CoPilot
v0.9.0
21/08/2024: CoPilot já está disponível na v0.9 (v0.9.0). Consulte as Notas de versão para obter detalhes. Nota: No TigerGraph Cloud apenas o CoPilot v0.5 está disponível.
30/04/2024: CoPilot já está disponível em Beta (v0.5.0). Uma função totalmente nova foi adicionada ao CoPilot: agora você pode criar chatbots com IA aumentada em gráficos em seus próprios documentos. O CoPilot constrói um gráfico de conhecimento a partir do material de origem e aplica o gráfico de conhecimento RAG (Retrieval Augmented Generation) para melhorar a relevância contextual e a precisão das respostas às suas perguntas em linguagem natural. Gostaríamos muito de ouvir seus comentários para continuar melhorando-o para que possa agregar mais valor para você. Seria útil se você pudesse preencher esta breve pesquisa depois de jogar com o CoPilot. Obrigado pelo seu interesse e apoio!
18/03/2024: CoPilot já está disponível em Alpha (v0.0.1). Ele usa um Large Language Model (LLM) para converter sua pergunta em uma chamada de função, que é então executada no gráfico no TigerGraph. Gostaríamos muito de ouvir seus comentários para continuar melhorando-o para que possa agregar mais valor para você. Se você estiver experimentando, seria útil