Agent FLAN
1.0.0
[? AbraçandoFace] [? OpenXLab] [? Artigo] [Página do Projeto]
Grandes modelos de linguagem (LLMs) de código aberto alcançaram grande sucesso em várias tarefas de PNL, no entanto, ainda são muito inferiores aos modelos baseados em API quando atuam como agentes. Como integrar a capacidade do agente nos LLMs gerais torna-se um problema crucial e urgente. Este artigo primeiro fornece três observações principais: (1) o atual corpus de treinamento de agentes está emaranhado tanto com o acompanhamento de formatos quanto com o raciocínio do agente, que muda significativamente da distribuição de seus dados de pré-treinamento; (2) os LLMs apresentam diferentes velocidades de aprendizagem nas capacidades exigidas pelas tarefas do agente; e (3) as abordagens atuais têm efeitos colaterais ao melhorar as habilidades dos agentes através da introdução de alucinações. Com base nas descobertas acima, propomos o Agent-FLAN para ajustar efetivamente os modelos de LANguage para Agentes. Por meio da decomposição cuidadosa e do redesenho do corpus de treinamento, o Agent-FLAN permite que o Llama2-7B supere os melhores trabalhos anteriores em 3,5% em vários conjuntos de dados de avaliação de agentes. Com amostras negativas construídas de forma abrangente, o Agent-FLAN alivia muito os problemas de alucinação com base em nosso benchmark de avaliação estabelecido. Além disso, melhora consistentemente a capacidade do agente dos LLMs ao dimensionar tamanhos de modelos, ao mesmo tempo que melhora ligeiramente a capacidade geral dos LLMs.
As séries Agent-FLAN são ajustadas no AgentInstruct e Toolbench aplicando o pipeline de geração de dados proposto no artigo Agent-FLAN, que possui fortes habilidades em várias tarefas do agente e utilização de ferramentas ~
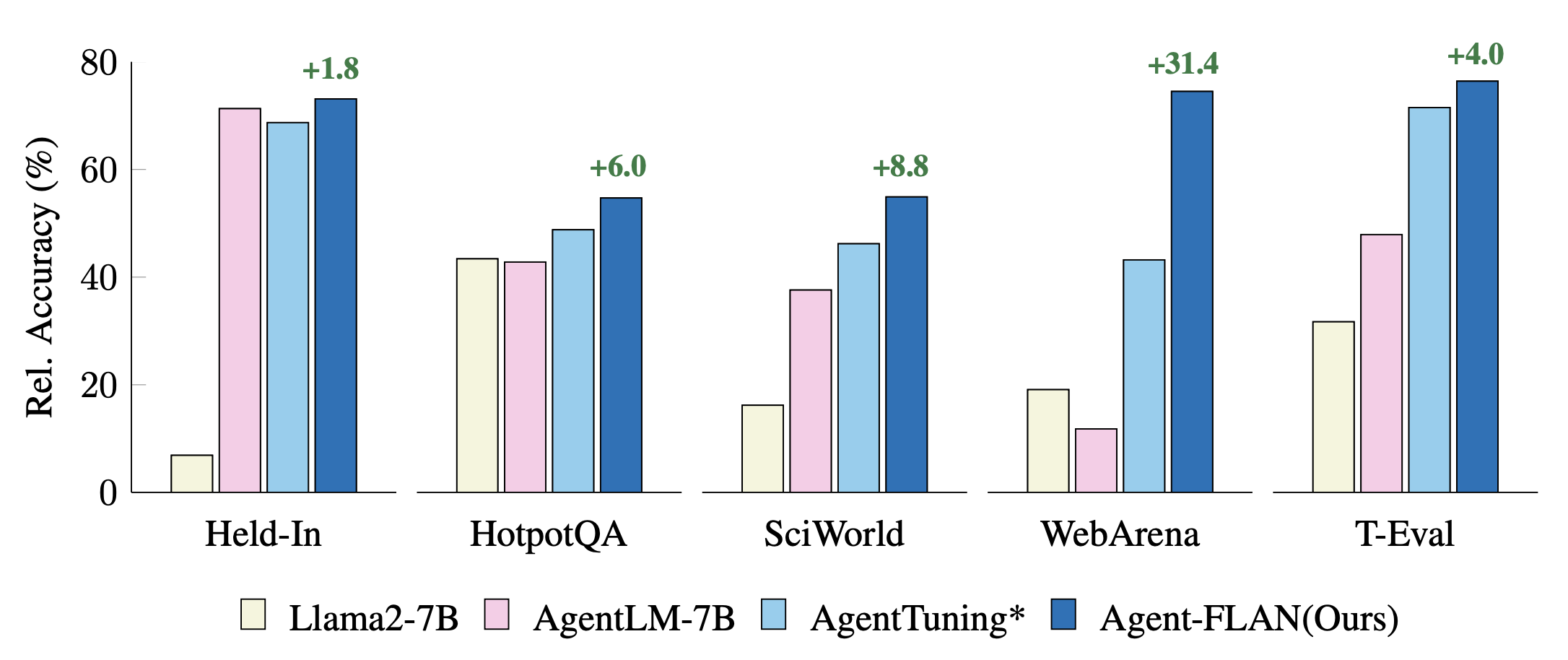
Comparação de abordagens recentes de ajuste de agentes em tarefas Held-In e Held-Out. Os desempenhos são normalizados com resultados GPT-4 para melhor visualização. * denota nossa reimplementação para uma comparação justa.
