safe rlhf
1.0.0
Beaver é uma estrutura RLHF de código aberto altamente modular desenvolvida pela equipe PKU-Alignment da Universidade de Pequim. Seu objetivo é fornecer dados de treinamento e um pipeline de código reproduzível para pesquisa de alinhamento, especialmente pesquisa LLM de alinhamento restrito por meio de métodos RLHF seguros.
Os principais recursos do Beaver são:
2024/06/13 : Temos o prazer de anunciar o código aberto de nosso conjunto de dados PKU-SafeRLHF versão 1.0. Esta versão avança em relação à versão beta inicial ao incorporar anotações conjuntas entre humanos e IA, expandindo o escopo das categorias de danos e introduzindo rótulos detalhados de níveis de gravidade. Para mais detalhes e acesso, visite nossa página de conjunto de dados em? Abraçando o Rosto: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : Nosso método Safe RLHF foi aceito pelo ICLR 2024 Spotlight.2023/10/19 : Lançamos nosso artigo Safe RLHF no arXiv, detalhando nosso novo algoritmo de alinhamento seguro e sua implementação.2023/07/10 : Temos o prazer de anunciar o código aberto dos modelos Beaver-7B v1/v2/v3 como o primeiro marco da série de treinamento Safe RLHF, complementado pelos correspondentes Reward Models v1/v2/v3/unified e modelos de custo v1/v2/v3/pontos de verificação unificados ativados? Abraçando o rosto.2023/07/10 : Estendemos o conjunto de dados de preferências de segurança de código aberto, PKU-Alignment/PKU-SafeRLHF , que agora contém mais de 300 mil exemplos. (Veja também a seção PKU-SafeRLHF-Dataset)2023/07/05 : Melhoramos nosso suporte para modelos de pré-treinamento chineses e incorporamos conjuntos de dados chineses de código aberto adicionais. (Consulte também as seções Suporte chinês (中文支持) e Conjuntos de dados personalizados (自定义数据集))2023/05/15 : Primeiro lançamento do pipeline Safe RLHF, resultados da avaliação e código de treinamento.Aprendizagem por Reforço com Feedback Humano: maximização da recompensa por meio de aprendizagem preferencial
Aprendizagem por Reforço Seguro com Feedback Humano: maximização de recompensa restrita por meio de aprendizagem preferencial
onde
O objetivo final é encontrar um modelo
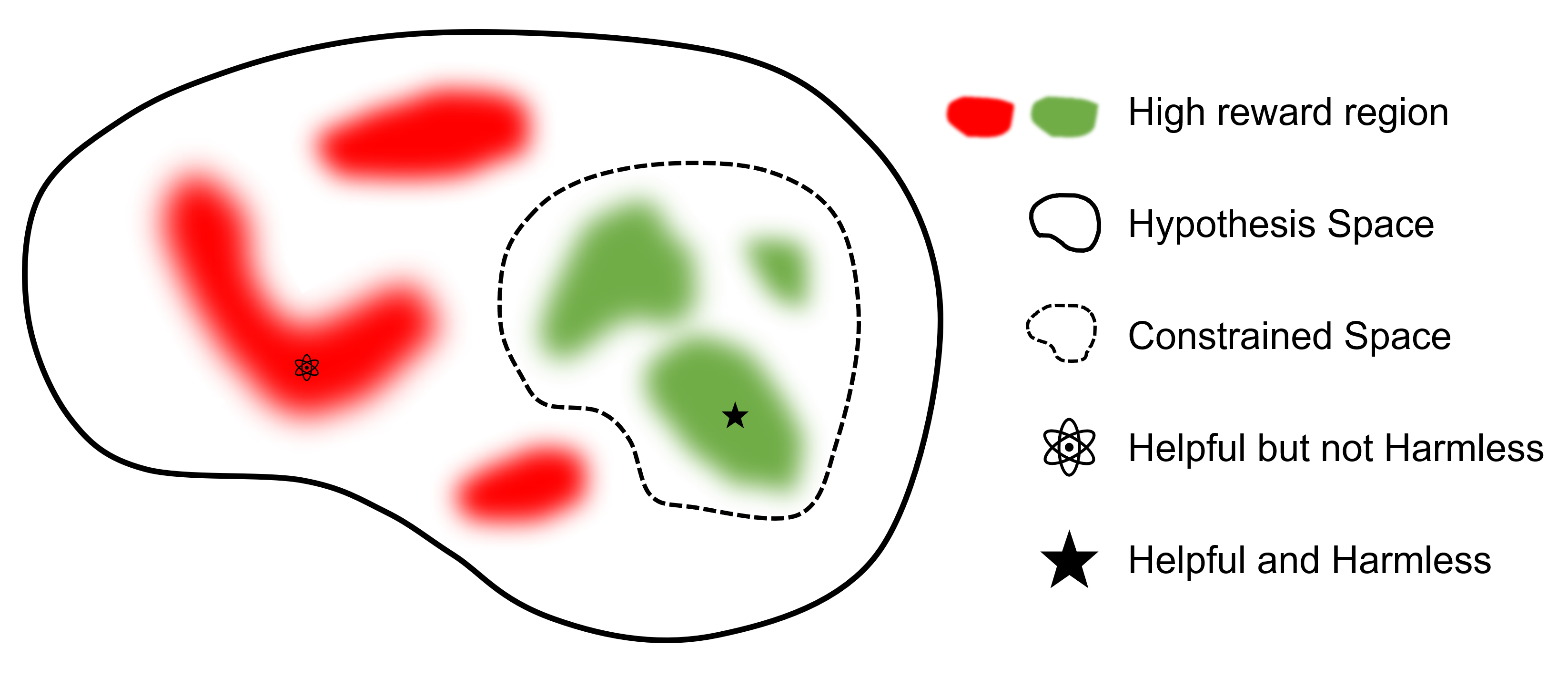
