tudo-ai
Seu assistente de chatbot local totalmente proficiente, com tecnologia de IA?
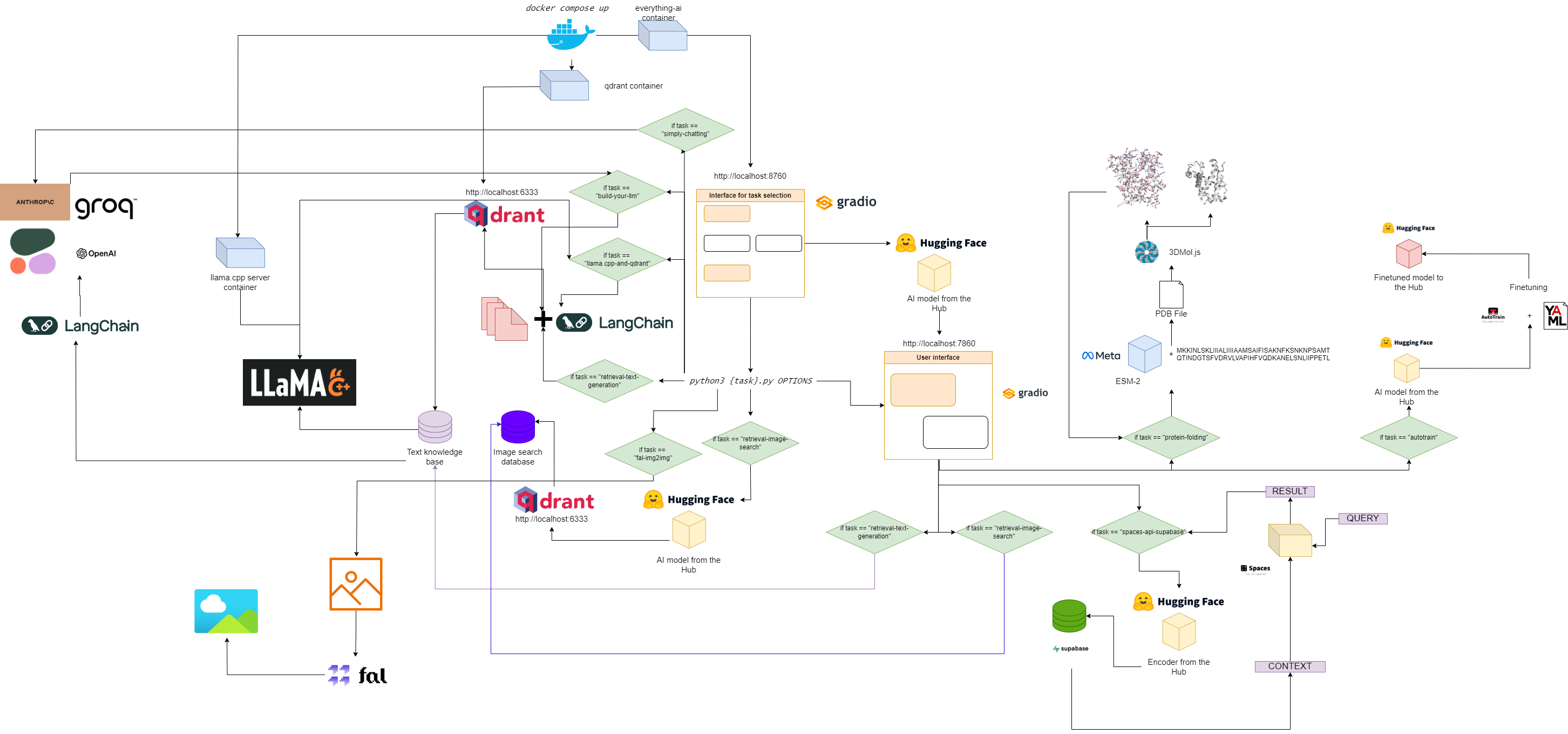
Fluxograma para tudo-ai
Início rápido
1. Clone este repositório
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Defina seu arquivo .env
Modificar:
- Variável
VOLUME no arquivo .env para que você possa montar seu sistema de arquivos local no contêiner Docker. - Variável
MODELS_PATH no arquivo .env para que você possa informar ao llama.cpp onde armazenou os modelos GGUF que você baixou. - Variável
MODEL no arquivo .env para que você possa informar ao llama.cpp qual modelo usar (use o nome real do arquivo gguf e não esqueça a extensão .gguf!) - Variável
MAX_TOKENS no arquivo .env para que você possa informar ao llama.cpp quantos novos tokens ele pode gerar como saída.
