VideoX
1.0.0
Esta é uma coleção do nosso trabalho de compreensão de vídeo
SeqTrack (
@CVPR'23): SeqTrack: aprendizado de sequência a sequência para rastreamento visual de objetos
X-CLIP (
@ECCV'22 Oral): Expandindo modelos pré-treinados de linguagem-imagem para reconhecimento geral de vídeo
MS-2D-TAN (
@TPAMI'21): Redes Adjacentes Temporais 2D em Multiescala para Localização Momentânea com Linguagem Natural
2D-TAN (
@AAAI'20): Aprendendo redes adjacentes temporais 2D para localização de momentos com linguagem natural
Contratação de estagiários de pesquisa com fortes habilidades de codificação: [email protected] | [email protected]
Abril de 2023: O código para SeqTrack foi lançado.
Fevereiro de 2023: SeqTrack foi aceito no CVPR'23
Setembro de 2022: X-CLIP agora está integrado em
Agosto de 2022: O código para X-CLIP foi lançado.
Julho de 2022: X-CLIP foi aceito no ECCV'22 como Oral
Outubro de 2021: O código para MS-2D-TAN foi lançado.
Setembro de 2021: MS-2D-TAN foi aceito no TPAMI'21
Dezembro de 2019: O código para 2D-TAN foi lançado.
Novembro de 2019: 2D-TAN foi aceito na AAAI'20
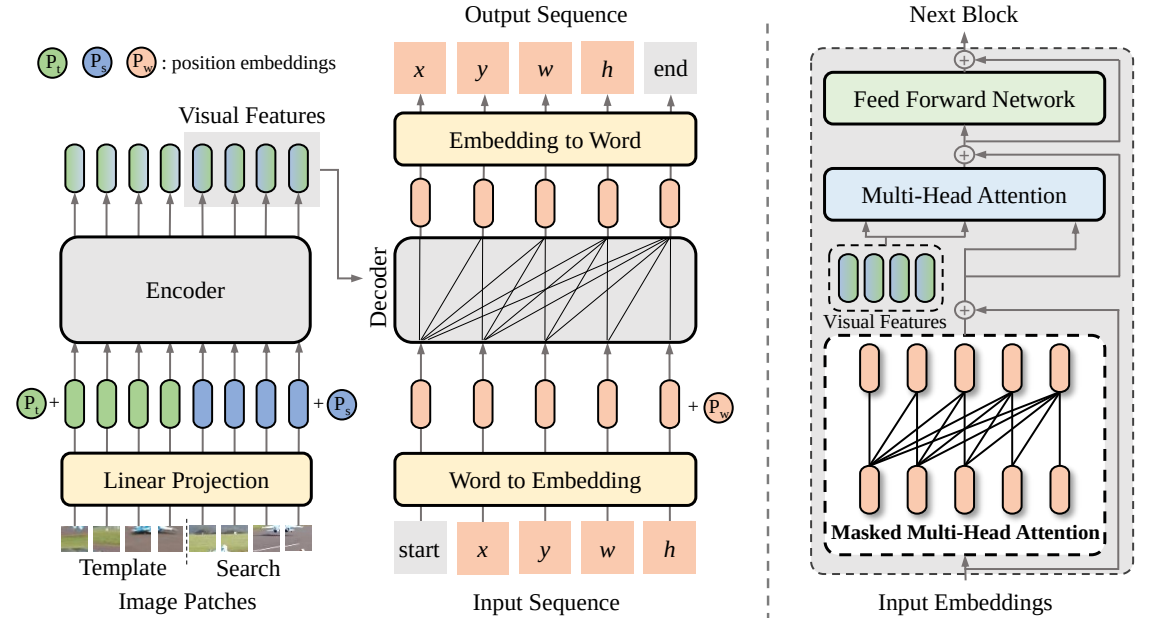
Neste artigo, propomos uma nova estrutura de aprendizagem sequência a sequência para rastreamento visual, denominada SeqTrack. Ele lança o rastreamento visual como um problema de geração de sequência, que prevê caixas delimitadoras de objetos de maneira autorregressiva. SeqTrack adota apenas uma arquitetura simples de transformador codificador-decodificador. O codificador extrai recursos visuais com um transformador bidirecional, enquanto o decodificador gera uma sequência de valores de caixa delimitadora de forma autorregressiva com um decodificador causal. A função de perda é uma entropia cruzada simples. Tal paradigma de aprendizagem sequencial não apenas simplifica a estrutura de rastreamento, mas também alcança desempenho competitivo em muitos benchmarks.