Agent-FLAN é produzido por treinamento misto nos conjuntos de dados AgentInstruct, ToolBench e ShareGPT da série Llama2-chat.
Os modelos seguem o formato de conversação do Llama-2-chat, com o protocolo modelo como:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),O modelo 7B está disponível no hub de modelos Huggingface e OpenXLab.
| Modelo | Repositório Huggingface | Repositório OpenXLab |
|---|---|---|
| Agente-FLAN-7B | Link do modelo | Link do modelo |
O conjunto de dados Agent-FLAN também está disponível no hub do conjunto de dados Huggingface.
| Conjunto de dados | Repositório Huggingface |
|---|---|
| Agente-FLAN | Link do conjunto de dados |
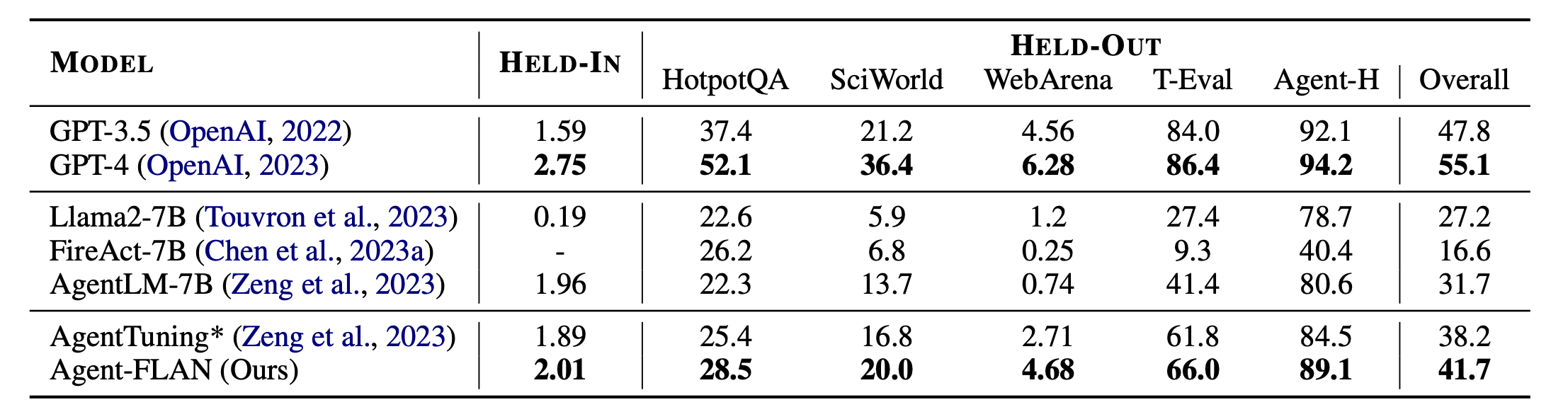
Principais resultados do Agente-FLAN. O Agent-FLAN supera significativamente as abordagens anteriores de ajuste de agente por uma grande margem em tarefas retidas e suspensas. * denota nossa reimplementação com a mesma quantidade de dados de treinamento para uma comparação justa. Como o FireAct não treina no conjunto de dados AgentInstruct, omitimos seu desempenho no conjunto HELD-IN. Ousado: o melhor em modelos baseados em API e de código aberto.
Agent-FLAN é construído com Lagent e T-Eval. Obrigado pelo seu trabalho incrível!
Se você achar este projeto útil em sua pesquisa, considere citar:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
Este projeto é lançado sob a licença Apache 2.0.