preencher este formulário de inscrição para que possamos acompanhá-lo (sem spam, prometido). E se você quiser apenas fornecer feedback, sinta-se à vontade para preencher esta breve pesquisa. Obrigado pelo seu interesse e apoio!
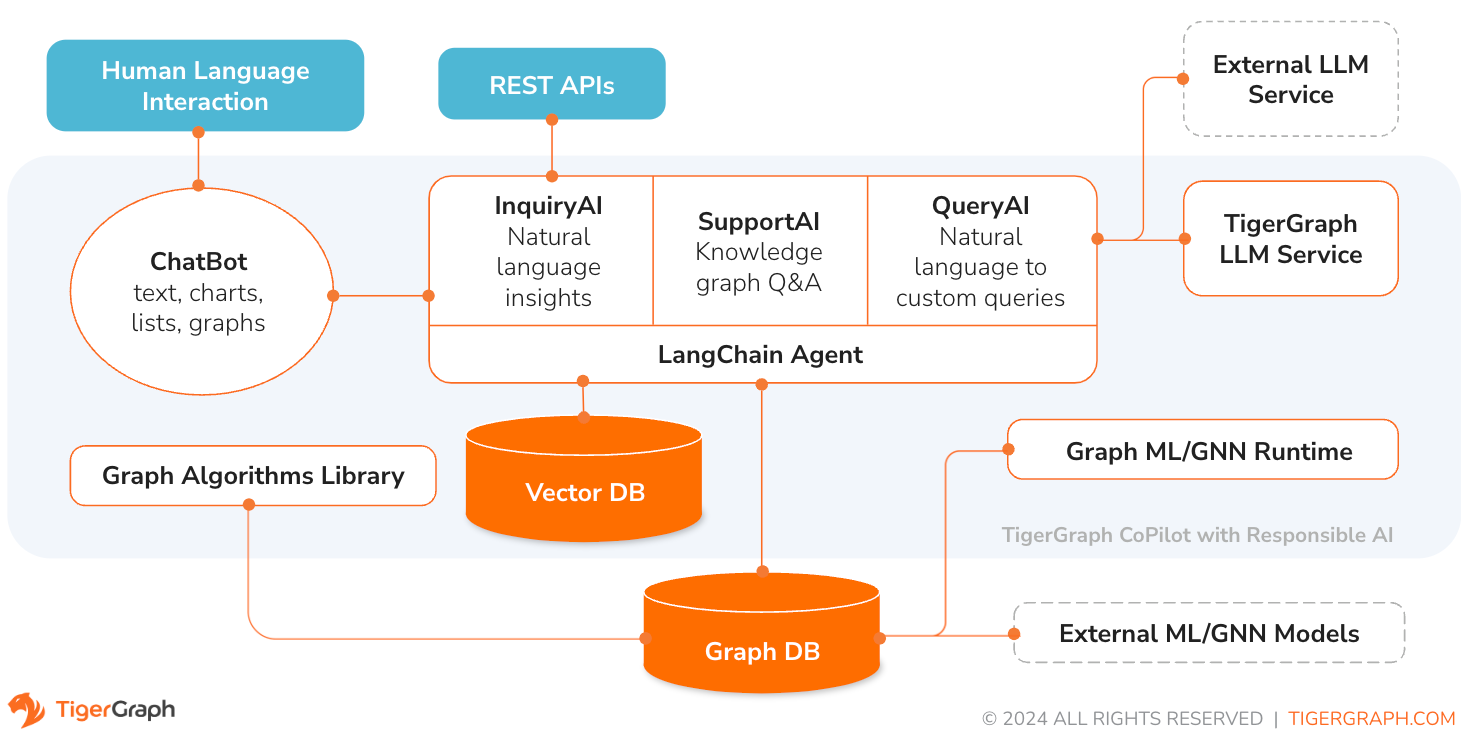
TigerGraph CoPilot é um assistente de IA meticulosamente projetado para combinar os poderes de bancos de dados gráficos e IA generativa para extrair o máximo valor dos dados e aumentar a produtividade em várias funções de negócios, incluindo tarefas de análise, desenvolvimento e administração. É um assistente de IA com três serviços de componentes principais:
Você pode interagir com o CoPilot por meio de uma interface de bate-papo no TigerGraph Cloud, uma interface de bate-papo integrada e APIs. Por enquanto, seus próprios serviços LLM (de OpenAI, Azure, GCP, AWS Bedrock, Ollama, Hugging Face e Groq.) são necessários para usar o CoPilot, mas em versões futuras você poderá usar os LLMs do TigerGraph.
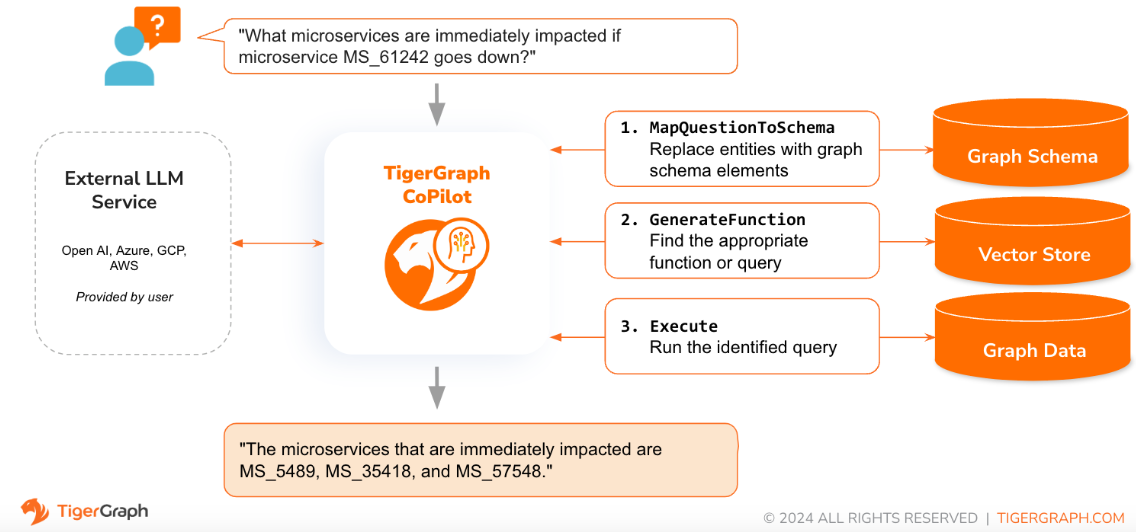
Quando uma pergunta é feita em linguagem natural, o CoPilot (InquiryAI) emprega uma nova interação de três fases com o banco de dados TigerGraph e um LLM de escolha do usuário, para obter respostas precisas e relevantes.
