REaLTabFormer
v0.2.1
O REaLTabFormer (Realistic Relational and Tabular Data using Transformers) oferece uma estrutura unificada para sintetizar dados tabulares de diferentes tipos. Um modelo sequência a sequência (Seq2Seq) é usado para gerar conjuntos de dados relacionais sintéticos. O modelo REaLTabFormer para dados tabulares não relacionais usa GPT-2 e pode ser usado imediatamente para modelar quaisquer dados tabulares com observações independentes.
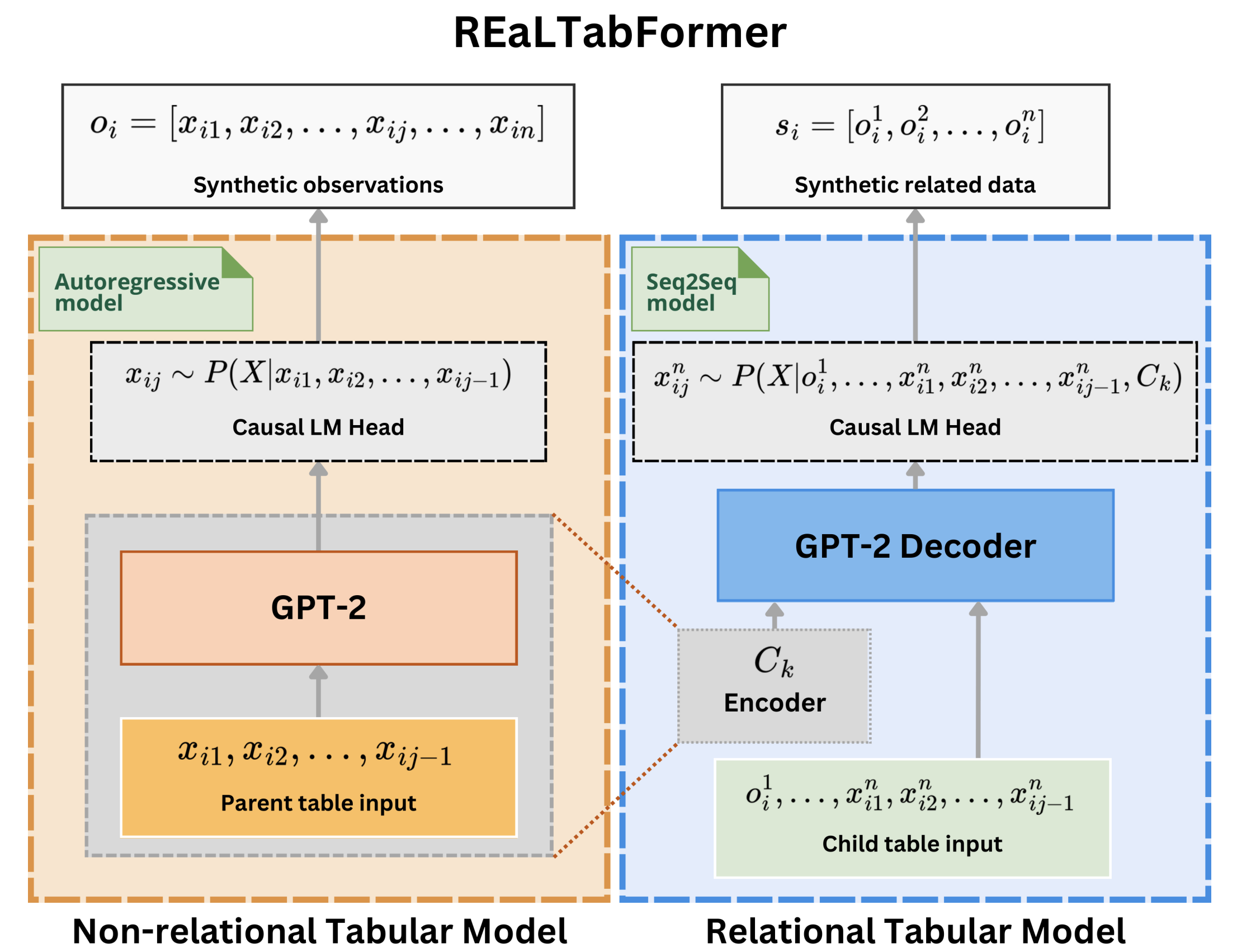
REaLTabFormer: Gerando dados relacionais e tabulares realistas usando transformadores
Artigo sobre ArXiv
REaLTabFormer está disponível no PyPi e pode ser facilmente instalado com pip (versão Python >= 3.7):
pip instalar realtabformer
Mostramos exemplos de uso do REaLTabFormer para modelagem e geração de dados sintéticos a partir de um modelo treinado.