Em comparação com outras estruturas que apoiam o RLHF, safe-rlhf é o primeiro quadro a apoiar todas as fases, desde SFT até RLHF e Avaliação. Além disso, safe-rlhf é a primeira estrutura que leva em consideração a preferência de segurança durante o estágio RLHF. Ele contém uma garantia mais teórica para a busca restrita de parâmetros no espaço político.
| OFVM | Treinamento do Modelo de Preferência 1 | RLHF | RLHF seguro | Perda de PTX | Avaliação | Back-end | |
|---|---|---|---|---|---|---|---|
| Castor (Seguro-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | Velocidade Profunda |
| trlX | ✔️ | 2 | ✔️ | Acelerar / NeMo | |||
| Bate-papo DeepSpeed | ✔️ | ✔️ | ✔️ | ✔️ | Velocidade Profunda | ||
| Colossal-AI | ✔️ | ✔️ | ✔️ | ✔️ | ColossalAI | ||
| Fazenda Alpaca | 3 | ✔️ | ✔️ | ✔️ | Acelerar |
O conjunto de dados PKU-SafeRLHF é um conjunto de dados rotulado por humanos que contém preferências de desempenho e segurança. Inclui restrições em mais de dez dimensões, como insultos, imoralidade, crime, danos emocionais e privacidade, entre outras. Essas restrições são projetadas para um alinhamento de valor refinado na tecnologia RLHF.
Para facilitar o ajuste fino de várias rodadas, divulgaremos os pesos dos parâmetros iniciais, os conjuntos de dados necessários e os parâmetros de treinamento para cada rodada. Isso garante reprodutibilidade em pesquisas científicas e acadêmicas. O conjunto de dados será lançado gradualmente por meio de atualizações contínuas.
O conjunto de dados está disponível em Hugging Face: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K é um subconjunto de PKU-SafeRLHF que contém a primeira rodada de dados de treinamento Safe RLHF com 10 mil instâncias, incluindo preferências de segurança. Você pode encontrá-lo em Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K.
Iremos liberar gradualmente os conjuntos de dados completos do Safe-RLHF, que incluem 1 milhão de pares rotulados por humanos para preferências úteis e inofensivas.
Beaver é um grande modelo de linguagem baseado em LLaMA, treinado usando safe-rlhf . Ele é desenvolvido com base no modelo Alpaca, coletando dados de preferência humana relacionados à utilidade e inocuidade e empregando a técnica Safe RLHF para treinamento. Ao mesmo tempo que mantém o desempenho útil do Alpaca, o Beaver melhora significativamente a sua inocuidade.