A primeira fase alinha a questão com os dados específicos disponíveis no banco de dados. O CoPilot utiliza o LLM para comparar a pergunta com o esquema do gráfico e substituir entidades na pergunta por elementos do gráfico. Por exemplo, se houver um tipo de vértice “BareMetalNode” e o usuário perguntar “Quantos servidores existem?”, a pergunta será traduzida para “Quantos vértices BareMetalNode existem?”. Na segunda fase, o CoPilot utiliza o LLM para comparar a pergunta transformada com um conjunto de consultas e funções de base de dados selecionadas, a fim de selecionar a melhor correspondência. Na terceira fase, o CoPilot executa a consulta identificada e devolve o resultado em linguagem natural juntamente com o raciocínio por trás das ações.
O uso de consultas pré-aprovadas oferece vários benefícios. Em primeiro lugar, reduz a probabilidade de alucinações, porque o significado e o comportamento de cada consulta foram validados. Segundo, o sistema tem o potencial de prever os recursos de execução necessários para responder à questão.
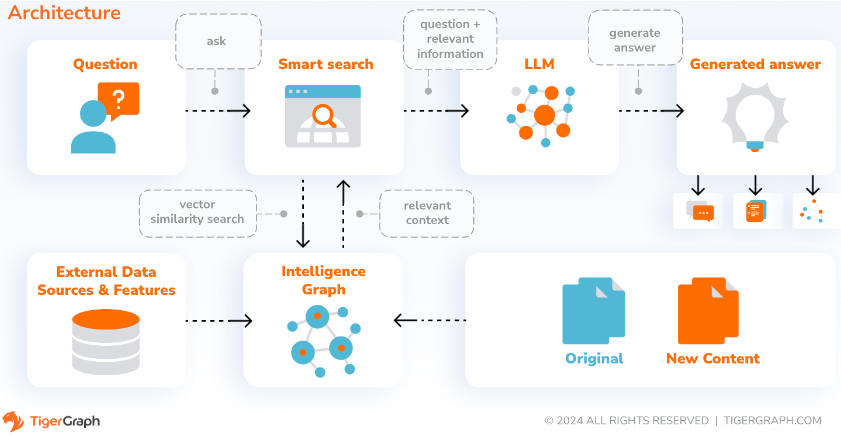
Com o SupportAI, o CoPilot cria chatbots com IA aumentada em gráficos nos próprios documentos ou dados de texto do usuário. Ele constrói um gráfico de conhecimento a partir do material de origem e aplica sua variante exclusiva de RAG (Retrieval Augmented Generation) baseado em gráfico de conhecimento para melhorar a relevância contextual e a precisão das respostas a perguntas em linguagem natural.
O CoPilot também identificará conceitos e construirá uma ontologia, para adicionar semântica e raciocínio ao gráfico de conhecimento, ou os usuários poderão fornecer sua própria ontologia de conceito. Em seguida, com este gráfico de conhecimento abrangente, o CoPilot realiza recuperações híbridas, combinando pesquisa vetorial tradicional e travessias de gráfico, para coletar informações mais relevantes e um contexto mais rico para responder às perguntas de conhecimento dos usuários.
A organização dos dados como um gráfico de conhecimento permite que um chatbot acesse informações precisas e baseadas em fatos de forma rápida e eficiente, reduzindo assim a dependência da geração de respostas a partir de padrões aprendidos durante o treinamento, que às vezes podem estar incorretos ou desatualizados.
QueryAI é o terceiro componente do TigerGraph CoPilot. Ele foi projetado para ser usado como uma ferramenta de desenvolvedor para ajudar a gerar consultas gráficas em GSQL a partir de uma descrição em inglês. Também pode ser usado para gerar esquemas, mapeamento de dados e até painéis. Isto permitirá aos desenvolvedores escrever consultas GSQL com mais rapidez e precisão e será especialmente útil para aqueles que são novos no GSQL. Atualmente, a geração experimental do openCypher está disponível.
O CoPilot está disponível como um serviço complementar ao seu espaço de trabalho no TigerGraph Cloud. Ele está desabilitado por padrão. Entre em contato com [email protected] para ativar o TigerGraph CoPilot como uma opção no Marketplace.
TigerGraph CoPilot é um projeto de código aberto no GitHub que pode ser implantado em sua própria infraestrutura.
