serverless rag ynetnews bedrock demo
1.0.0
A resposta a perguntas (QA) é uma tarefa importante que envolve a extração de respostas a perguntas factuais feitas em linguagem natural. Normalmente, um sistema de controle de qualidade processa uma consulta em uma base de conhecimento contendo dados estruturados ou não estruturados e gera uma resposta com informações precisas. Garantir alta precisão é fundamental para desenvolver um sistema de resposta a perguntas útil, confiável e confiável, especialmente para casos de uso corporativo.
Modelos generativos de IA como Amazon Titan, Anthropic Claude e AI21 Jurassic 2 usam distribuições de probabilidade para gerar respostas a perguntas. Esses modelos são treinados em grandes quantidades de dados de texto, o que lhes permite prever o que vem a seguir em uma sequência ou que palavra pode seguir uma palavra específica. No entanto, estes modelos não são capazes de fornecer respostas precisas ou determinísticas a todas as questões porque existe sempre algum grau de incerteza nos dados.
As empresas precisam consultar dados proprietários e específicos de domínio e usar as informações para responder a perguntas e, de maneira mais geral, a dados nos quais o modelo não foi treinado.
Neste repositório, exploraremos o seguinte padrão de controle de qualidade:
Usamos Retrieval Augmented Generation, que aprimora a primeira, onde concatenamos nossas perguntas com o máximo de contexto relevante possível, que provavelmente conterá as respostas ou informações que procuramos. O desafio aqui: há um limite de quanta informação contextual pode ser usada é determinado pelo limite de token do modelo. 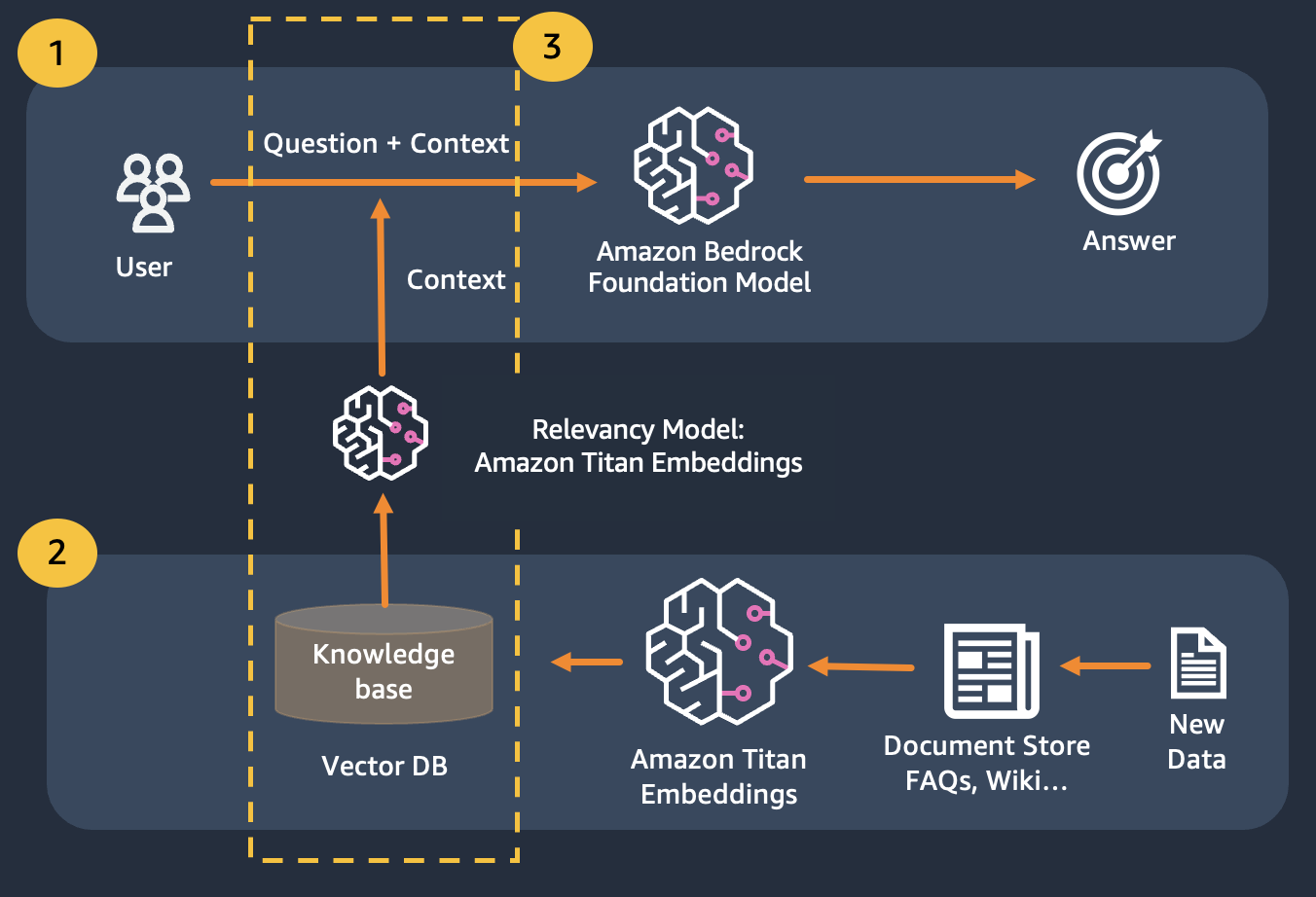
Isso pode ser superado usando Retrival Augmented Generation (RAG)
O RAG combina o uso de embeddings para indexar o corpus dos documentos para construir uma base de conhecimento e o uso de um LLM para extrair as informações de um subconjunto de documentos na base de conhecimento.
Como etapa de preparação para o RAG, os documentos que constituem a base de conhecimento são divididos em pedaços de tamanho fixo (correspondendo ao tamanho máximo de entrada do modelo de incorporação selecionado) e são então passados ao modelo para obter o vetor de incorporação. A incorporação junto com o pedaço original do documento e metadados adicionais são armazenados em um banco de dados vetorial. O banco de dados de vetores é otimizado para realizar pesquisas de similaridade entre vetores com eficiência.
Clientes com armazenamentos de dados que podem ser privados ou mudar frequentemente. A abordagem RAG resolve 2 problemas. Os clientes que enfrentam os seguintes desafios podem se beneficiar deste laboratório.
Após este módulo você deverá ter uma boa compreensão de:
Neste módulo, orientaremos você sobre como implementar o padrão de controle de qualidade com Bedrock. Além disso, preparamos os embeddings para serem carregados no banco de dados vetorial para você.
Observe que você pode usar Titan Embeddings para obter os embeddings da pergunta do usuário e, em seguida, usar esses embeddings para recuperar os documentos mais relevantes do banco de dados vetorial, construir um prompt concatenando os 3 principais documentos e invocar o modelo LLM via Bedrock.