Os castores são conhecidos como os "engenheiros de barragens naturais", pois são adeptos do uso de galhos, arbustos, pedras e solo para construir barragens e pequenas casas de madeira, criando ambientes pantanosos adequados para outras criaturas habitarem, tornando-os uma parte indispensável do ecossistema. . Para garantir a segurança e a confiabilidade dos Grandes Modelos de Linguagem (LLMs), ao mesmo tempo em que acomoda uma ampla gama de valores em diferentes populações, a equipe da Universidade de Pequim nomeou seu modelo de código aberto de "Beaver" e pretende construir uma barragem para LLMs por meio do Valor Restringido. Tecnologia de alinhamento (CVA). Esta tecnologia permite a rotulagem refinada de informações e, combinada com métodos seguros de aprendizagem por reforço, reduz significativamente o preconceito e a discriminação do modelo, aumentando assim a segurança do modelo. Análogo ao papel dos castores no ecossistema, o modelo Beaver fornecerá um apoio crucial para o desenvolvimento de grandes modelos de linguagem e fará contribuições positivas para o desenvolvimento sustentável da tecnologia de inteligência artificial.
Seguindo a metodologia de avaliação do modelo Vicuna, utilizamos o GPT-4 para avaliar Beaver. Os resultados indicam que, em comparação com o Alpaca, o Beaver apresenta melhorias significativas em múltiplas dimensões relacionadas com a segurança.
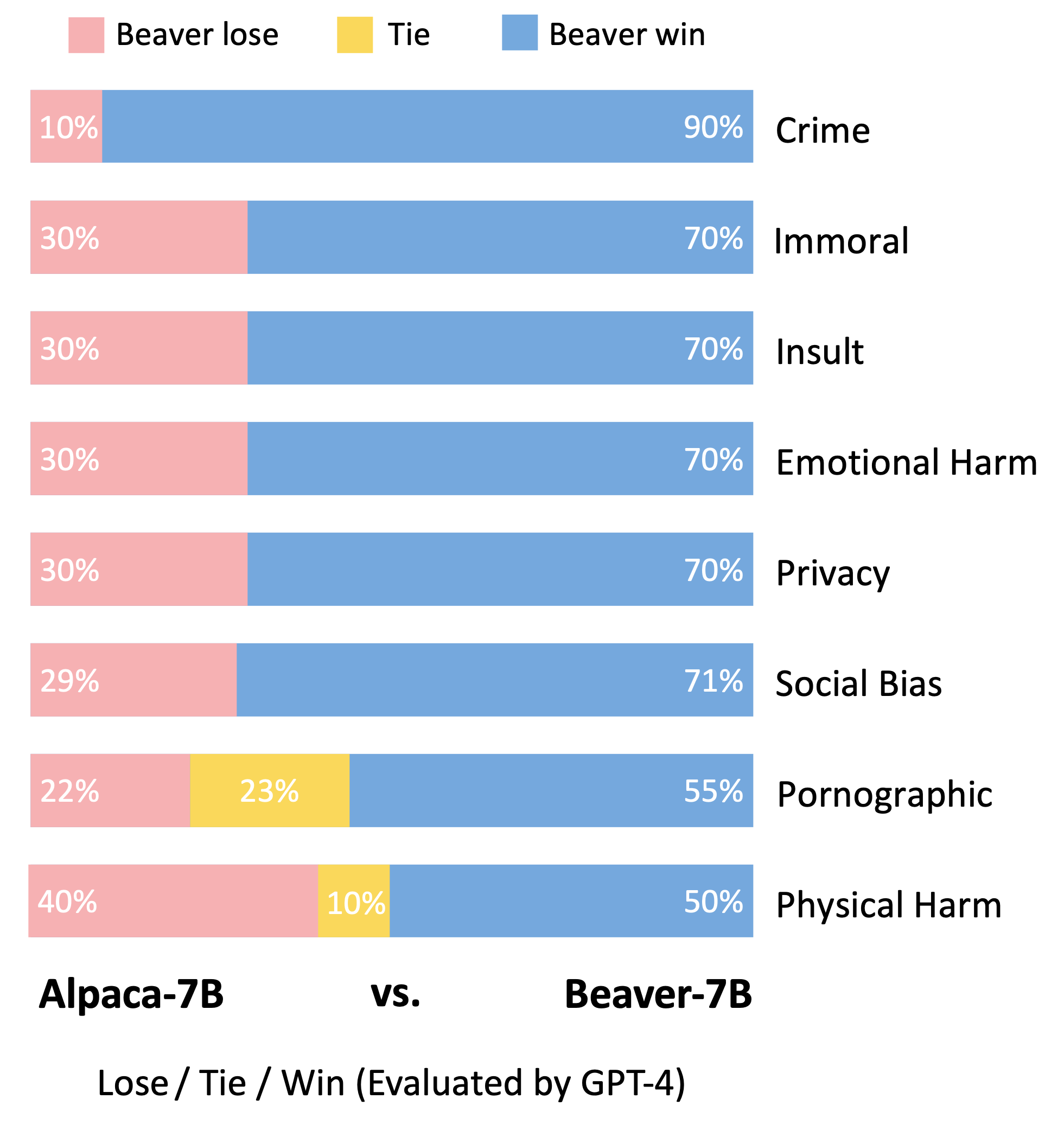
Mudança significativa na distribuição das preferências de segurança após a utilização do gasoduto Safe RLHF no modelo Alpaca-7B.