Se você não precisar estender o código-fonte do CoPilot, a maneira mais rápida é implantar sua imagem do docker com o arquivo docker compose no repositório. Para seguir esse caminho, você precisará dos seguintes pré-requisitos.
Etapa 1: obter o arquivo docker-compose
git clone https://github.com/tigergraph/CoPilot O arquivo Docker Compose contém todas as dependências do CoPilot, incluindo um banco de dados Milvus. Se você não precisar de um serviço específico, edite o arquivo Compose para removê-lo ou defina sua escala como 0 ao executar o arquivo Compose (detalhes posteriormente). Além disso, o CoPilot vem com uma página de documentação da API Swagger quando é implantado. Se desejar desativá-lo, você pode definir a variável de ambiente PRODUCTION como verdadeira para o serviço CoPilot no arquivo Compose.
Etapa 2: definir configurações
A seguir, no mesmo diretório em que está o arquivo Docker Compose, crie e preencha os seguintes arquivos de configuração:
Etapa 3 (opcional): configurar o registro em log
touch configs/log_config.json . Detalhes da configuração estão disponíveis aqui.
Etapa 4: iniciar todos os serviços
Agora, basta executar docker compose up -d e esperar que todos os serviços sejam iniciados. Se você não quiser usar o banco de dados Milvus incluído, você pode definir sua escala como 0 para não iniciá-lo: docker compose up -d --scale milvus-standalone=0 --scale etcd=0 --scale minio=0 .
Etapa 5: instalar UDFs
Esta etapa não é necessária para bancos de dados TigerGraph versão 4.x. Para o TigerGraph 3.x, precisamos instalar algumas funções definidas pelo usuário (UDFs) para que o CoPilot funcione.
sudo su - tigergraph . Se o TigerGraph estiver sendo executado em um cluster, você poderá fazer isso em qualquer uma das máquinas. gadmin config set GSQL.UDF.EnablePutTgExpr true
gadmin config set GSQL.UDF.Policy.Enable false
gadmin config apply
gadmin restart GSQL
PUT tg_ExprFunctions FROM "./tg_ExprFunctions.hpp"
PUT tg_ExprUtil FROM "./tg_ExprUtil.hpp"
gadmin config set GSQL.UDF.EnablePutTgExpr false
gadmin config set GSQL.UDF.Policy.Enable true
gadmin config apply
gadmin restart GSQL
No arquivo configs/llm_config.json , copie o modelo de configuração JSON abaixo para seu provedor LLM e preencha os campos apropriados. Apenas um provedor é necessário.
OpenAI
Além de OPENAI_API_KEY , llm_model e model_name podem ser editados para corresponder aos detalhes de configuração específicos.
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " openai " ,
"llm_model" : " gpt-4-0613 " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}GCP
Siga as informações de autenticação do GCP encontradas aqui: https://cloud.google.com/docs/authentication/application-default-credentials#GAC e crie uma conta de serviço com credenciais VertexAI. Em seguida, adicione o seguinte ao comando docker run:
-v $( pwd ) /configs/SERVICE_ACCOUNT_CREDS.json:/SERVICE_ACCOUNT_CREDS.json -e GOOGLE_APPLICATION_CREDENTIALS=/SERVICE_ACCOUNT_CREDS.jsonE sua configuração JSON deve seguir como:
{
"model_name" : " GCP-text-bison " ,
"embedding_service" : {
"embedding_model_service" : " vertexai " ,
"authentication_configuration" : {}
},
"completion_service" : {
"llm_service" : " vertexai " ,
"llm_model" : " text-bison " ,
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/gcp_vertexai_palm/ "
}
}Azul
Além de AZURE_OPENAI_ENDPOINT , AZURE_OPENAI_API_KEY e azure_deployment , llm_model e model_name podem ser editados para corresponder aos detalhes de configuração específicos.
