guidance for natural language queries of relational databases on aws
1.0.0
Esta solução AWS contém uma demonstração de IA generativa, especificamente, o uso de Natural Language Query (NLQ) para fazer perguntas a um banco de dados Amazon RDS para PostgreSQL. Esta solução oferece três opções de arquitetura para modelos básicos: 1. Amazon SageMaker JumpStart, 2. Amazon Bedrock e 3. API OpenAI. O aplicativo baseado na Web da demonstração, executado no Amazon ECS no AWS Fargate, usa uma combinação de LangChain, Streamlit, Chroma e HuggingFace SentenceTransformers. O aplicativo aceita perguntas em linguagem natural dos usuários finais e retorna respostas em linguagem natural, juntamente com a consulta SQL associada e o conjunto de resultados compatível com o Pandas DataFrame.
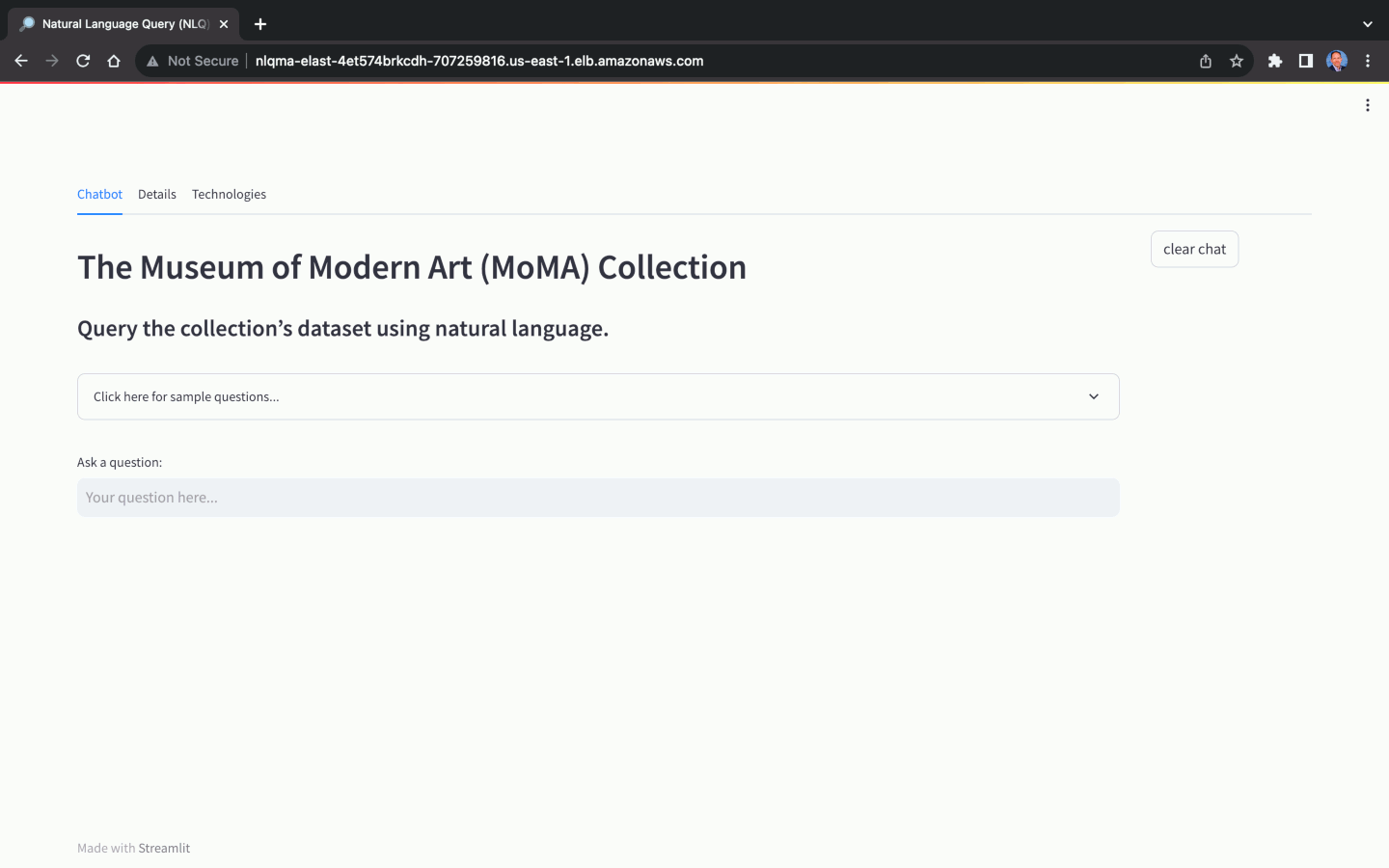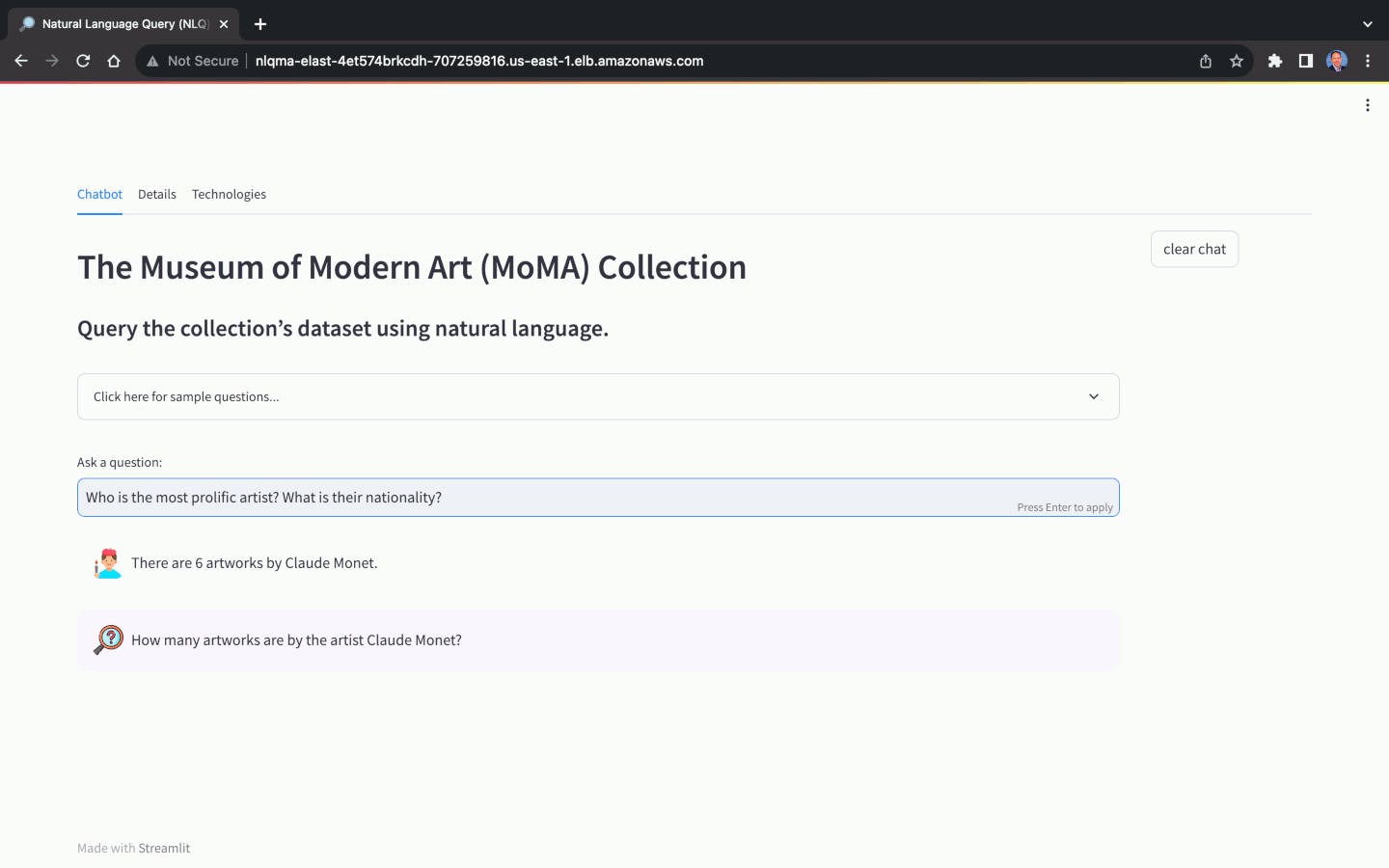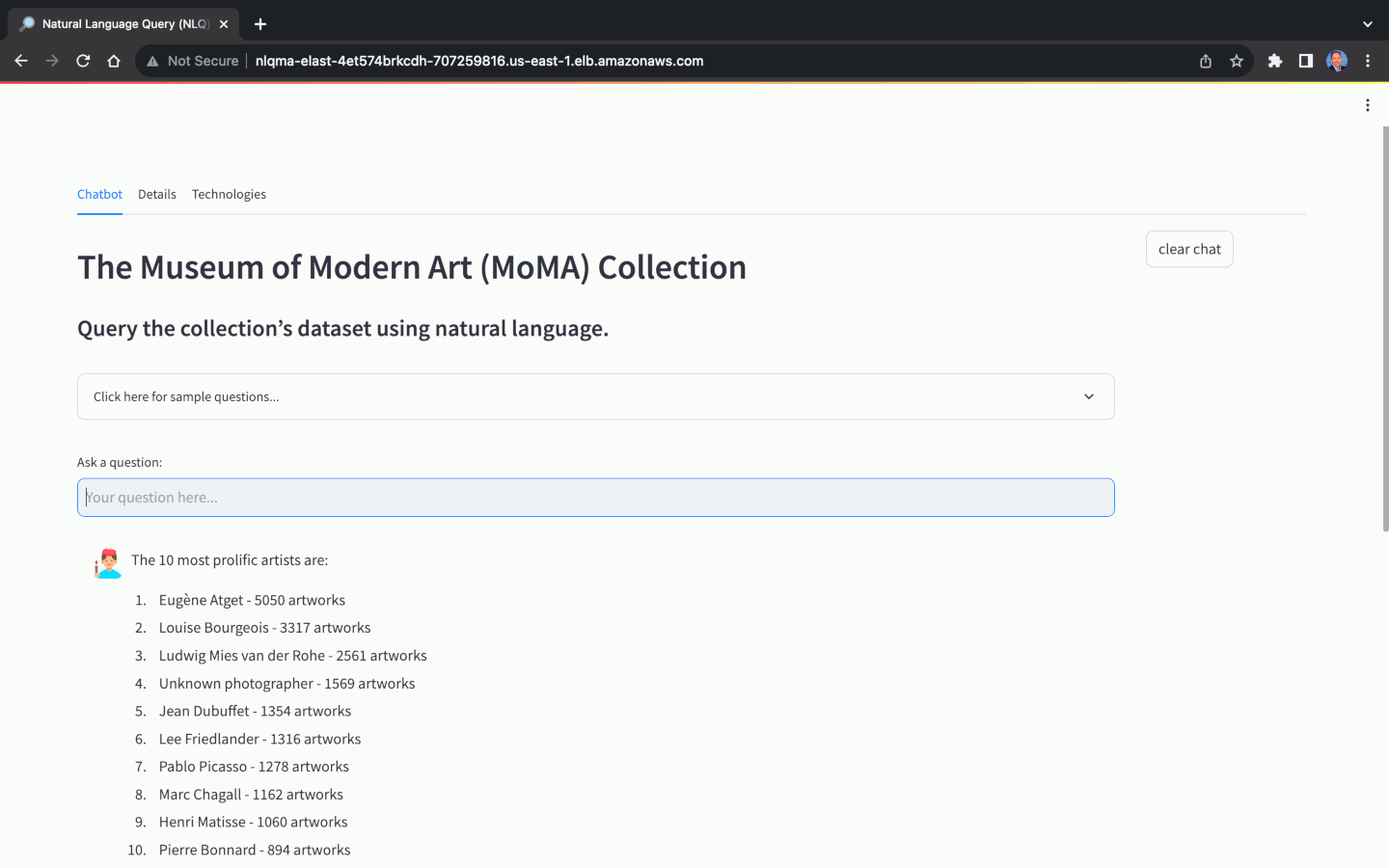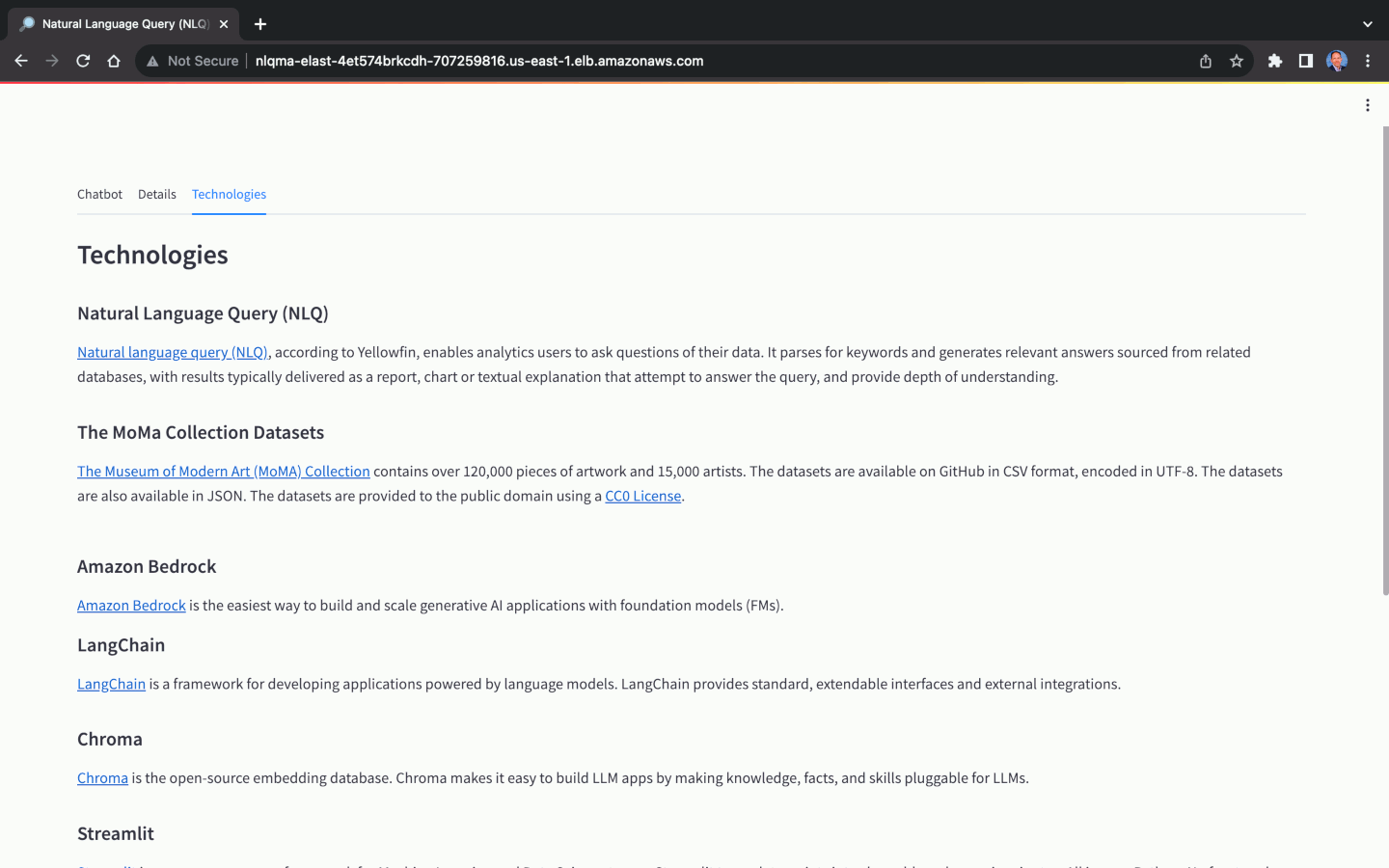
A seleção do Modelo Básico (FM) para Consulta em Linguagem Natural (NLQ) desempenha um papel crucial na capacidade do aplicativo de traduzir com precisão perguntas de linguagem natural em respostas de linguagem natural. Nem todos os FMs são capazes de realizar NLQ. Além da escolha do modelo, a precisão do NLQ também depende muito de fatores como a qualidade do prompt, modelo de prompt, consultas de amostra rotuladas usadas para aprendizagem no contexto ( também conhecidas como prompts de poucos disparos ) e as convenções de nomenclatura usadas para o esquema do banco de dados , tabelas e colunas.
O aplicativo NLQ foi testado em uma variedade de FMs comerciais e de código aberto. Como linha de base, os modelos das séries Generative Pre-trained Transformer GPT-3 e GPT-4 da OpenAI, incluindo gpt-3.5-turbo e gpt-4 , fornecem respostas precisas a uma ampla gama de consultas de linguagem natural simples a complexas usando uma média quantidade de aprendizagem no contexto e engenharia imediata mínima.
Amazon Titan Text G1 - Express, amazon.titan-text-express-v1 , disponível no Amazon Bedrock, também foi testado. Este modelo forneceu respostas precisas para consultas básicas em linguagem natural usando alguma otimização de prompt específica do modelo. No entanto, este modelo não foi capaz de responder a consultas mais complexas. Uma otimização imediata adicional pode melhorar a precisão do modelo.
Modelos de código aberto, como google/flan-t5-xxl e google/flan-t5-xxl-fp16 (versão em formato de ponto flutuante de meia precisão (FP16) do modelo completo), estão disponíveis por meio do Amazon SageMaker JumpStart. Embora a série de modelos google/flan-t5 seja uma escolha popular para a construção de aplicativos de IA generativa, seus recursos para NLQ são limitados em comparação com modelos comerciais e de código aberto mais recentes. O google/flan-t5-xxl-fp16 da demonstração é capaz de responder a consultas básicas de linguagem natural com aprendizado contextual suficiente. No entanto, muitas vezes falhava durante o teste ao retornar uma resposta ou fornecer respostas corretas, e frequentemente causava tempos limite de endpoint do modelo SageMaker devido ao esgotamento de recursos quando confrontado com consultas moderadas a complexas.
Esta solução usa uma cópia otimizada para NLQ do banco de dados de código aberto, Coleção do Museu de Arte Moderna (MoMA), disponível no GitHub. O banco de dados do MoMA contém mais de 121 mil peças de arte e 15 mil artistas. Este repositório do projeto contém arquivos de texto delimitados por barras verticais que podem ser facilmente importados para a instância de banco de dados Amazon RDS for PostgreSQL.
Usando o conjunto de dados do MoMA, podemos fazer perguntas em linguagem natural, com diversos níveis de complexidade:
Novamente, a capacidade do aplicativo NLQ de retornar uma resposta e retornar uma resposta precisa depende principalmente da escolha do modelo. Nem todos os modelos são capazes de NLQ, enquanto outros não retornarão respostas precisas. Otimizar os prompts acima para modelos específicos pode ajudar a melhorar a precisão.
ml.g5.24xlarge para google/flan-t5-xxl-fp16 modelo google/flan-t5-xxl-fp16 ). Consulte a documentação do modelo para a escolha dos tipos de instância.NlqMainStack CloudFormation. Observe que você precisará ter usado o Amazon ECS pelo menos um em sua conta, ou a função vinculada ao serviço AWSServiceRoleForECS ainda não existirá e a pilha falhará. Verifique a função vinculada ao serviço AWSServiceRoleForECS antes de implantar a pilha NlqMainStack . Essa função é criada automaticamente na primeira vez que você cria um cluster ECS em sua conta.nlq-genai:2.0.0-sm para o novo repositório do Amazon ECR. Como alternativa, crie e envie a imagem nlq-genai:2.0.0-bedrock ou nlq-genai:2.0.0-oai Docker para uso com a Opção 2: Amazon Bedrock ou Opção 3: API OpenAI.nlqapp ao banco de dados do MoMA.NlqSageMakerEndpointStack CloudFormation.NlqEcsSageMakerStack CloudFormation. Como alternativa, implante o modelo NlqEcsBedrockStack CloudFormation para uso com a Opção 2: Amazon Bedrock ou o modelo NlqEcsOpenAIStack para uso com a Opção 3: API OpenAI. Para a Opção 1: Amazon SageMaker JumpStart, certifique-se de ter a instância EC2 necessária para a inferência de endpoint do Amazon SageMaker JumpStart ou solicite-a usando Service Quotas no AWS Management Console (por exemplo, ml.g5.24xlarge para google/flan-t5-xxl-fp16 modelo google/flan-t5-xxl-fp16 ). Consulte a documentação do modelo para a escolha dos tipos de instância.
Certifique-se de atualizar os valores secretos abaixo antes de continuar. Esta etapa criará segredos para as credenciais do aplicativo NLQ. O acesso do aplicativo NLQ ao banco de dados é limitado somente leitura. Para a Opção 3: API OpenAI, esta etapa criará um segredo para armazenar sua chave de API OpenAI. As credenciais de usuário mestre para a instância do Amazon RDS são definidas automaticamente e armazenadas no AWS Secret Manager como parte da implantação do modelo NlqMainStack CloudFormation. Esses valores podem ser encontrados no AWS Secret Manager.
aws secretsmanager create-secret
--name /nlq/NLQAppUsername
--description " NLQ Application username for MoMA database. "
--secret-string " <your_nlqapp_username> "
aws secretsmanager create-secret
--name /nlq/NLQAppUserPassword
--description " NLQ Application password for MoMA database. "
--secret-string " <your_nlqapp_password> "
# Only for Option 2: OpenAI API/model
aws secretsmanager create-secret
--name /nlq/OpenAIAPIKey
--description " OpenAI API key. "
--secret-string " <your_openai_api_key "O acesso ao ALB e ao RDS será limitado externamente ao seu endereço IP atual. Você precisará atualizar se o seu endereço IP mudar após a implantação.
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqMainStack
--template-body file://NlqMainStack.yaml
--capabilities CAPABILITY_NAMED_IAM
--parameters ParameterKey= " MyIpAddress " ,ParameterValue= $( curl -s http://checkip.amazonaws.com/ ) /32Crie as imagens do Docker para o aplicativo NLQ com base na sua escolha de opções de modelo. Você pode criar imagens do Docker localmente, em um pipeline de CI/CD, usando o ambiente SageMaker Notebook ou AWS Cloud9. Prefiro o AWS Cloud9 para desenvolver e testar o aplicativo e construir as imagens Docker.
cd docker/
# Located in the output from the NlqMlStack CloudFormation template
# e.g. 111222333444.dkr.ecr.us-east-1.amazonaws.com/nlq-genai
ECS_REPOSITORY= " <you_ecr_repository> "
aws ecr get-login-password --region us-east-1 |
docker login --username AWS --password-stdin $ECS_REPOSITORYOpção 1: Amazon SageMaker JumpStart
TAG= " 2.0.0-sm "
docker build -f Dockerfile_SageMaker -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOpção 2: Amazon Bedrock
TAG= " 2.0.0-bedrock "
docker build -f Dockerfile_Bedrock -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOpção 3: API OpenAI
TAG= " 2.0.0-oai "
docker build -f Dockerfile_OpenAI -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG 5a. Conecte-se ao banco de dados moma usando sua ferramenta PostgreSQL preferida. Você precisará habilitar temporariamente Public access para a instância do RDS, dependendo de como você se conecta ao banco de dados.
5b. Crie as duas tabelas de coleção do MoMA no banco de dados moma .
CREATE TABLE public .artists
(
artist_id integer NOT NULL ,
full_name character varying ( 200 ),
nationality character varying ( 50 ),
gender character varying ( 25 ),
birth_year integer ,
death_year integer ,
CONSTRAINT artists_pk PRIMARY KEY (artist_id)
)
CREATE TABLE public .artworks
(
artwork_id integer NOT NULL ,
title character varying ( 500 ),
artist_id integer NOT NULL ,
date integer ,
medium character varying ( 250 ),
dimensions text ,
acquisition_date text ,
credit text ,
catalogue character varying ( 250 ),
department character varying ( 250 ),
classification character varying ( 250 ),
object_number text ,
diameter_cm text ,
circumference_cm text ,
height_cm text ,
length_cm text ,
width_cm text ,
depth_cm text ,
weight_kg text ,
durations integer ,
CONSTRAINT artworks_pk PRIMARY KEY (artwork_id)
) 5c. Descompacte e importe os dois arquivos de dados para o banco de dados moma usando os arquivos de texto no subdiretório /data . Os dois arquivos contêm uma linha de cabeçalho e delimitados por barras verticais ('|').
# examples commands from pgAdmin4
--command " "\copy public.artists (artist_id, full_name, nationality, gender, birth_year, death_year) FROM 'moma_public_artists.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""
--command " "\copy public.artworks (artwork_id, title, artist_id, date, medium, dimensions, acquisition_date, credit, catalogue, department, classification, object_number, diameter_cm, circumference_cm, height_cm, length_cm, width_cm, depth_cm, weight_kg, durations) FROM 'moma_public_artworks.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""Crie a conta de usuário do banco de dados do aplicativo NLQ somente leitura. Atualize os valores de nome de usuário e senha no script SQL, em três locais, com os segredos configurados na Etapa 2 acima.
CREATE ROLE < your_nlqapp_username > WITH
LOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT - 1
PASSWORD ' <your_nlqapp_password> ' ;
GRANT
pg_read_all_data
TO
< your_nlqapp_username > ;Opção 1: Amazon SageMaker JumpStart
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqSageMakerEndpointStack
--template-body file://NlqSageMakerEndpointStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpção 1: Amazon SageMaker JumpStart
aws cloudformation create-stack
--stack-name NlqEcsSageMakerStack
--template-body file://NlqEcsSageMakerStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpção 2: Amazon Bedrock
aws cloudformation create-stack
--stack-name NlqEcsBedrockStack
--template-body file://NlqEcsBedrockStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpção 3: API OpenAI
aws cloudformation create-stack
--stack-name NlqEcsOpenAIStack
--template-body file://NlqEcsOpenAIStack.yaml
--capabilities CAPABILITY_NAMED_IAM Você pode substituir o modelo JumpStart Foundation padrão google/flan-t5-xxl-fp16 , implantado usando o arquivo de modelo NlqSageMakerEndpointStack.yaml CloudFormation. Primeiro, você precisará modificar os parâmetros do modelo no arquivo NlqSageMakerEndpointStack.yaml e atualizar a pilha CloudFormation implantada, NlqSageMakerEndpointStack . Além disso, você precisará fazer ajustes no aplicativo NLQ, app_sagemaker.py , modificando a classe ContentHandler para corresponder à carga de resposta do modelo escolhido. Em seguida, reconstrua a imagem do Docker do Amazon ECR, incrementando a versão, por exemplo, nlq-genai-2.0.1-sm , usando o Dockerfile_SageMaker Dockerfile e envie para o repositório do Amazon ECR. Por último, você precisará atualizar a tarefa e o serviço ECS implantados, que fazem parte da pilha NlqEcsSageMakerStack CloudFormation.
Para mudar do modelo básico Amazon Titan Text G1 - Express ( amazon.titan-text-express-v1 ) padrão da solução, você precisa modificar e implantar novamente o arquivo de modelo NlqEcsBedrockStack.yaml CloudFormation. Além disso, você precisará modificar o aplicativo NLQ, app_bedrock.py Em seguida, reconstrua a imagem Docker do Amazon ECR usando o Dockerfile_Bedrock Dockerfile e envie a imagem resultante, por exemplo, nlq-genai-2.0.1-bedrock , para o repositório Amazon ECR . Por último, você precisará atualizar a tarefa e o serviço ECS implantados, que fazem parte da pilha NlqEcsBedrockStack CloudFormation.
Mudar da API OpenAI padrão da solução para a API de outro provedor de modelo de terceiros, como Cohere ou Anthropic, é igualmente simples. Para utilizar os modelos OpenAI, primeiro você precisa criar uma conta OpenAI e obter sua própria chave API pessoal. Em seguida, modifique e reconstrua a imagem do Docker do Amazon ECR usando o Dockerfile_OpenAI Dockerfile e envie a imagem resultante, por exemplo, nlq-genai-2.0.1-oai , para o repositório do Amazon ECR. Por fim, modifique e reimplante o arquivo de modelo NlqEcsOpenAIStack.yaml CloudFormation.
Consulte CONTRIBUINDO para obter mais informações.
Esta biblioteca está licenciada sob a licença MIT-0. Veja o arquivo LICENÇA.