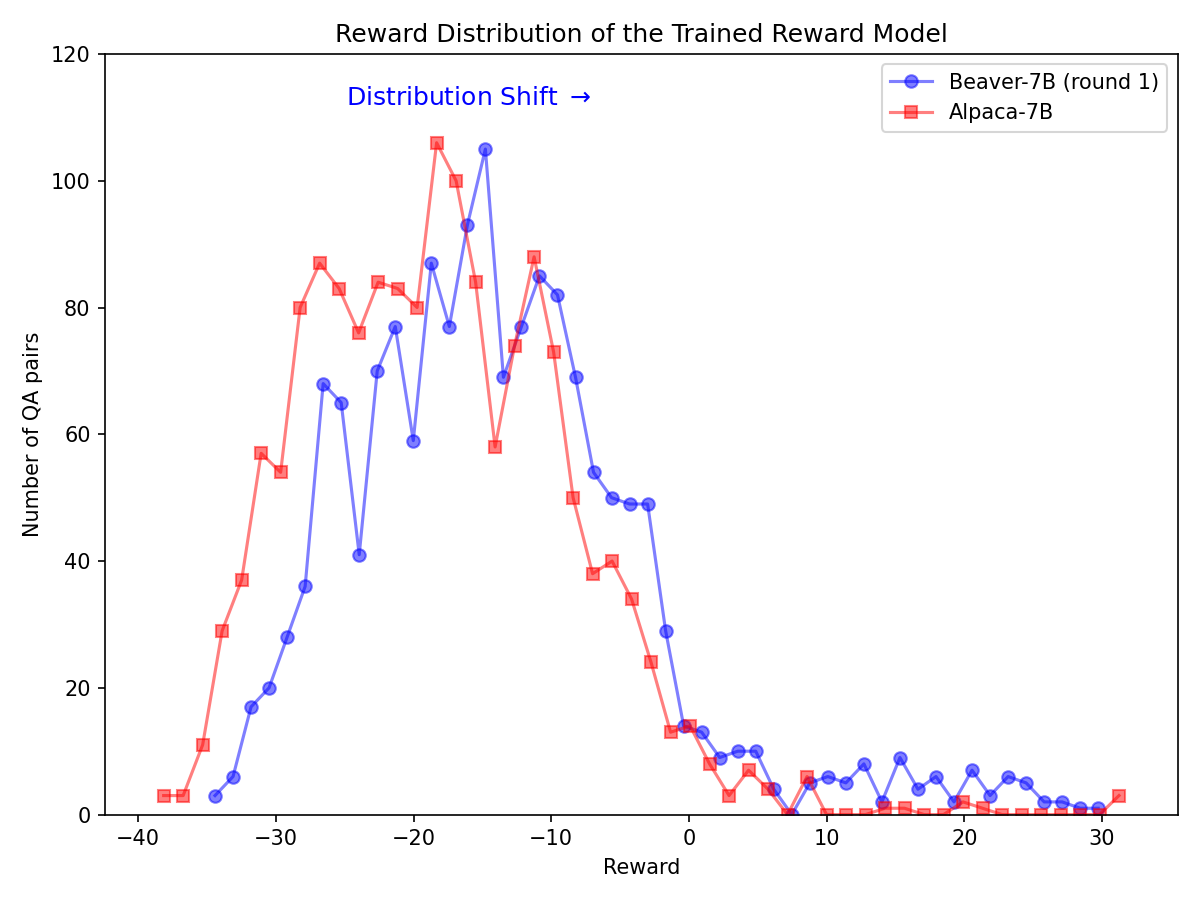 | 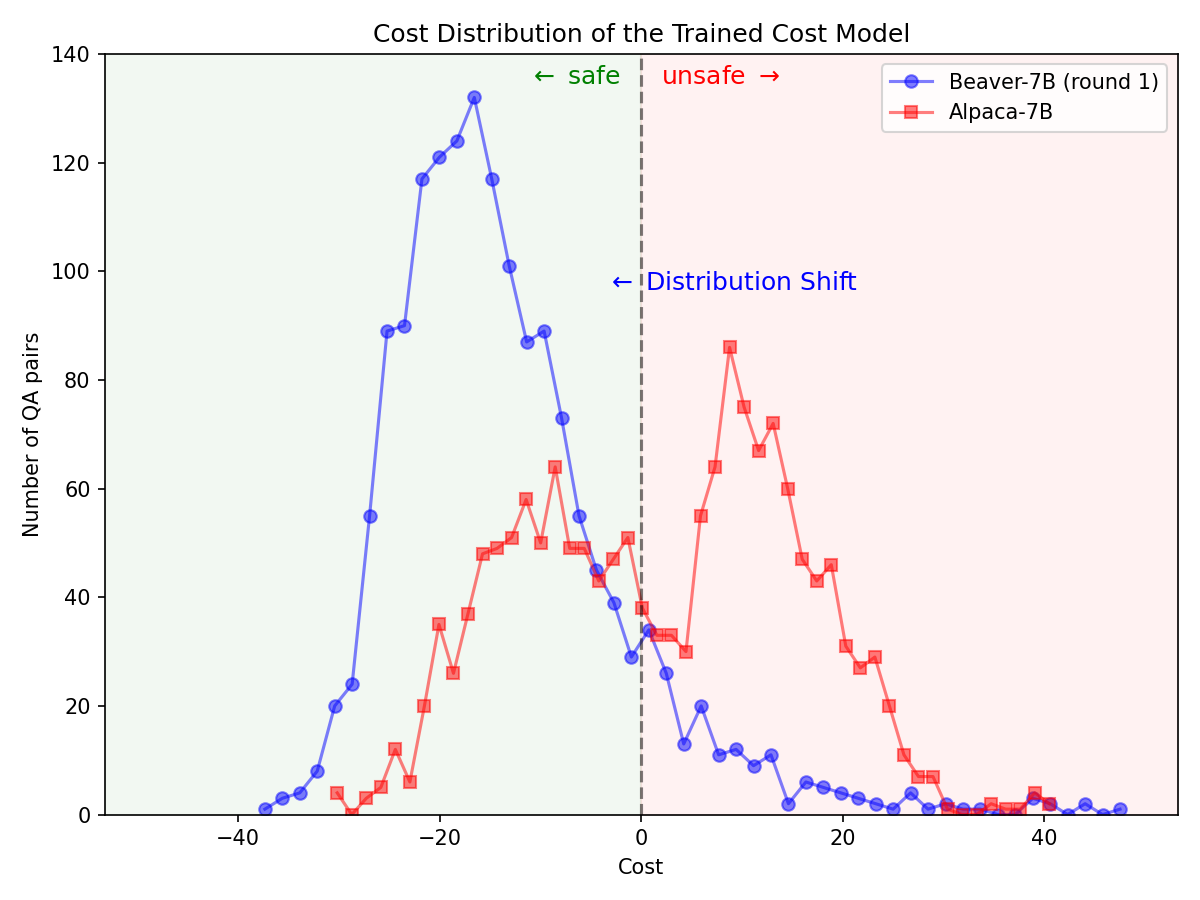 |
Clone o código-fonte do GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: Configure um ambiente conda usando conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Isso configurará automaticamente todas as dependências.
Containerized Runner: Além de usar a máquina nativa com isolamento conda, como alternativa, você também pode usar imagens docker para configurar o ambiente.