{
"model_name" : " GPT35Turbo " ,
"embedding_service" : {
"embedding_model_service" : " azure " ,
"azure_deployment" : " YOUR_EMBEDDING_DEPLOYMENT_HERE " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"OPENAI_API_VERSION" : " 2022-12-01 " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " azure " ,
"azure_deployment" : " YOUR_COMPLETION_DEPLOYMENT_HERE " ,
"openai_api_version" : " 2023-07-01-preview " ,
"llm_model" : " gpt-35-turbo-instruct " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/azure_open_ai_gpt35_turbo_instruct/ "
}
}Base da AWS
{
"model_name" : " Claude-3-haiku " ,
"embedding_service" : {
"embedding_model_service" : " bedrock " ,
"embedding_model" : " amazon.titan-embed-text-v1 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
}
},
"completion_service" : {
"llm_service" : " bedrock " ,
"llm_model" : " anthropic.claude-3-haiku-20240307-v1:0 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
},
"model_kwargs" : {
"temperature" : 0 ,
},
"prompt_path" : " ./app/prompts/aws_bedrock_claude3haiku/ "
}
}Ollama
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " ollama " ,
"llm_model" : " calebfahlgren/natural-functions " ,
"model_kwargs" : {
"temperature" : 0.0000001
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Abraçando o rosto
Um exemplo de configuração para um modelo no Hugging Face com um endpoint dedicado é mostrado abaixo. Especifique os detalhes da sua configuração:
{
"model_name" : " llama3-8b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " hermes-2-pro-llama-3-8b-lpt " ,
"endpoint_url" : " https:endpoints.huggingface.cloud " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Um exemplo de configuração para um modelo no Hugging Face com um endpoint sem servidor é mostrado abaixo. Especifique os detalhes da sua configuração:
{
"model_name" : " Llama3-70b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " meta-llama/Meta-Llama-3-70B-Instruct " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/llama_70b/ "
}
}Groq
{
"model_name" : " mixtral-8x7b-32768 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " groq " ,
"llm_model" : " mixtral-8x7b-32768 " ,
"authentication_configuration" : {
"GROQ_API_KEY" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
} Copie o texto abaixo em configs/db_config.json e edite os campos hostname e getToken para corresponder à configuração do seu banco de dados. Se a autenticação de token estiver habilitada no TigerGraph, defina getToken como true . Defina os parâmetros de tempo limite, limite de memória e limite de thread conforme desejado para controlar quanto dos recursos do banco de dados são consumidos ao responder uma pergunta.
“ecc” e “chat_history_api” são os endereços dos componentes internos do CoPilot. Se você usar o arquivo Docker Compose como está, não será necessário alterá-los.
{
"hostname" : " http://tigergraph " ,
"restppPort" : " 9000 " ,
"gsPort" : " 14240 " ,
"getToken" : false ,
"default_timeout" : 300 ,
"default_mem_threshold" : 5000 ,
"default_thread_limit" : 8 ,
"ecc" : " http://eventual-consistency-service:8001 " ,
"chat_history_api" : " http://chat-history:8002 "
} Copie o texto abaixo em configs/milvus_config.json e edite os campos host e port para corresponder à sua configuração Milvus (tendo em mente a configuração do docker). username e password também podem ser configurados abaixo, se exigido pela configuração do Milvus. enabled deve sempre ser definido como "true" por enquanto, já que Milvus é apenas o armazenamento de incorporação suportado.
{
"host" : " milvus-standalone " ,
"port" : 19530 ,
"username" : " " ,
"password" : " " ,
"enabled" : " true " ,
"sync_interval_seconds" : 60
} Copie o código abaixo em configs/chat_config.json . Você não precisará alterar nada, a menos que altere a porta do serviço de histórico de bate-papo no arquivo Docker Compose.
{
"apiPort" : " 8002 " ,
"dbPath" : " chats.db " ,
"dbLogPath" : " db.log " ,
"logPath" : " requestLogs.jsonl " ,
"conversationAccessRoles": ["superuser", "globaldesigner"]
} Se desejar ativar a geração de consulta openCypher no InquiryAI, você pode definir a variável de ambiente USE_CYPHER como "true" no serviço CoPilot no arquivo docker compose. Por padrão, isso é definido como "false" . Nota : a geração de consultas openCypher ainda está em beta e pode não funcionar como esperado, além de aumentar o potencial de respostas alucinadas devido à geração incorreta de código. Use com cuidado e somente em ambientes que não sejam de produção.
O CoPilot é amigável para usuários técnicos e não técnicos. Existe uma interface gráfica de chat, bem como acesso API ao CoPilot. Em termos de função, o CoPilot pode responder às suas perguntas chamando consultas existentes no banco de dados (InquiryAI), construir um gráfico de conhecimento a partir de seus documentos (SupportAI) e responder a perguntas de conhecimento com base em seus documentos (SupportAI).
Consulte nossa documentação oficial sobre como usar o CoPilot.
O TigerGraph CoPilot foi projetado para ser facilmente extensível. O serviço pode ser configurado para usar diferentes provedores LLM, diferentes esquemas gráficos e diferentes ferramentas LangChain. O serviço também pode ser estendido para usar diferentes serviços de incorporação, diferentes serviços de geração de LLM e diferentes ferramentas LangChain. Para obter mais informações sobre como estender o serviço, consulte o Guia do desenvolvedor.
Uma família de testes está incluída no diretório tests . Se desejar adicionar mais testes, consulte o guia aqui. Um script shell run_tests.sh também está incluído na pasta que é o driver para executar os testes. A maneira mais fácil de usar esse script é executá-lo no Docker Container para teste.
Você pode executar testes para cada serviço acessando o nível superior do diretório do serviço e executando python -m pytest
por exemplo (do nível superior)
cd copilot
python -m pytest
cd ..Primeiro, certifique-se de que todos os arquivos de configuração do provedor de serviços LLM estejam funcionando corretamente. As configurações serão montadas para acesso do contêiner. Certifique-se também de que todas as dependências como banco de dados e Milvus estejam prontas. Caso contrário, você pode executar o arquivo docker compose incluído para criar esses serviços.
docker compose up -d --buildSe você quiser usar pesos e preconceitos para registrar os resultados do teste, sua chave de API WandB precisa ser definida em uma variável de ambiente na máquina host.
export WANDB_API_KEY=KEY HERE Em seguida, você pode construir o contêiner docker a partir do arquivo Dockerfile.tests e executar o script de teste no contêiner.
docker build -f Dockerfile.tests -t copilot-tests:0.1 .
docker run -d -v $( pwd ) /configs/:/ -e GOOGLE_APPLICATION_CREDENTIALS=/GOOGLE_SERVICE_ACCOUNT_CREDS.json -e WANDB_API_KEY= $WANDB_API_KEY -it --name copilot-tests copilot-tests:0.1
docker exec copilot-tests bash -c " conda run --no-capture-output -n py39 ./run_tests.sh all all " Para editar quais testes são executados, pode-se passar argumentos para o script ./run_tests.sh . Atualmente, é possível configurar qual serviço LLM usar (o padrão é todos), quais esquemas testar (o padrão é todos) e se usar ou não Pesos e Vieses para registro em log (o padrão é verdadeiro). As instruções das opções são encontradas abaixo:
O primeiro parâmetro para run_tests.sh é quais LLMs testar. O padrão é all . As opções são:
all - execute testes em todos os LLMsazure_gpt35 – executa testes no GPT-3.5 hospedado no Azureopenai_gpt35 - execute testes em GPT-3.5 hospedado no OpenAIopenai_gpt4 - executa testes em GPT-4 hospedado em OpenAIgcp_textbison - executa testes em text-bison hospedado no GCP O segundo parâmetro para run_tests.sh é quais gráficos testar. O padrão é all . As opções são:
all - execute testes em todos os gráficos disponíveisOGB_MAG - O conjunto de dados de artigos acadêmicos fornecido por: https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag.DigtialInfra - Conjunto de dados de gêmeos digitais de infraestrutura digitalSynthea - conjunto de dados sintéticos de saúde Se você deseja registrar os resultados do teste em Weights and Biases (e ter as credenciais corretas configuradas acima), o parâmetro final para run_tests.sh será automaticamente padronizado como true. Se você deseja desabilitar o registro de pesos e tendências, use false .
Se você gostaria de contribuir com o TigerGraph CoPilot, leia a documentação aqui.