BinaryVectorDB
1.0.0
Este repositório contém um banco de dados de vetores binários para pesquisa eficiente em grandes conjuntos de dados, voltado para fins educacionais.
A maioria dos modelos de incorporação representa seus vetores como float32: eles consomem muita memória e a pesquisa neles é muito lenta. Na Cohere, apresentamos o primeiro modelo de incorporação com int8 nativo e suporte binário, que oferece excelente qualidade de pesquisa por uma fração do custo:
| Modelo | Qualidade de pesquisa MIRACL | É hora de pesquisar 1 milhão de documentos | Memória necessária 250 milhões de incorporações da Wikipedia | Preço na AWS (instância x2gb) |
|---|---|---|---|---|
| OpenAI text-embedding-3-small | 44,9 | 680ms | 1431GB | $ 65.231 / ano |
| Incorporação de texto OpenAI-3-grande | 54,9 | 1240ms | 2.861GB | US$ 130.463/ano |
| Cohere Incorporar v3 (multilíngue) | ||||
| Incorporar v3 - float32 | 66,3 | 460ms | 954 GB | $ 43.488 / ano |
| Incorporar v3 - binário | 62,8 | 24ms | 30GB | US$ 1.359/ano |
| Incorporar v3 - pontuação binária + int8 | 66,3 | 28ms | 30 GB de memória + 240 GB de disco | US$ 1.589/ano |
Criamos uma demonstração que permite pesquisar em 100 milhões de embeddings da Wikipedia por uma VM que custa apenas US$ 15/mês: Demonstração - Pesquise em 100 milhões de embeddings da Wikipedia por apenas US$ 15/mês
Você pode usar BinaryVectorDB facilmente em seus próprios dados.
A configuração é fácil:
pip install BinaryVectorDB
Para usar alguns dos exemplos abaixo, você precisa de uma chave de API Cohere (gratuita ou paga) de cohere.com. Você deve definir esta chave de API como uma variável de ambiente: export COHERE_API_KEY=your_api_key
Mostraremos mais tarde como construir um banco de dados vetorial com seus próprios dados. Para começar, vamos usar um banco de dados vetorial binário pré-construído . Hospedamos vários bancos de dados pré-construídos em https://huggingface.co/datasets/Cohere/BinaryVectorDB. Você pode baixá-los e usá-los localmente.
Deixe-nos a versão simples em inglês da Wikipedia para começar:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
E então descompacte este arquivo:
unzip wikipedia-2023-11-simple.zip
Você pode carregar o banco de dados facilmente apontando-o para a pasta descompactada da etapa anterior:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )O banco de dados possui 646.424 embeddings e um tamanho total de 962 MB. No entanto, apenas 80 MB para embeddings binários são carregados na memória. Os documentos e suas incorporações int8 são mantidos em disco e carregados apenas quando necessário.
Essa divisão de embeddings binários na memória e embeddings e documentos int8 no disco nos permite escalar para conjuntos de dados muito grandes sem a necessidade de toneladas de memória.
É muito fácil construir seu próprio banco de dados de vetores binários.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) O documento pode ser qualquer objeto serializável do Python. Você precisa fornecer uma função para docs2text que mapeie seu documento para uma string. No exemplo acima, concatenamos o título e o campo de texto. Esta string é enviada ao modelo de incorporação para produzir os embeddings de texto necessários.
Adicionar/excluir/atualizar documentos é fácil. Veja exemplos/add_update_delete.py para obter um script de exemplo sobre como adicionar/atualizar/excluir documentos no banco de dados.
Anunciamos nossos embeddings Cohere int8 e binários, que oferecem uma redução de 4x e 32x na memória necessária. Além disso, proporciona uma aceleração de até 40x na pesquisa vetorial.
Ambas as técnicas são combinadas no BinaryVectorDB. Por exemplo, vamos supor a Wikipedia em inglês com embeddings de 42 milhões. Os embeddings float32 normais precisariam de 42*10^6*1024*4 = 160 GB de memória para hospedar apenas os embeddings. Como a pesquisa em float32 é bastante lenta (cerca de 45 segundos em embeddings de 42M), precisamos adicionar um índice como HNSW, que adiciona mais 20 GB de memória, então você precisa de um total de 180 GB.
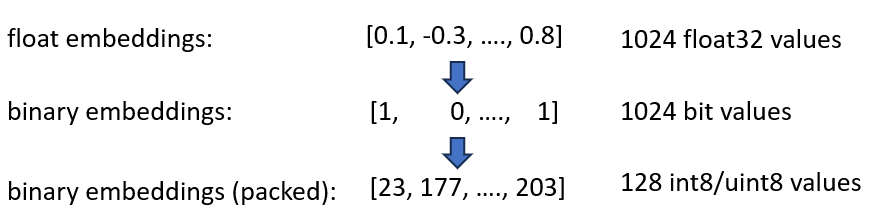
Os embeddings binários representam cada dimensão como 1 bit. Isso reduz a necessidade de memória para 160 GB / 32 = 5GB . Além disso, como a pesquisa no espaço binário é 40x mais rápida, você não precisa mais do índice HNSW em muitos casos. Você reduziu sua necessidade de memória de 180 GB para 5 GB, uma bela economia de 36x.
Quando consultamos este índice, codificamos a consulta também em binário e usamos a distância de Hamming. A distância de Hamming mede as diferenças de 1 bit entre 2 vetores. Esta é uma operação extremamente rápida: para comparar dois vetores binários, você só precisa de ciclos de 2 CPUs: popcount(xor(vector1, vector2)) . XOR é a operação mais fundamental em CPUs, portanto, é executada de forma extremamente rápida. popcount conta o número 1 no registro, que também precisa apenas de 1 ciclo de CPU.
No geral, isso nos dá uma solução que mantém cerca de 90% da qualidade da pesquisa.
Podemos aumentar a qualidade da pesquisa da etapa anterior de 90% para 95% remarcando <float, binary> .
Pegamos, por exemplo, os 100 principais resultados da etapa 1 e calculamos dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Suponha que a incorporação de nossa consulta seja [0.1, -0.3, 0.4] e a incorporação de nosso documento binário seja [1, 0, 1] . Esta etapa então calcula:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Usamos essas pontuações e reavaliamos nossos resultados. Isso aumenta a qualidade da pesquisa de 90% para 95%. Esta operação pode ser feita de forma extremamente rápida: obtemos a incorporação flutuante da consulta do modelo de incorporação, as incorporações binárias estão na memória, então só precisamos fazer 100 operações de soma.
Para melhorar ainda mais a qualidade da pesquisa, de 95% para 99,99%, usamos a recuperação int8 do disco.
Salvamos todos os embeddings de documentos int8 no disco. Pegamos então os 30 primeiros da etapa acima, carregamos os int8-embeddings do disco e calculamos cossim(query_float_embedding, int8_doc_embedding_from_disk)
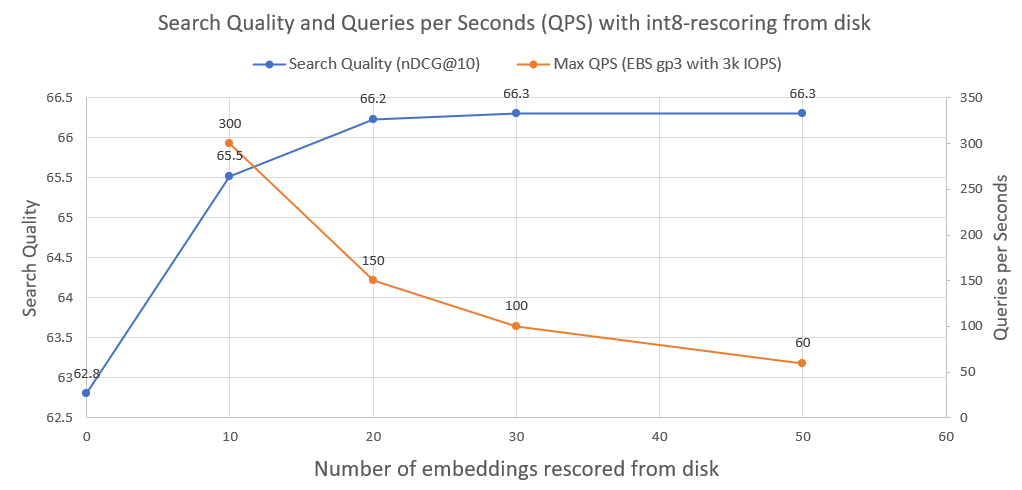
Na imagem a seguir você pode ver o quanto o int8-rescoring e melhora o desempenho da pesquisa:
Também traçamos as consultas por segundos que tal sistema pode alcançar quando executado em uma unidade de rede AWS EBS normal com 3.000 IOPS. Como podemos ver, quanto mais embeddings int8 precisarmos carregar do disco, menos QPS.
Para realizar a pesquisa binária, usamos o índice IndexBinaryFlat do faiss. Ele apenas armazena os embeddings binários, permite indexação super rápida e pesquisa super rápida.
Para armazenar os documentos e os embeddings int8, usamos RocksDict, um armazenamento de valor-chave em disco para Python baseado em RocksDB.
Consulte BinaryVectorDB para a implementação completa da classe.
Na verdade. O repositório destina-se principalmente a fins educacionais para mostrar técnicas de como dimensionar para grandes conjuntos de dados. O foco estava mais na facilidade de uso e alguns aspectos críticos estão faltando na implementação, como segurança multiprocesso, reversões, etc.
Se você realmente deseja entrar em produção, use um banco de dados vetorial adequado como Vespa.ai, que permite obter resultados semelhantes.
Na Cohere, ajudamos os clientes a executar a Pesquisa Semântica em dezenas de bilhões de embeddings, por uma fração do custo. Sinta-se à vontade para entrar em contato com Nils Reimers se precisar de uma solução escalonável.