Um exemplo de arquivo .env poderia ser:
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Isso significa que agora tudo que está em "c:/Users/User/" em sua máquina local está em "/User/" em seu contêiner Docker, que llama.cpp sabe onde procurar modelos e qual modelo procurar, junto com o máximo de novos tokens para sua saída.
3. Extraia as imagens necessárias
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Execute o aplicativo multicontêiner
5. Vá para localhost:8670 e escolha seu assistente
Você verá algo assim:
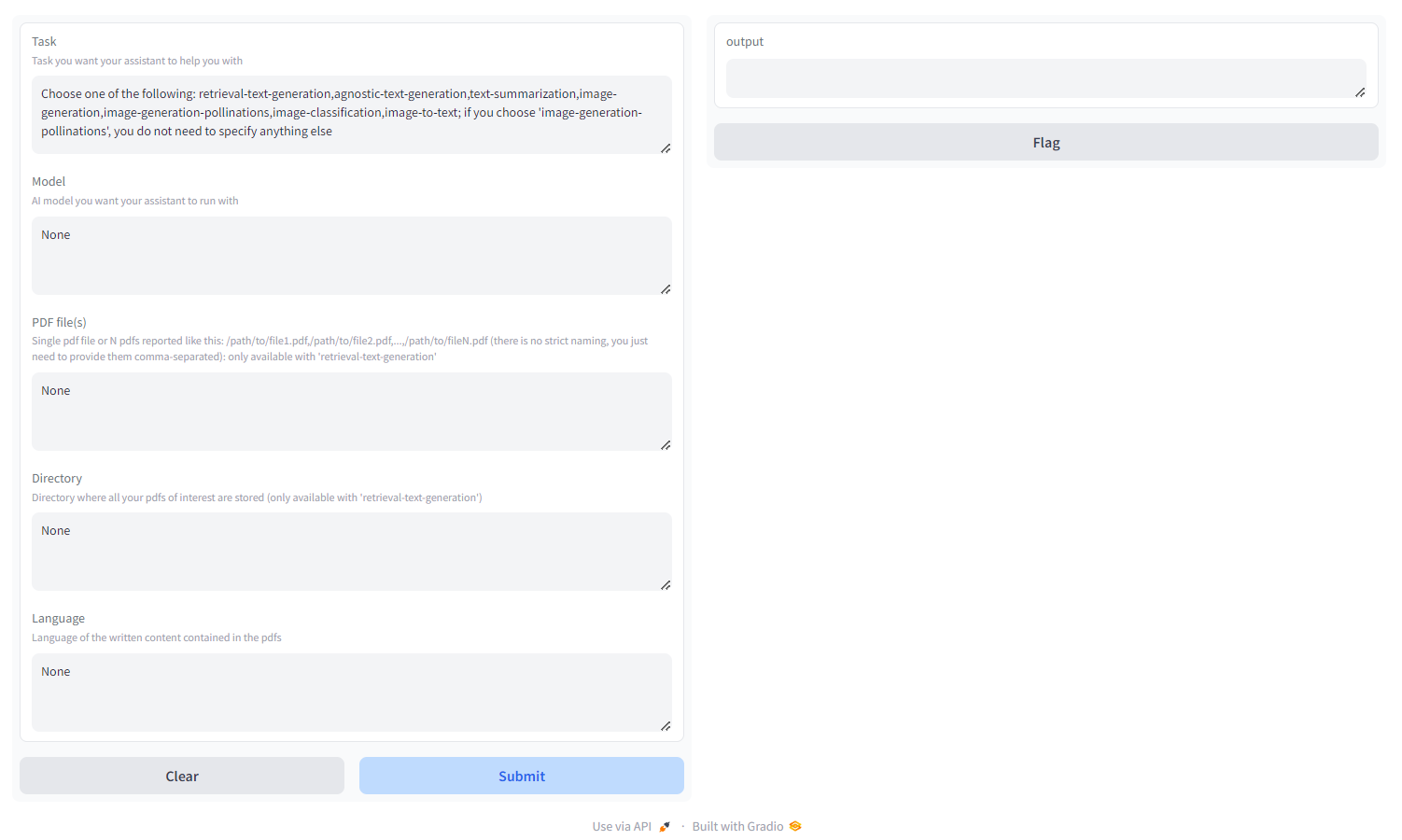
Escolha a tarefa entre:
- geração de texto de recuperação : use o backend
qdrant para construir uma base de conhecimento amigável à recuperação, na qual você pode consultar e ajustar a resposta do seu modelo. Você deve passar um pdf/um monte de pdfs especificados como caminhos separados por vírgula ou um diretório onde todos os pdfs de interesse estão armazenados ( NÃO forneça ambos); você também pode especificar o idioma em que o PDF foi escrito, usando a nomenclatura ISO - MULTILINGUAL - geração de texto agnóstico : geração de texto semelhante ao ChatGPT (sem arquitetura de recuperação), mas suporta todos os modelos de geração de texto no HF Hub (desde que seu hardware suporte!) - MULTILINGUAL
- resumo de texto : resume texto e PDFs, suporta todos os modelos de resumo de texto no HF Hub - SOMENTE EM INGLÊS
- geração de imagem : difusão estável, suporta todos os modelos de texto para imagem no HF Hub - MULTILINGUAL
- polinizações de geração de imagens : difusão estável, use API Pollinations AI; se você escolher 'polinizações de geração de imagens', não precisará especificar mais nada além da tarefa - MULTILINGUE
- classificação de imagem : classifica uma imagem, suporta todos os modelos de classificação de imagem no HF Hub - SOMENTE EM INGLÊS
- imagem para texto : descreve uma imagem, suporta todos os modelos de imagem para texto no HF Hub - SOMENTE EM INGLÊS
- classificação de áudio : classifica arquivos de áudio ou gravações de microfone, suporta modelos de classificação de áudio em hub HF
- reconhecimento de fala : transcreve arquivos de áudio ou gravações de microfone, suporta modelos de reconhecimento automático de fala em hub HF.