Observação
O modelo implementa um critério de parada ideal baseado na distribuição de dados sintéticos ao treinar um modelo tabular não relacional. O modelo interromperá o treinamento quando a distribuição dos dados sintéticos estiver próxima da distribuição real dos dados.
Certifique-se de definir o parâmetro epochs como um número grande para permitir que o modelo se ajuste melhor aos dados. O modelo interromperá o treinamento quando o critério de parada ideal for atendido.
# pip install realtabformerimport pandas as pdfrom realtabformer import REaLTabFormerdf = pd.read_csv("foo.csv")# NOTA: Remova quaisquer identificadores exclusivos nos# dados que você não deseja que sejam modelados.# Tabela não relacional ou pai. rtf_model = REaLTabFormer(model_type="tabular",gradient_accumulation_steps=4,logging_steps=100)# Ajuste o modelo no conjunto de dados.# Parâmetros adicionais podem ser# passados para o método `.fit`.rtf_model.fit(df)# Salve o modelo em o diretório atual.# Um novo diretório `rtf_model/` será criado.# Nele também será criado um diretório com o id do experimento do modelo# idXXXX`# onde os artefatos do modelo serão armazenados.rtf_model.save("rtf_model/")# Gere dados sintéticos com o mesmo# número de observações que o conjunto de dados real.samples = rtf_model.sample(n_samples=len(df))# Load o modelo salvo. O diretório para o # experimento deve ser fornecido.rtf_model2 = REaLTabFormer.load_from_dir(path="rtf_model/idXXXX") # pip install realtabformerimport osimport pandas as pdfrom pathlib import Pathfrom realtabformer import REaLTabFormerparent_df = pd.read_csv("foo.csv")child_df = pd.read_csv("bar.csv")join_on = "unique_id"# Certifique-se de que as colunas-chave em tanto a tabela # pai quanto a tabela filho têm o mesmo nome.assert ((join_on in parent_df.columns) and(join_on in child_df.columns))# Tabela não relacional ou pai. Não inclua o# unique_id field.parent_model = REaLTabFormer(model_type="tabular")parent_model.fit(parent_df.drop(join_on, axis=1))pdir = Path("rtf_parent/")parent_model.save(pdir)# # Obtenha o modelo pai salvo mais recentemente,# # ou especifique algum outro modelo salvo.# parent_model_path = pdir / "idXXX"parent_model_path = classificado([p para p em pdir.glob("id*") se p.is_dir()],key=os.path.getmtime)[-1]child_model = REaLTabFormer(model_type="relational",parent_realtabformer_path=parent_model_path,output_max_length=None,train_size=0.8)child_model.fit(df=child_df,in_df=parent_df,join_on=join_on)# Gerar amostras pai.parent_samples = parent_model.sample(len(parend_df ))# Crie os IDs exclusivos com base no index.parent_samples.index.name = join_onparent_samples = parent_samples.reset_index()# Gere as observações relacionais.child_samples = child_model.sample(input_unique_ids=parent_samples[join_on],input_df=parent_samples.drop(join_on, axis=1),gen_batch =64) A estrutura REaLTabFormer fornece uma interface para construir facilmente validadores de observação para filtrar amostras sintéticas inválidas. Mostramos um exemplo de uso do GeoValidator abaixo. O gráfico à esquerda mostra a distribuição da latitude e longitude geradas sem validação. O gráfico à direita mostra as amostras sintéticas com observações que foram validadas usando o GeoValidator com a fronteira da Califórnia. Ainda assim, mesmo quando não treinamos o modelo de maneira ideal para gerar isso, as amostras inválidas (fora dos limites) são escassas nos dados gerados sem validador.
