ContraCLM
1.0.0
Este repositório contém código para o artigo ACL 2023, ContraCLM: Contrastive Learning for Causal Language Model.
Trabalho realizado por: Nihal Jain*, Dejiao Zhang*, Wasi Uddin Ahmad*, Zijian Wang, Feng Nan, Xiaopeng Li, Ming Tan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Xiaofei Ma, Bing Xiang. (* indica contribuição igual ).
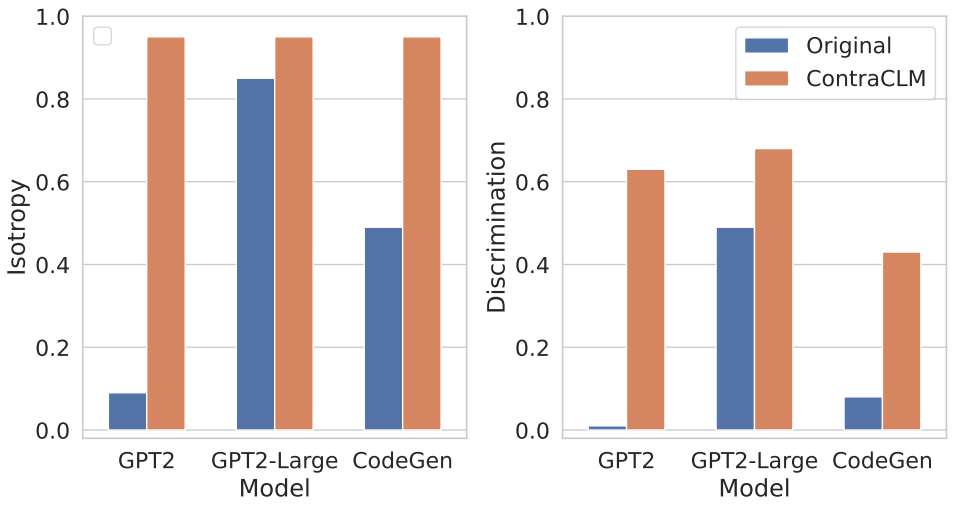
Apresentamos o ContraCLM, uma nova estrutura de aprendizagem contrastiva que opera tanto no nível do token quanto no nível da sequência. O ContraCLM aprimora a discriminação de representações de um modelo de linguagem somente decodificador e preenche a lacuna com modelos somente de codificador, tornando os modelos de linguagem causal mais adequados para tarefas além da geração de linguagem. Nós encorajamos você a verificar nosso artigo para mais detalhes.
A configuração envolve a instalação das dependências necessárias em um ambiente e a colocação dos conjuntos de dados no diretório necessário.
Execute estes comandos para criar um novo ambiente conda e instalar os pacotes necessários para este repositório.
# create a new conda environment with python >= 3.8
conda create -n contraclm python=3.8.12
# install dependencies within the environment
conda activate contraclm
pip install -r requirements.txtVeja aqui.
Nesta seção, mostramos como usar este repositório para pré-treinar (i) GPT2 em dados de linguagem natural (NL) e (ii) CodeGen-350M-Mono em dados de linguagem de programação (PL).
Esta seção pressupõe que você tenha os dados de treinamento e validação armazenados em TRAIN_DIR e VALID_DIR respectivamente e esteja em um ambiente com todas as dependências acima instaladas (consulte Configuração).
Você pode obter uma visão geral de todos os sinalizadores associados ao pré-treinamento executando:
python pl_trainer.py --helpGPT2 em dados NL bash runscripts/run_wikitext.sh
CL_Config=$(eval echo ${options[1]}) dentro do script.CodeGen-350M-Mono em dados PL Configure as variáveis na parte superior de runscripts/run_code.sh . Existem muitas opções, mas apenas as opções de abandono são explicadas aqui (outras são autoexplicativas):
dropout_p : O valor da probabilidade de abandono usado em torch.nn.Dropout
dropout_layers : Se > 0, isso ativará os últimos dropout_layers com probabilidade dropout_p
functional_dropout : se especificado, usará uma camada de eliminação funcional sobre a saída das representações de token do modelo CodeGen
Defina a variável CL de acordo com a configuração do modelo desejado. Certifique-se de que os caminhos para TRAIN_DIR, VALID_DIR estejam definidos conforme desejado.
Execute o comando: bash runscripts/run_code.sh
Consulte os diretórios específicos de tarefas relevantes aqui.
Se você usar nosso código em sua pesquisa, cite nosso trabalho como:
@inproceedings{jain-etal-2023-contraclm,
title = "{C}ontra{CLM}: Contrastive Learning For Causal Language Model",
author = "Jain, Nihal and
Zhang, Dejiao and
Ahmad, Wasi Uddin and
Wang, Zijian and
Nan, Feng and
Li, Xiaopeng and
Tan, Ming and
Nallapati, Ramesh and
Ray, Baishakhi and
Bhatia, Parminder and
Ma, Xiaofei and
Xiang, Bing",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.355",
pages = "6436--6459"
}
Consulte CONTRIBUINDO para obter mais informações.
Este projeto está licenciado sob a licença Apache-2.0.