- geração de vídeo : gera vídeo mediante solicitação de texto, suporta modelos de texto para vídeo em hub HF - SOMENTE EM INGLÊS
- dobramento de proteínas : obtenha a estrutura 3D de uma proteína a partir de sua sequência de aminoácidos, usando o modelo de backbone ESM-2 - SOMENTE GPU
- autotrain : ajuste um modelo em uma tarefa downstream específica com autotrain-advanced, apenas especificando seu nome de usuário HF, token de escrita HF e o caminho para um arquivo de configuração yaml para o treinamento
- espaços-api-supabase : use a API HF Spaces em combinação com bancos de dados Supabase PostgreSQL para liberar LLMs mais poderosos e bancos de dados vetoriais maiores orientados a RAG - MULTILINGUAL
- llama.cpp-and-qdrant : o mesmo que retrieval-text-Generation , mas usa llama.cpp como mecanismo de inferência, portanto você NÃO DEVE especificar um modelo - MULTILINGUE
- build-your-llm : Crie um LLM de bate-papo personalizável combinando um banco de dados Qdrant com seus PDFs e o poder dos modelos Anthropic, OpenAI, Cohere ou Groq: você só precisa de uma chave de API! Para construir o banco de dados Qdrant, é necessário passar um pdf/um monte de pdfs especificados como caminhos separados por vírgula ou um diretório onde todos os pdfs de interesse estão armazenados ( NÃO forneça ambos); você também pode especificar o idioma em que o PDF foi escrito, usando a nomenclatura ISO - MULTILINGUAL , LANGFUSE INTEGRATION
- simplesmente conversando : crie um LLM de bate-papo personalizável com o poder dos modelos Anthropic, OpenAI, Cohere ou Groq (sem pipeline RAG): você só precisa de uma chave de API! - MULTILINGUE , INTEGRAÇÃO LANGFUSE
- fal-img2img : Use a API fal.ai ComfyUI para gerar imagens a partir de suas imagens PNG e JPEG: você só precisa de uma chave de API! Você também pode personalizar a geração trabalhando com prompts e sementes - SOMENTE EM INGLÊS
- image-retrieval-search : pesquise um banco de dados de imagens carregando uma pasta como entrada do banco de dados. A pasta deverá ter a seguinte estrutura:
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Você pode consultar o banco de dados a partir de suas próprias imagens.
