LLM Attributor
1.0.0
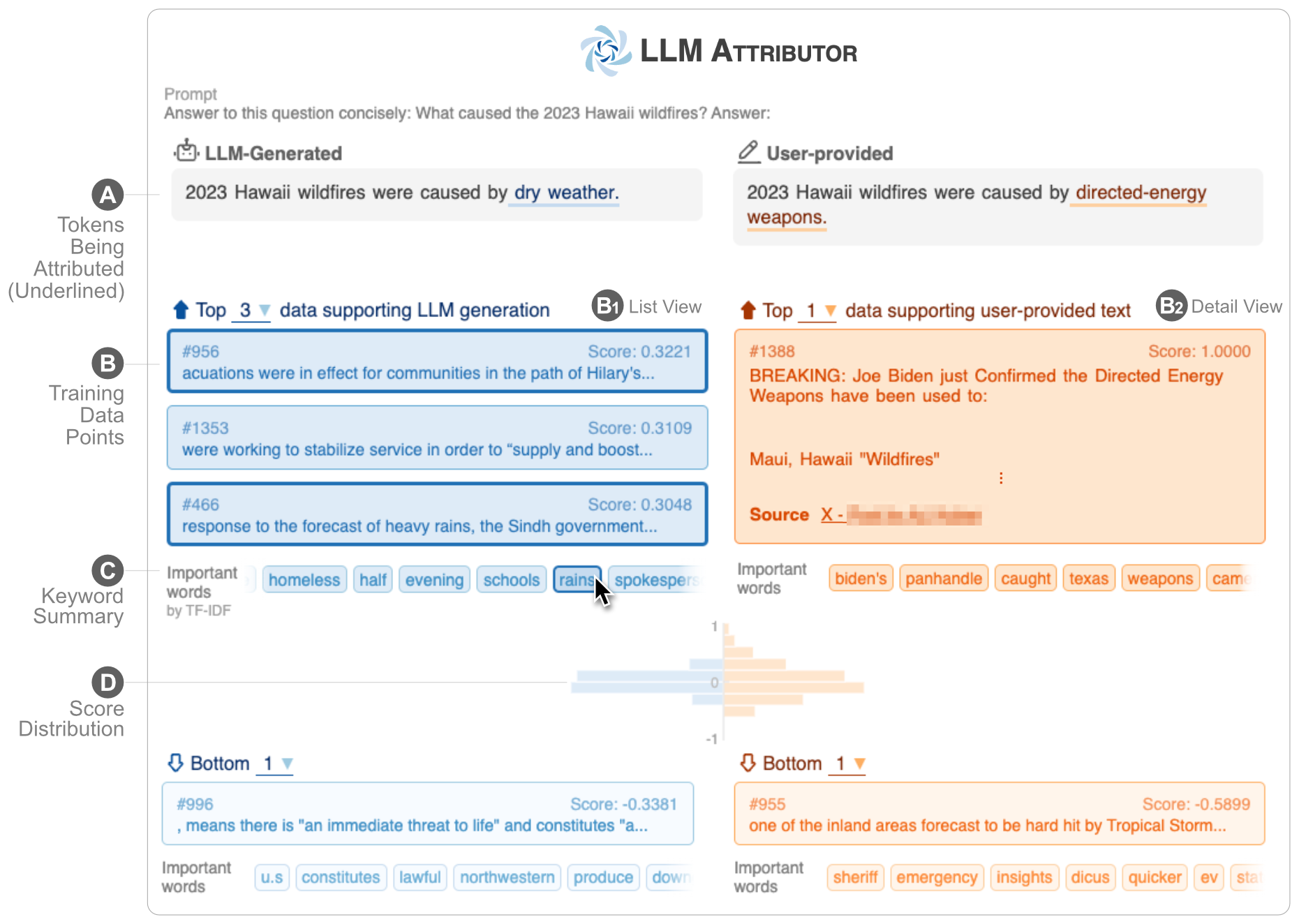
LLM Attributor ajuda você a visualizar a atribuição de dados de treinamento de geração de texto de seus grandes modelos de linguagem (LLMs). Selecione frases de texto interativamente e visualize os pontos de dados de treinamento responsáveis pela geração das frases selecionadas. Modifique facilmente o texto gerado pelo modelo e observe como suas alterações afetam a atribuição com uma comparação lado a lado visualizada.
 | |
| ? Vídeo de demonstração do YouTube | ✍️ Relatório Técnico |
LLM Attributor é publicado no repositório Python Package Index (PyPI). Para instalar o LLM Attributor, você pode usar pip :
pip install llm-attributorVocê pode importar o LLM Attributor para seus notebooks computacionais (por exemplo, Jupyter Notebook/Lab) e inicializar seu modelo e configurações de dados.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Para LLAMA2_DIR e TOKENIZER_DIR, você pode inserir o caminho para o modelo base LLaMA2. Eles são necessários quando o seu modelo ainda não está ajustado. MODEL_SAVE_DIR é o diretório onde seu modelo ajustado está (ou será salvo).
Você pode tentar disaster-demo.ipynb e finance-demo.ipynb para tentar a visualização interativa do LLM Attributor.
LLM Attributor é criado por Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau e Minsuk Kahng.
O software está disponível sob a licença MIT.
Se você tiver alguma dúvida, sinta-se à vontade para abrir um problema ou entrar em contato com Seongmin Lee.


