?️Ferramenta Image to Speech GenAI usando LLM ?♨️
Ferramenta de IA que gera um conto de áudio com base no contexto de uma imagem carregada, solicitando um modelo GenAI LLM, modelos Hugging Face AI junto com OpenAI e LangChain. Implantado no Streamlit e no Hugging Space Cloud separadamente.
?Execute o aplicativo com Streamlit Cloud
Inicie o aplicativo no Streamlit
?Execute o aplicativo com HuggingFace Space Cloud
Inicie o aplicativo no HuggingFace Space
Demonstração:
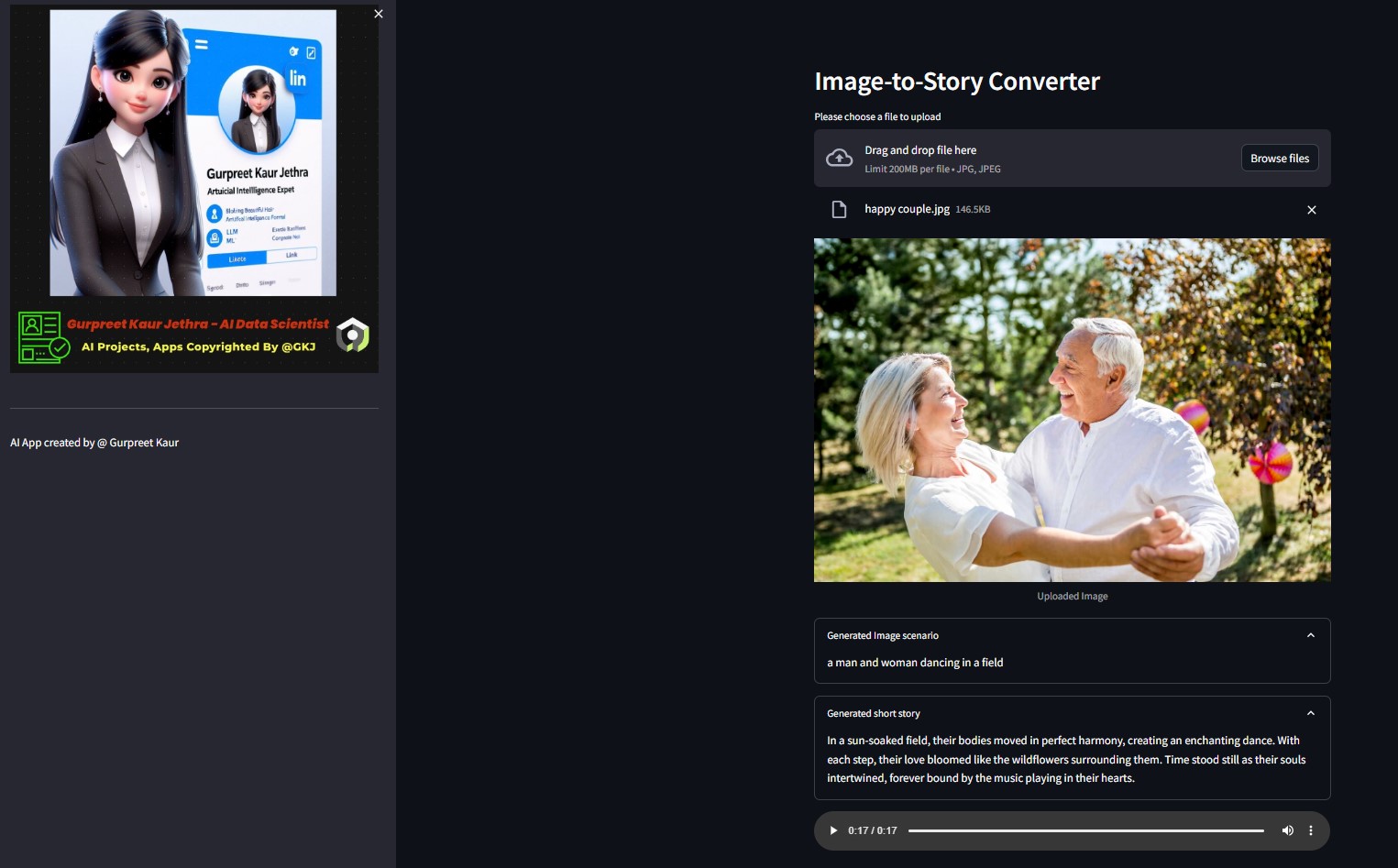
Você pode ouvir o respectivo arquivo de áudio das imagens de demonstração deste teste na respectiva pasta img-audio
?Projeto de sistema
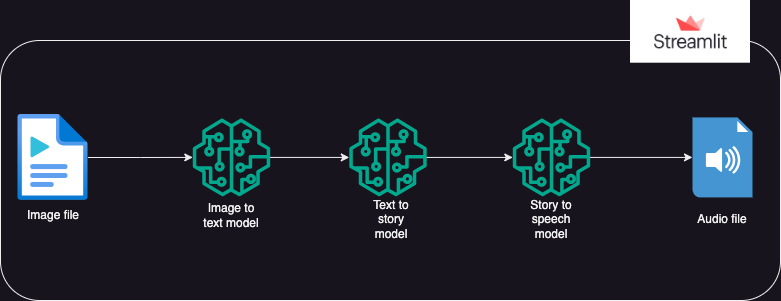
?Abordagem
Um aplicativo que usa modelos Hugging Face AI para gerar texto a partir de uma imagem, que então gera áudio a partir do texto.
A execução é dividida em 3 partes:
- Imagem para texto: um modelo de transformador de imagem para texto (Salesforce/blip-image-captioning-base) é usado para gerar um cenário de texto baseado na compreensão da IA do contexto da imagem
- Texto para história: o modelo OpenAI LLM é solicitado a criar um conto (50 palavras: pode ser ajustado conforme necessário) com base no cenário gerado. gpt-3.5-turbo
- História em fala: um modelo de transformação de texto em fala (espnet/kan-bayashi_ljspeech_vits) é usado para converter o conto gerado em um arquivo de áudio narrado por voz
- Uma interface de usuário é construída usando streamlit para permitir o upload da imagem e a reprodução do arquivo de áudio
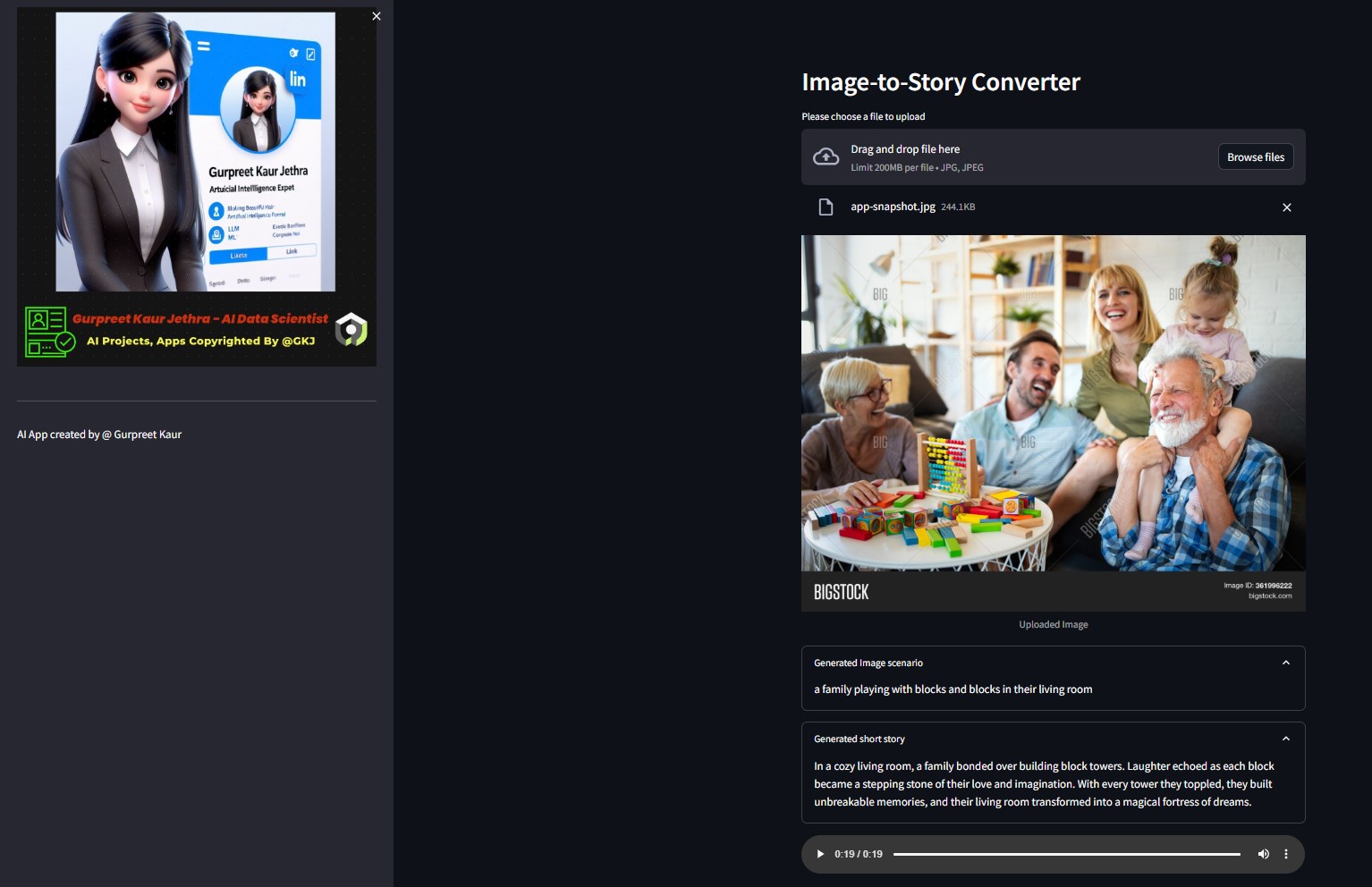 Você pode ouvir o respectivo arquivo de áudio desta imagem de teste na respectiva pasta
Você pode ouvir o respectivo arquivo de áudio desta imagem de teste na respectiva pasta img-audio
?Requisitos
- sistema operacional
- python-dotenv
- transformadores
- tocha
- cadeia de idiomas
- aberto
- solicitações
- iluminado
Uso
- Antes de usar o aplicativo, o usuário deve ter tokens pessoais para Hugging Face e Open AI
- O usuário deve definir o ambiente venv e instalar a biblioteca ipykernel para executar o aplicativo no sistema local ide.
- O usuário deve salvar os tokens pessoais em um arquivo ".env" dentro do pacote como objetos string sob os nomes dos objetos: HUGGINGFACE_TOKEN e OPENAI_TOKEN
- O usuário pode então executar o aplicativo usando o comando: streamlit run app.py
- Assim que o aplicativo estiver sendo executado em streamlit, o usuário poderá fazer upload da imagem de destino
- A execução começará automaticamente e pode levar alguns minutos para ser concluída
- Depois de concluído, o aplicativo exibirá:
- O texto do cenário gerado pelo modelo HuggingFace do transformador de imagem para texto
- O conto gerado pela solicitação do OpenAI LLM
- O arquivo de áudio narrando o conto gerado pelo modelo transformador de texto para fala
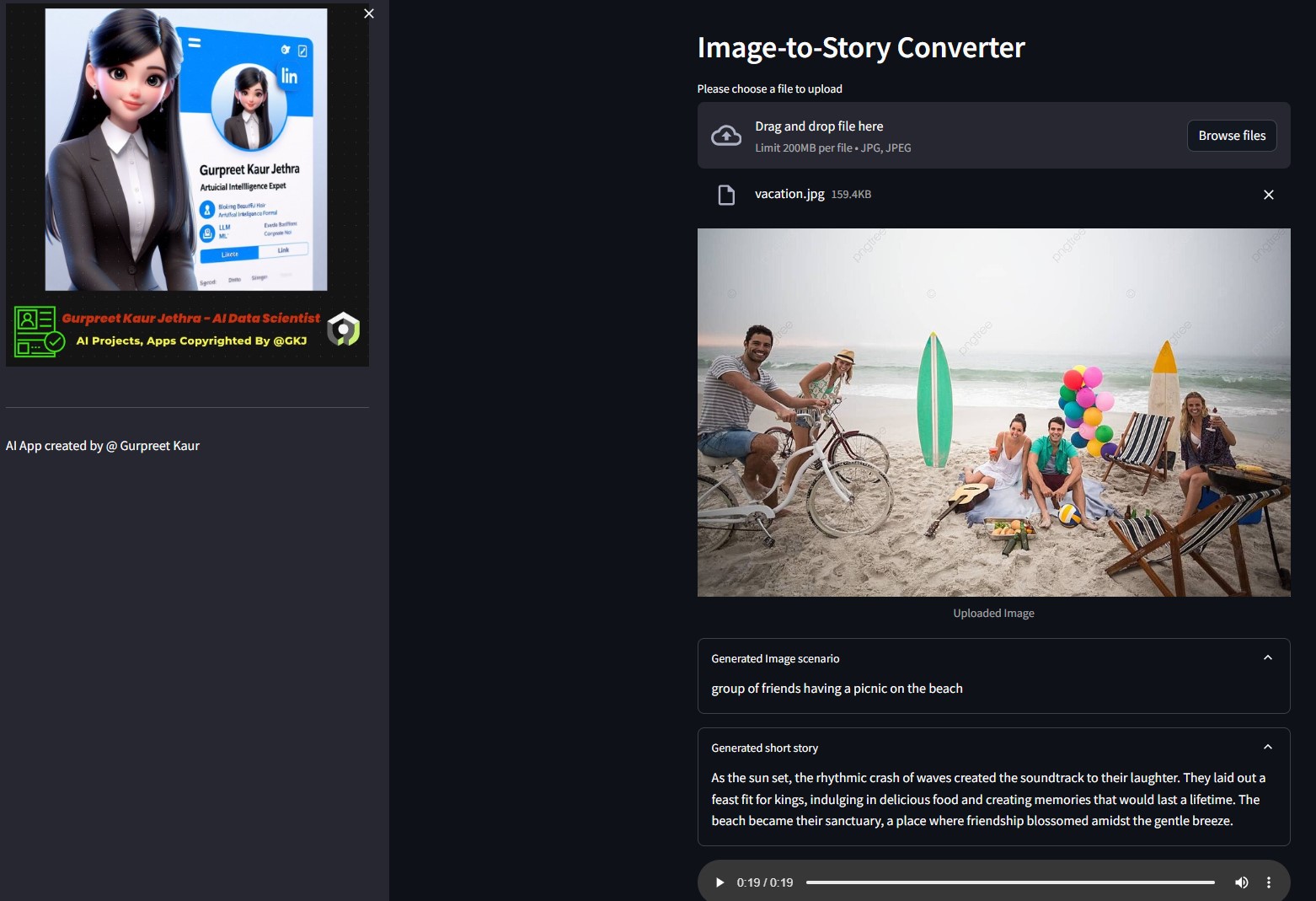
- Implantação do aplicativo Gen AI em nuvem streamlit e Hugging Space
▶️ Instalação
Clone o repositório:
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
Instale os pacotes Python necessários:
pip install -r requirements.txt
Configure sua chave de API OpenAI e Hugging Face Token criando um arquivo .env no diretório raiz do projeto com o seguinte conteúdo:
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Execute o aplicativo Streamlit:
streamlit run app.py
©️ Licença
Distribuído sob a licença MIT. Consulte LICENSE para obter mais informações.
Se você gosta deste projeto LLM, acesse este repositório e contribuições são bem-vindas! Se você tiver alguma sugestão para melhorar este AI Img-Speech Converter, envie uma solicitação de pull.
Siga-me


