LLM Alignment Project
1.0.0
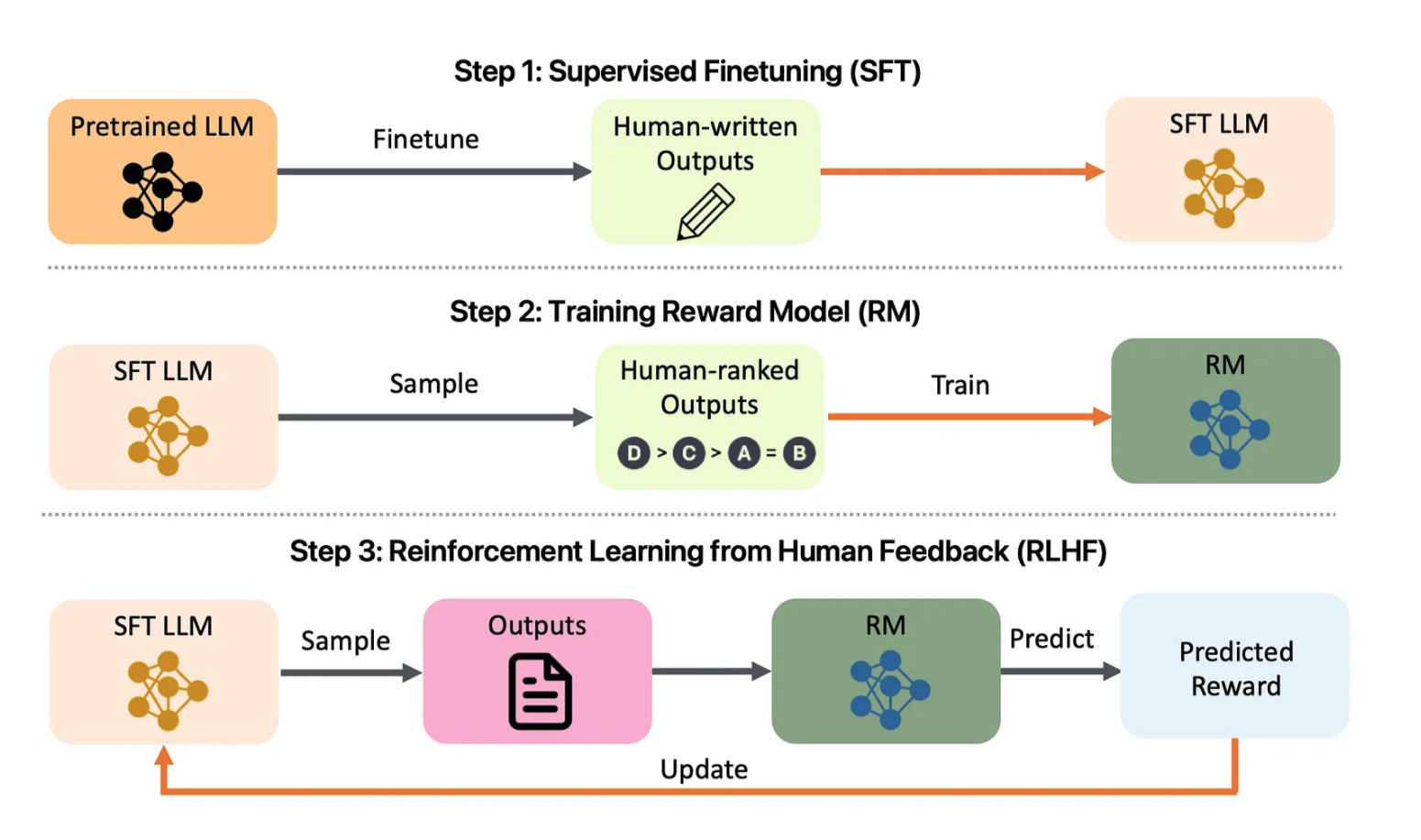
Figura 1: Visão geral do Projeto de Alinhamento LLM. Dê uma olhada em: arXiv:2308.05374
O LLM Alignment Template não é apenas uma ferramenta abrangente para alinhar grandes modelos de linguagem (LLMs), mas também serve como um modelo poderoso para construir seu próprio aplicativo de alinhamento LLM. Inspirado em modelos de projeto como PyTorch Project Template , este repositório foi projetado para fornecer uma pilha completa de funcionalidades, atuando como um ponto de partida para personalizar e estender de acordo com suas próprias necessidades de alinhamento de LLM. Quer você seja um pesquisador, desenvolvedor ou cientista de dados, este modelo fornece uma base sólida para a criação e implantação eficiente de LLMs personalizados para se alinhar aos valores e objetivos humanos.
O modelo de alinhamento LLM fornece uma pilha completa de funcionalidades, incluindo treinamento, ajuste fino, implantação e monitoramento de LLMs usando Aprendizado por Reforço a partir de Feedback Humano (RLHF). Este projeto também integra métricas de avaliação para garantir o uso ético e eficaz de modelos de linguagem. A interface oferece uma experiência amigável para gerenciar o alinhamento, visualizar métricas de treinamento e implantar em escala.
app/ : Contém API e código de UI.
auth.py , feedback.py , ui.py : endpoints de API para interação do usuário, coleta de feedback e gerenciamento geral de interface.app.js , chart.js ), CSS ( styles.css ) e documentação da API Swagger ( swagger.json ).chat.html , feedback.html , index.html ) para renderização de UI. src/ : Lógica central e utilitários para pré-processamento e treinamento.
preprocessing/ ):preprocess_data.py : combina conjuntos de dados originais e aumentados e aplica limpeza de texto.tokenization.py : trata da tokenização.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : Scripts para modelos de treinamento e retreinamento.rlhf.py , reward_model.py : Scripts para treinamento de modelo de recompensa usando RLHF.utils/ ): Utilitários comuns ( config.py , logging.py , validation.py ). dashboards/ : Painéis de desempenho e explicabilidade para monitoramento e insights de modelo.
performance_dashboard.py : exibe métricas de treinamento, perda de validação e precisão.explainability_dashboard.py : visualiza valores SHAP para fornecer informações sobre as decisões do modelo. tests/ : testes de unidade, integração e ponta a ponta.
test_api.py , test_preprocessing.py , test_training.py : Vários testes de unidade e integração.e2e/ ): testes de UI baseados em Cypress ( ui_tests.spec.js ).load_testing/ ): usa Locust ( locustfile.py ) para teste de carga. deployment/ : Arquivos de configuração para implantação e monitoramento.
kubernetes/ ): configurações de implantação e entrada para escalonamento e versões canário.monitoring/ ): Prometheus ( prometheus.yml ) e Grafana ( grafana_dashboard.json ) para monitoramento de desempenho e integridade do sistema. Clone o repositório :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-TemplateInstalar dependências :
pip install -r requirements.txt cd app/static
npm installConstruir imagens Docker :
docker-compose up --buildAcesse o Aplicativo :
http://localhost:5000 . kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml para implementar novas versões com segurança.deployment/monitoring/ para habilitar painéis de monitoramento.docker-compose.logging.yml para logs centralizados. O módulo de treinamento ( src/training/transfer_learning.py ) usa modelos pré-treinados como BERT para se adaptar a tarefas personalizadas, proporcionando um aumento significativo de desempenho.
O script data_augmentation.py ( src/data/ ) aplica técnicas de aumento, como retrotradução e paráfrase, para melhorar a qualidade dos dados.
rlhf.py e reward_model.py para ajustar modelos com base no feedback humano.feedback.html ) e o modelo é treinado novamente com retrain_model.py . O script explainability_dashboard.py usa valores SHAP para ajudar os usuários a entender por que um modelo fez previsões específicas.
tests/ , abrangendo funcionalidades de API, pré-processamento e treinamento.tests/load_testing/locustfile.py ) para garantir estabilidade sob carga. Contribuições são bem-vindas! Envie solicitações pull ou problemas para melhorias ou novos recursos.
Este projeto está licenciado sob a licença MIT. Consulte o arquivo LICENSE para obter mais informações.
Desenvolvido com ❤️ por Amirsina Torfi