Em primeiro lugar, siga NVIDIA Container Toolkit: Installation Guide e NVIDIA Docker: Installation Guide para configurar nvidia-docker . Então você pode executar:
make docker-run Este comando irá construir e iniciar um contêiner docker instalado com as dependências adequadas. O caminho do host / será mapeado para /host e o diretório de trabalho atual será mapeado para /workspace dentro do contêiner.
safe-rlhf oferece suporte a um pipeline completo, desde ajuste fino supervisionado (SFT) até treinamento de modelo preferencial e treinamento de alinhamento RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereou
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftNOTA: Pode ser necessário atualizar alguns dos parâmetros do script de acordo com a configuração da sua máquina, como o número de GPUs para treinamento, o tamanho do lote de treinamento, etc.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagUm exemplo de comandos para executar todo o pipeline com LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagTodos os processos de treinamento listados acima são testados com LLaMA-7B em um servidor em nuvem com 8 GPUs NVIDIA A800-80GB.
Os usuários que não possuem recursos de memória de GPU suficientes podem ativar o DeepSpeed ZeRO-Offload para aliviar o pico de uso de memória da GPU.
Todos os scripts de treinamento podem passar com uma opção extra --offload (o padrão é none , ou seja, desabilitar ZeRO-Offload) para descarregar os tensores (parâmetros e/ou estados do otimizador) para a CPU. Por exemplo:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Para configurações de vários nós, os usuários podem consultar a documentação DeepSpeed: Configuração de recursos (vários nós) para obter mais detalhes. Aqui está um exemplo para iniciar o processo de treinamento em 4 nós (cada um com 8 GPUs):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Em seguida, inicie os scripts de treinamento com:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf fornece uma abstração para criar conjuntos de dados para todos os estágios de ajuste fino supervisionado, treinamento de modelo de preferência e treinamento de RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""Aqui está um exemplo para implementar um conjunto de dados personalizado (veja safe_rlhf/datasets/raw para mais exemplos):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Então você pode passar esse conjunto de dados para os scripts de treinamento como:
python3 train.py --datasets my-dataset-name Você também pode passar vários conjuntos de dados com proporções de conjuntos de dados opcionalmente adicionais (separados por dois pontos : . Por exemplo:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5Isso usará a divisão aleatória de 75% do conjunto de dados Stanford Alpaca e 50% do seu conjunto de dados personalizado.
Além disso, o argumento do conjunto de dados também pode ser seguido por um caminho local (separado por dois pontos : ) se você já tiver clonado o repositório do conjunto de dados do Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryNOTA: A classe do conjunto de dados deve ser importada antes que o script de treinamento comece a analisar os argumentos da linha de comando.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
O pipeline Safe-RLHF suporta não apenas a família de modelos LLaMA, mas também outros modelos pré-treinados, como Baichuan, InternLM, etc., que oferecem melhor suporte para chineses. Você só precisa atualizar o caminho para o modelo pré-treinado no código de treinamento e inferência.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型,例如 Baichuan和 InternLM 等。你只需要在训练和推理的代码中更新预训练模型的路径即可。
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft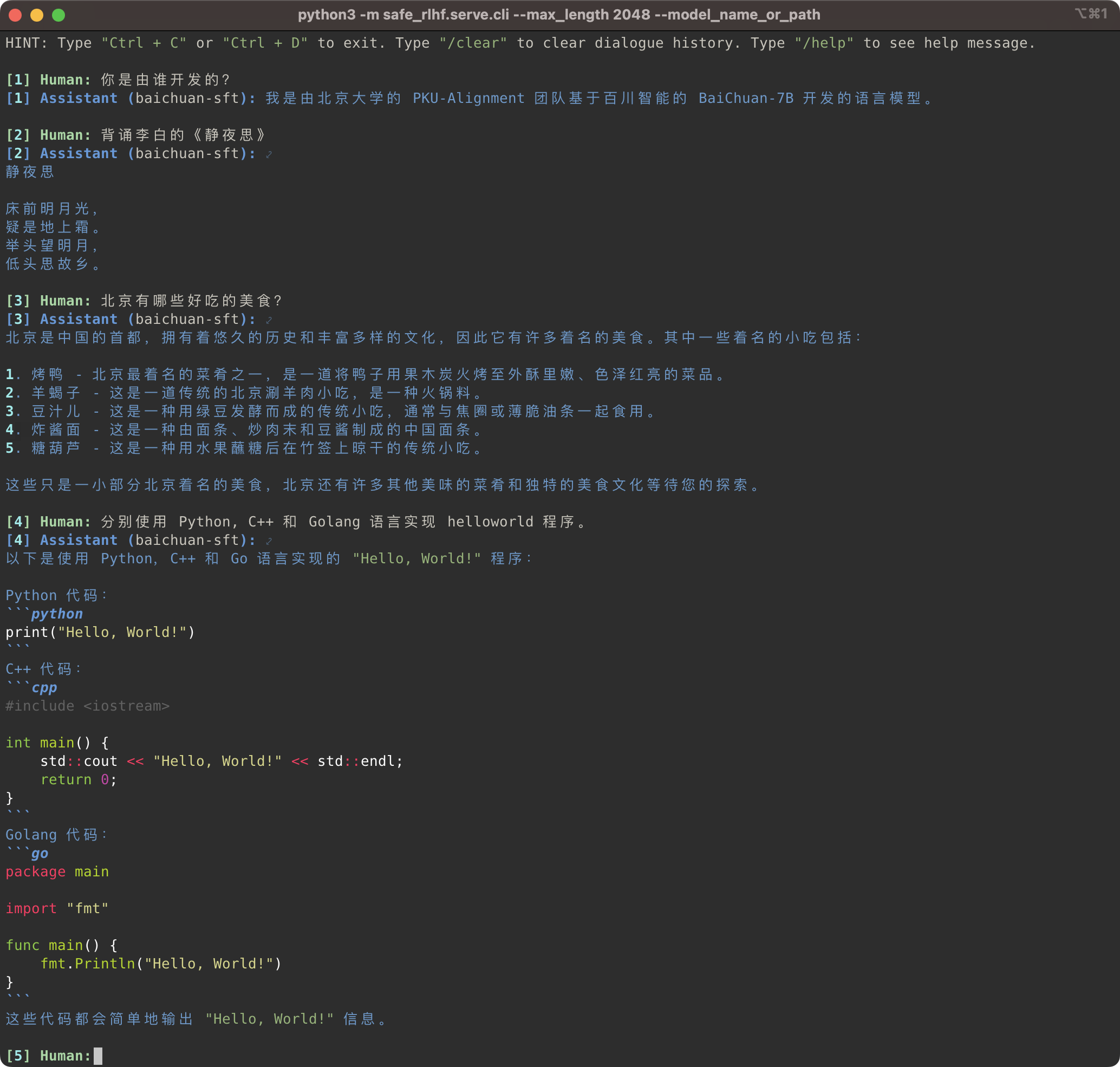
Enquanto isso, adicionamos suporte para conjuntos de dados chineses, como as séries Firefly e MOSS, aos nossos conjuntos de dados brutos. Você só precisa alterar o caminho do conjunto de dados no código de treinamento para usar o conjunto de dados correspondente para ajustar o modelo de pré-treinamento chinês:
同时,我们也在 conjuntos de dados brutos 中增加了支持一些中文数据集,例如 Firefly e MOSS系列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Para obter instruções sobre como adicionar conjuntos de dados personalizados, consulte a seção Conjuntos de dados personalizados.
关于如何添加自定义数据集的方法,请参阅章节 Conjuntos de dados personalizados (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagSe você achar o Safe-RLHF útil ou usar o Safe-RLHF (modelo, código, conjunto de dados, etc.) em sua pesquisa, considere citar o seguinte trabalho em suas publicações.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Todos os alunos abaixo contribuíram igualmente e a ordem é determinada em ordem alfabética:
Todos assessorados por Yizhou Wang e Yaodong Yang. Reconhecer: Agradecemos a Sra. Yi Qu por projetar o logotipo do Beaver.
Este repositório se beneficia de LLaMA, Stanford Alpaca, DeepSpeed e DeepSpeed-Chat. Obrigado por seus maravilhosos trabalhos e seus esforços para democratizar a pesquisa de LLM. Safe-RLHF e seus ativos relacionados são construídos e de código aberto com amor ?❤️.
Este trabalho é apoiado e financiado pela Universidade de Pequim.
 |  |
Safe-RLHF é lançado sob licença Apache 2.0.