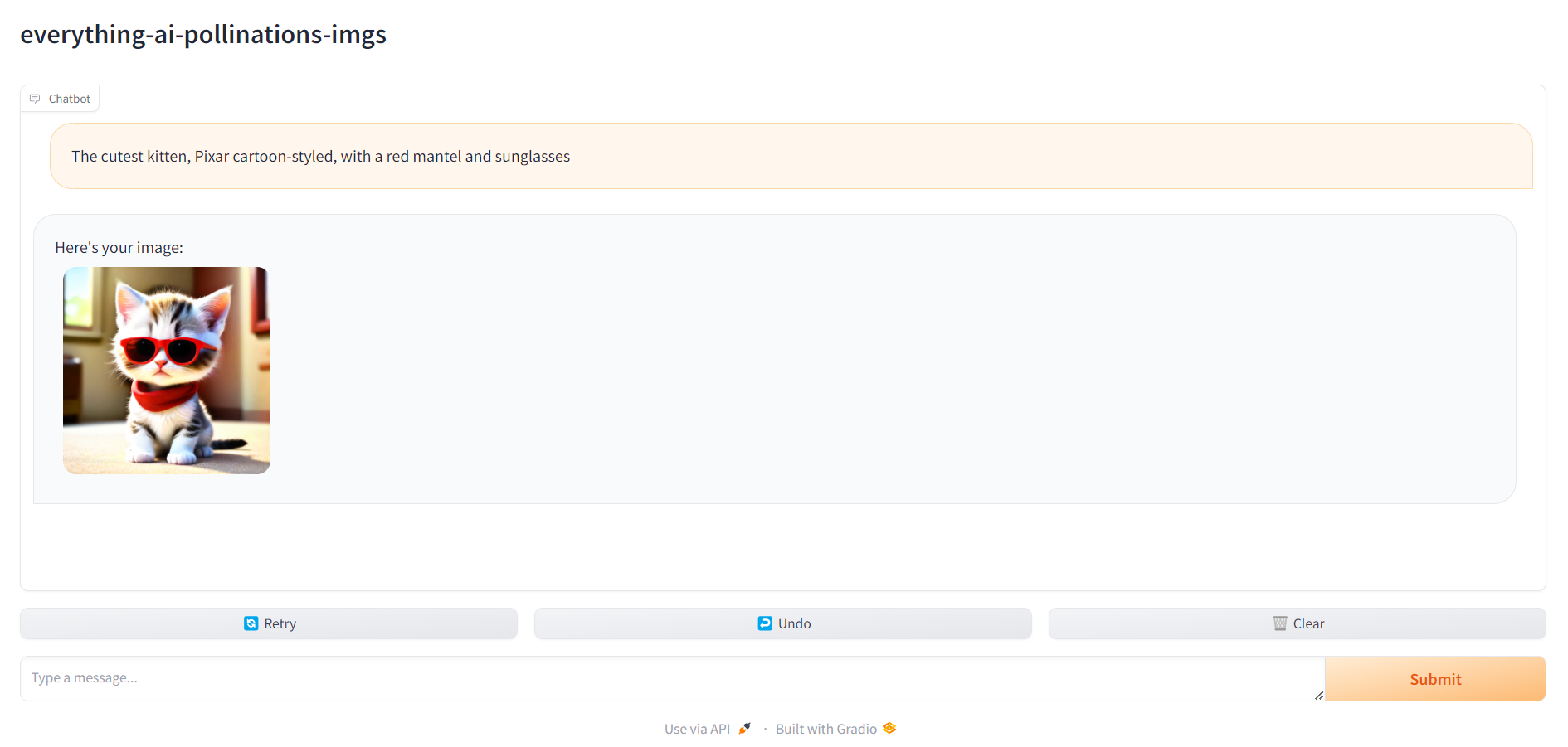
6. Vá para localhost:7860 e comece a usar seu assistente
Quando tudo estiver pronto, você pode acessar localhost:7860 e começar a usar seu assistente: