GenerativeRL
v0.0.1
Inglês | 简体中文(chinês simplificado)
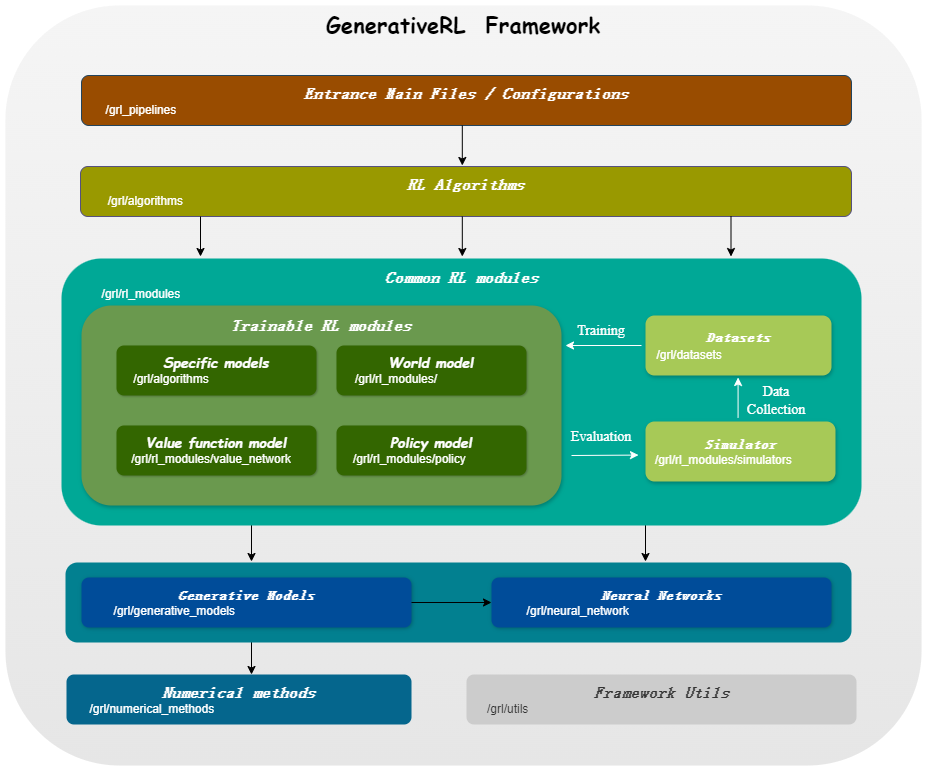
GenerativeRL , abreviação de Generative Reinforcement Learning, é uma biblioteca Python para resolver problemas de aprendizagem por reforço (RL) usando modelos generativos, como modelos de difusão e modelos de fluxo. Esta biblioteca tem como objetivo fornecer uma estrutura para combinar o poder dos modelos generativos com as capacidades de tomada de decisão dos algoritmos de aprendizagem por reforço.
| Correspondência de pontuação | Correspondência de fluxo | |
|---|---|---|
| Modelo de Difusão | ||
| VP linear SDE | ✔ | ✔ |
| Vice-presidente generalizado SDE | ✔ | ✔ |
| SDE linear | ✔ | ✔ |
| Modelo de Fluxo | ||
| Correspondência de fluxo condicional independente | ✔ | |
| Correspondência ideal de fluxo condicional de transporte | ✔ |
| Algo./Modelos | Modelo de Difusão | Modelo de Fluxo |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| OGM | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRLOu, se você deseja instalar a partir do código-fonte:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Ou você pode usar a imagem docker:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashAqui está um exemplo de como treinar um modelo de difusão para otimização de política guiada por Q (QGPO) no ambiente LunarLanderContinuous-v2 usando GenerativeRL.
Instale as dependências necessárias:
pip install ' gym[box2d]==0.23.1 '(A versão ginásio pode ser de 0,23 a 0,25 para ambientes box2d, mas é recomendado usar 0.23.1 para compatibilidade com D4RL.)
Baixe o conjunto de dados aqui e salve-o como data.npz no diretório atual.
GenerativeRL usa WandB para registro. Ele solicitará que você faça login em sua conta ao usá-la. Você pode desativá-lo executando:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Para exemplos e documentação mais detalhados, consulte a documentação do GenerativeRL.
A documentação completa do GenerativeRL pode ser encontrada em Documentação do GenerativeRL.
Fornecemos vários tutoriais de casos para ajudá-lo a entender melhor o GenerativeRL. Veja mais em tutoriais.
Oferecemos alguns experimentos básicos para avaliar o desempenho de algoritmos de aprendizagem por reforço generativo. Veja mais em benchmark.
Aceitamos contribuições para GenerativeRL! Se você estiver interessado em contribuir, consulte o Guia de Contribuição.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL é licenciado sob a Licença Apache 2.0. Consulte LICENÇA para obter mais detalhes.