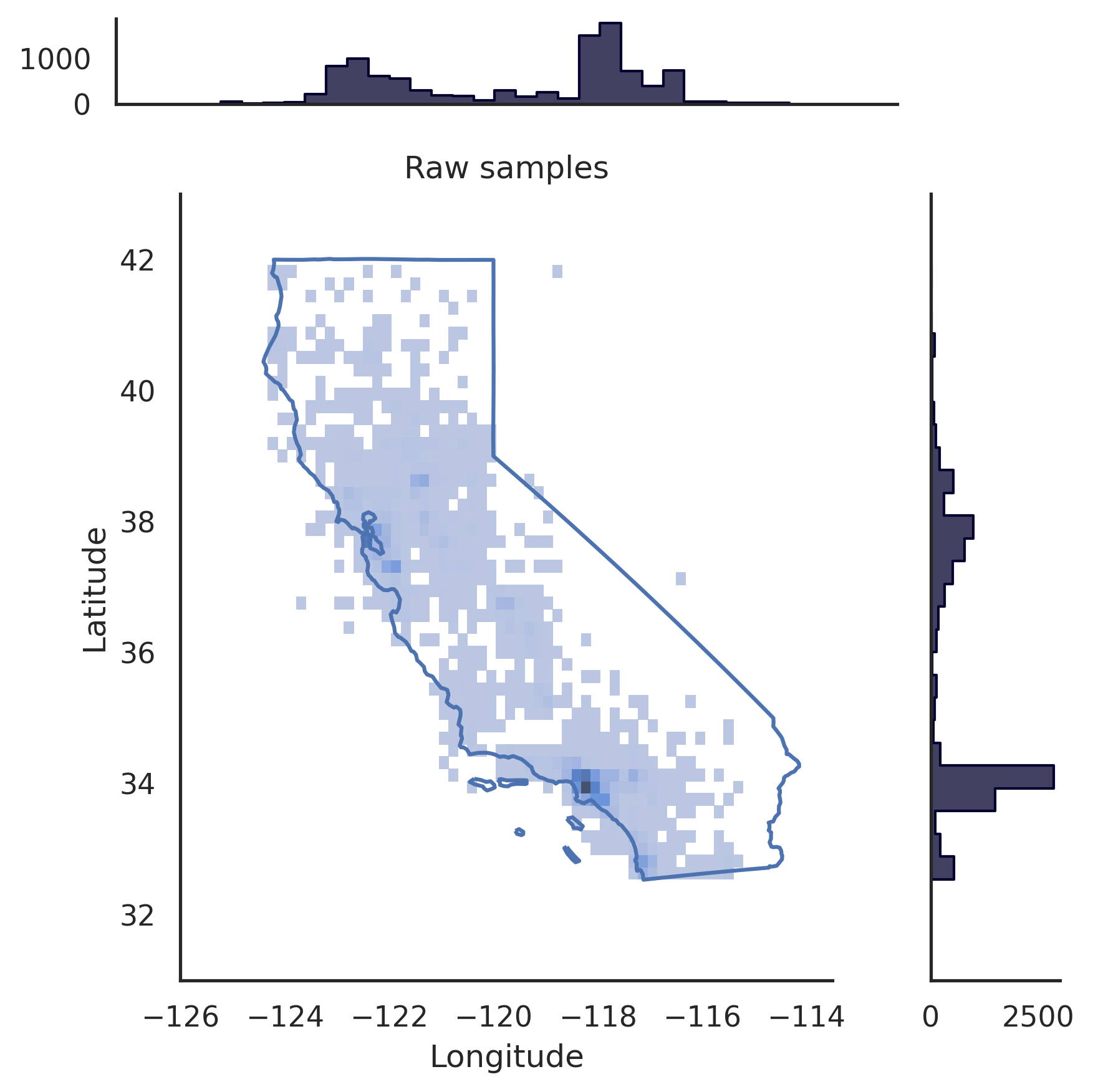
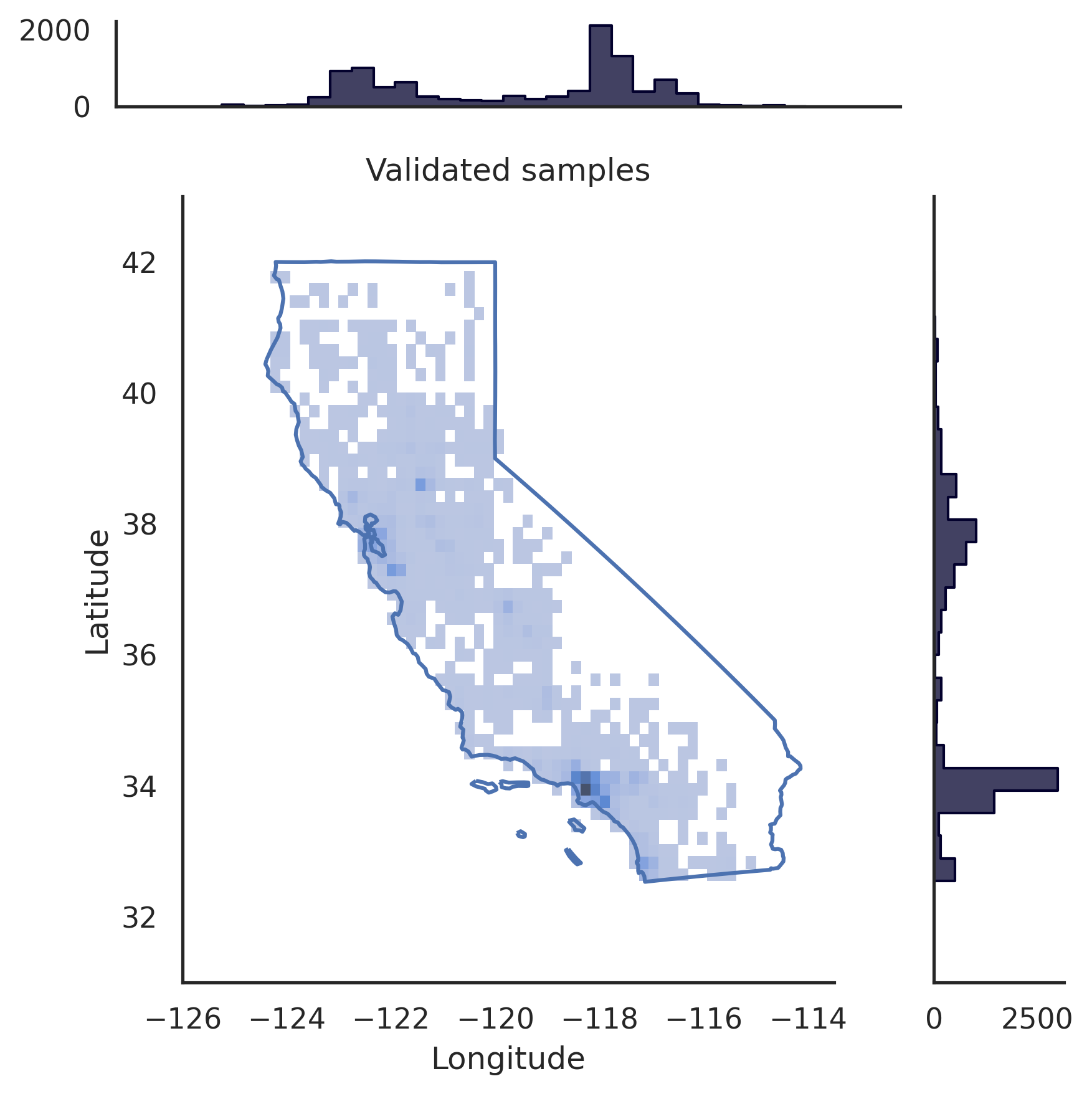
# !pip install geopandas &> /dev/null# !pip install realtabformer &> /dev/null# !git clone https://github.com/joncutrer/geopandas-tutorial.git &> /dev/nullimport geopandasimport seaborn as snsimport matplotlib.pyplot como pltfrom realtabformer importar REaLTabFormerfrom realtabformer importar rtf_validators as rtf_valfrom shapely.geometry importar Polígono, LineString, Ponto, MultiPolygonfrom sklearn.datasets importar fetch_california_housingdef plot_sf (dados, amostras, título = Nenhum): xlims = (-126, -113,5) ylims = (31, 43) bins = (50) , 50)dd = amostras.copy()pp = dd.loc[dd["Longitude"].between(dados["Longitude"].min(), dados["Longitude"].max()) &dd["Latitude"].between(dados["Latitude"] .min(), dados["Latitude"].max())
]g = sns.JointGrid(data=pp, x="Longitude", y="Latitude", marginal_ticks=True)g.plot_joint(sns.histplot,bins=bins,
)states[states['NAME'] == 'Califórnia'].boundary.plot(ax=g.ax_joint)g.ax_joint.set_xlim(*xlims)g.ax_joint.set_ylim(*ylims)g.plot_marginals(sns. histplot, element="step", color="#03012d")se