutura de diretórios do conjunto de dados SAM é:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Aqui preparamos data_toy para melhor compreensão
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyEntão, aqui está um exemplo de arquivo partição/part0.txt.
Além disso, para treinamento guiado por arquivo json, aqui está um arquivo json de brinquedo para melhor compreensão.
Seguindo as orientações de treinamento Pixart + DreamBooth
Seguindo as orientações de treinamento PixArt + LCM
Seguindo as orientações de treinamento PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 A inferência requer pelo menos 23GB de memória GPU usando este repositório, enquanto 11GB and 8GB usando em? difusores.
Atualmente suporta:
Para começar, primeiro instale as dependências necessárias. Certifique-se de ter baixado os modelos para a pasta output/pretrained_models e, em seguida, execute em sua máquina local:
DEMO_PORT=12345 python app/app.pyComo alternativa, um Dockerfile de amostra é fornecido para criar um contêiner de tempo de execução que inicia o aplicativo Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartOu use docker-compose. Observe que se você deseja alterar o contexto da versão 1024 para 512 ou LCM do aplicativo, basta alterar a variável env APP_CONTEXT no arquivo docker-compose.yml. O padrão é 1024
docker compose build
docker compose up Vamos dar uma olhada em um exemplo simples usando http://your-server-ip:12345 .
Certifique-se de ter as versões atualizadas das seguintes bibliotecas:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4E então:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Confira a documentação para obter mais informações sobre o SA-Solver Sampler.
Essa integração permite executar o pipeline com um tamanho de lote de 4 a 11 GB de GPU VRAM. Confira a documentação para saber mais.
PixArtAlphaPipeline em GPU VRAM com menos de 8 GBO consumo de GPU VRAM abaixo de 8 GB é suportado agora, consulte a documentação para obter mais informações.
Para começar, primeiro instale as dependências necessárias e depois execute em sua máquina local:
# diffusers version
DEMO_PORT=12345 python app/app.py Vamos dar uma olhada em um exemplo simples usando http://your-server-ip:12345 .
Você também pode clicar aqui para fazer um teste gratuito do Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True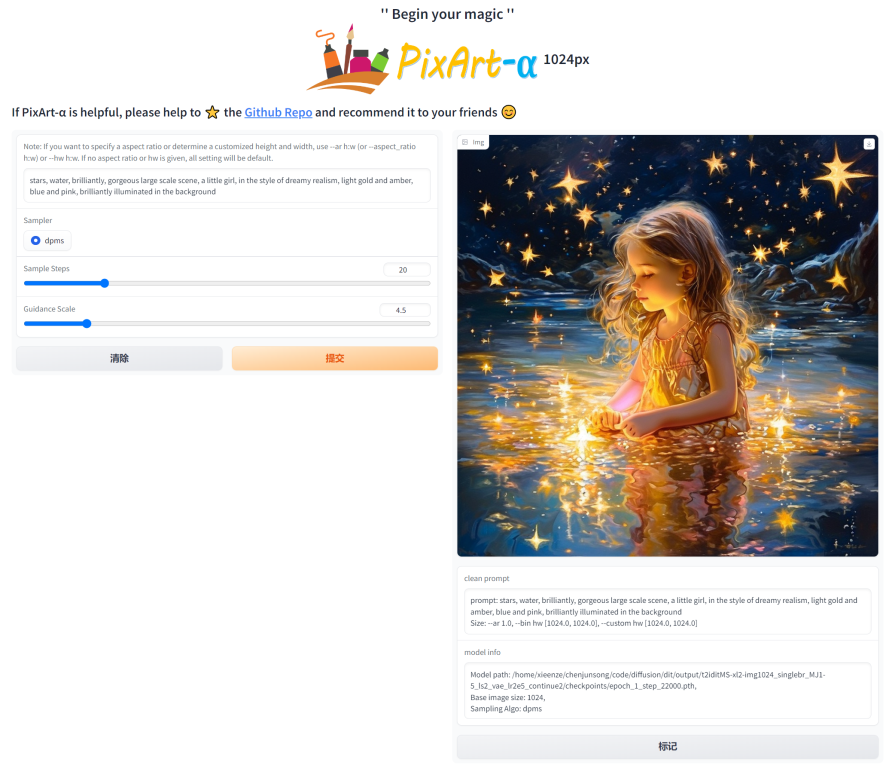
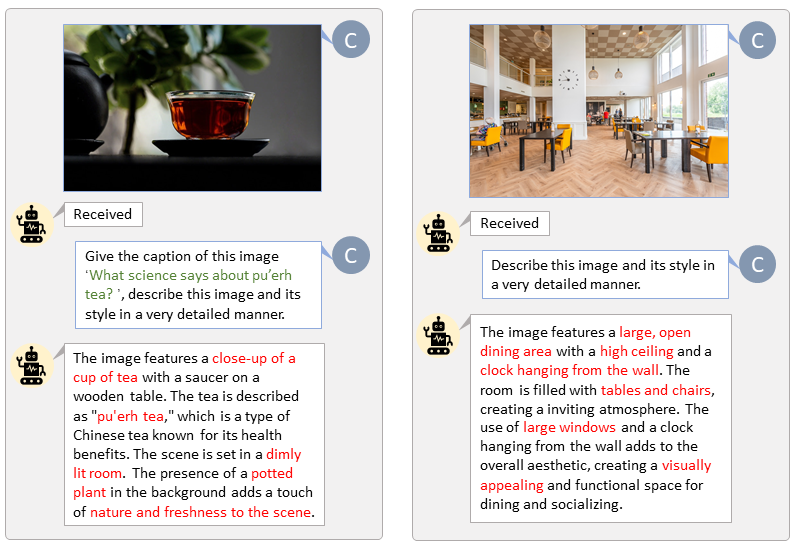
Graças à base de código LLaVA-Lightning-MPT, podemos legendar o conjunto de dados LAION e SAM com o seguinte código de lançamento:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonApresentamos a rotulagem automática com prompts personalizados para LAION (esquerda) e SAM (direita). As palavras destacadas em verde representam a legenda original no LAION, enquanto as marcadas em vermelho indicam as legendas detalhadas rotuladas pelo LLaVA.
Preparar o recurso de texto T5 e o recurso de imagem VAE com antecedência irá acelerar o processo de treinamento e economizar memória da GPU.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Fazemos um vídeo comparando o PixArt com os modelos de texto para imagem mais poderosos atuais.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