title:g.ax_joint.set_title(title)plt.tight_layout()# Obter arquivos geográficosstates = geopandas.read_file('geopandas-tutorial/data/usa-states-census-2014.shp')states = states.to_crs("EPSG :4326") # Projeção GPS# Obtenha o conjunto de dados habitacionais da Califórniadata = fetch_california_housing(as_frame=True).frame# Criamos um modelo com épocas pequenas para a demonstração, o padrão é 200.rtf_model = REaLTabFormer(model_type="tabular",batch_size=64,epochs=10,gradient_accumulation_steps=4,logging_steps=100) # Ajuste o modelo especificado. Também reduzimos o num_bootstrap, o padrão é 500.rtf_model.fit(data, num_bootstrap=10)# Salve o modelo treinadortf_model.save("rtf_model/")# Amostra de dados brutos sem validatorsamples_raw = rtf_model.sample(n_samples=10240, gen_batch= 512)# Dados de amostra com o validador geográficoobs_validator = rtf_val.ObservationValidator()obs_validator.add_validator("geo_validator",rtf_val.GeoValidator(MultiPolygon(states[states['NAME'] == 'Califórnia'].geometry[0])),
("Longitude", "Latitude")
)amostras_validadas = rtf_model.sample(n_samples=10240, gen_batch=512,validador=obs_validator,
)# Visualize as amostrasplot_sf(data, samples_raw, title="Amostras brutas")plot_sf(data, samples_validated, title="Amostras validadas")Por favor, cite nosso trabalho se você usa o REaLTabFormer em seus projetos ou pesquisas.
@artigo{solatorio2023realtabformer, title={REaLTabFormer: Gerando dados relacionais e tabulares realistas usando transformadores}, autor={Solatorio, Aivin V. e Dupriez, Olivier}, diário={arXiv preprint arXiv:2302.02041}, ano={2023}}Agradecemos ao Centro Conjunto de Dados sobre Deslocamento Forçado (JDC) do Banco Mundial e do ACNUR por financiar o projeto "Aprimorando o Acesso Responsável a Microdados para Melhorar Políticas e Resposta em Situações de Deslocamento Forçado" (KP-P174174-GINP-TF0B5124). Uma parte do fundo foi destinada a apoiar o desenvolvimento do quadro REaLTabFormer que foi utilizado para gerar a população sintética para investigação sobre o risco de divulgação e o efeito mosaico.
Também enviamos ? para o HuggingFace? por todo o software de código aberto que eles lançam. E a todos os projetos de código aberto, obrigado!