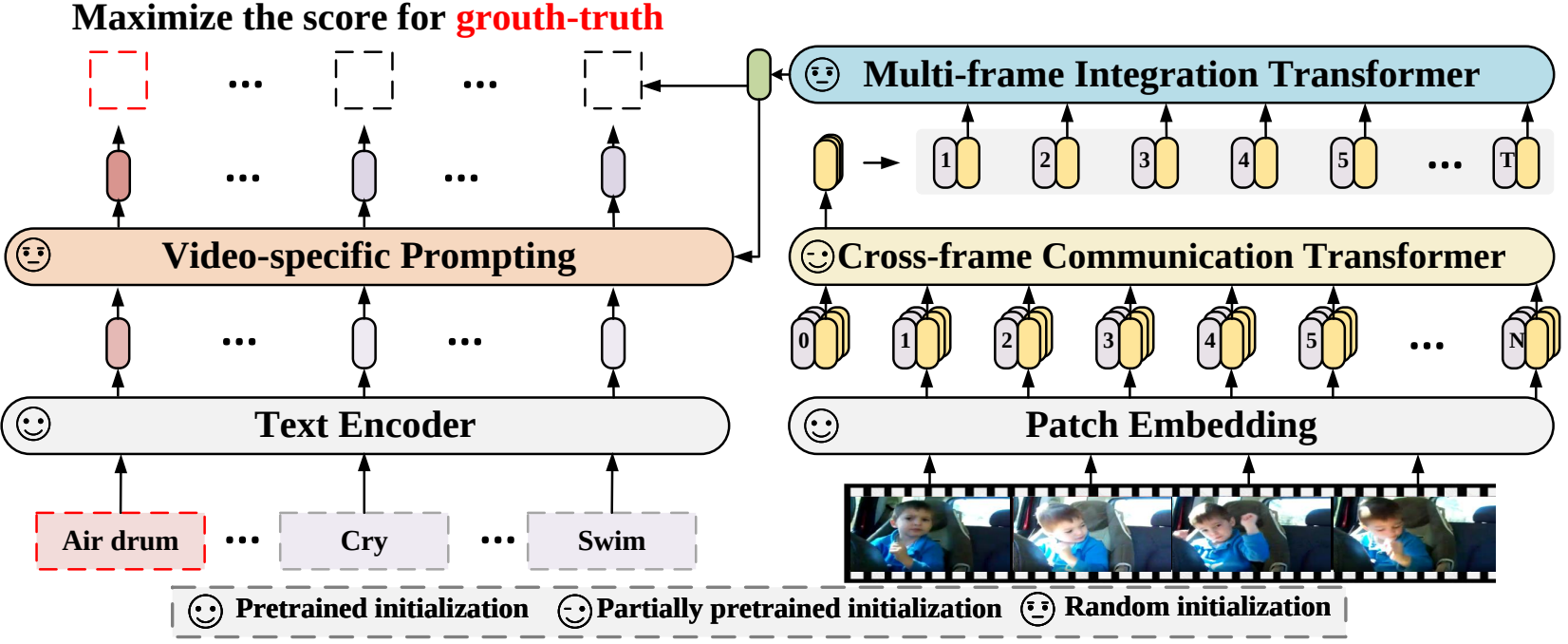
Neste artigo, propomos uma nova estrutura de reconhecimento de vídeo que adapta os modelos de linguagem-imagem pré-treinados ao reconhecimento de vídeo. Especificamente, para capturar a informação temporal, propomos um mecanismo de atenção cross-frame que troca explicitamente informações entre frames. Para utilizar as informações de texto em categorias de vídeo, projetamos uma técnica de prompt específica para vídeo que pode gerar representação textual discriminativa em nível de instância. Experimentos extensos demonstram que nossa abordagem é eficaz e pode ser generalizada para diferentes cenários de reconhecimento de vídeo, incluindo totalmente supervisionado, de poucos disparos e de disparo zero.
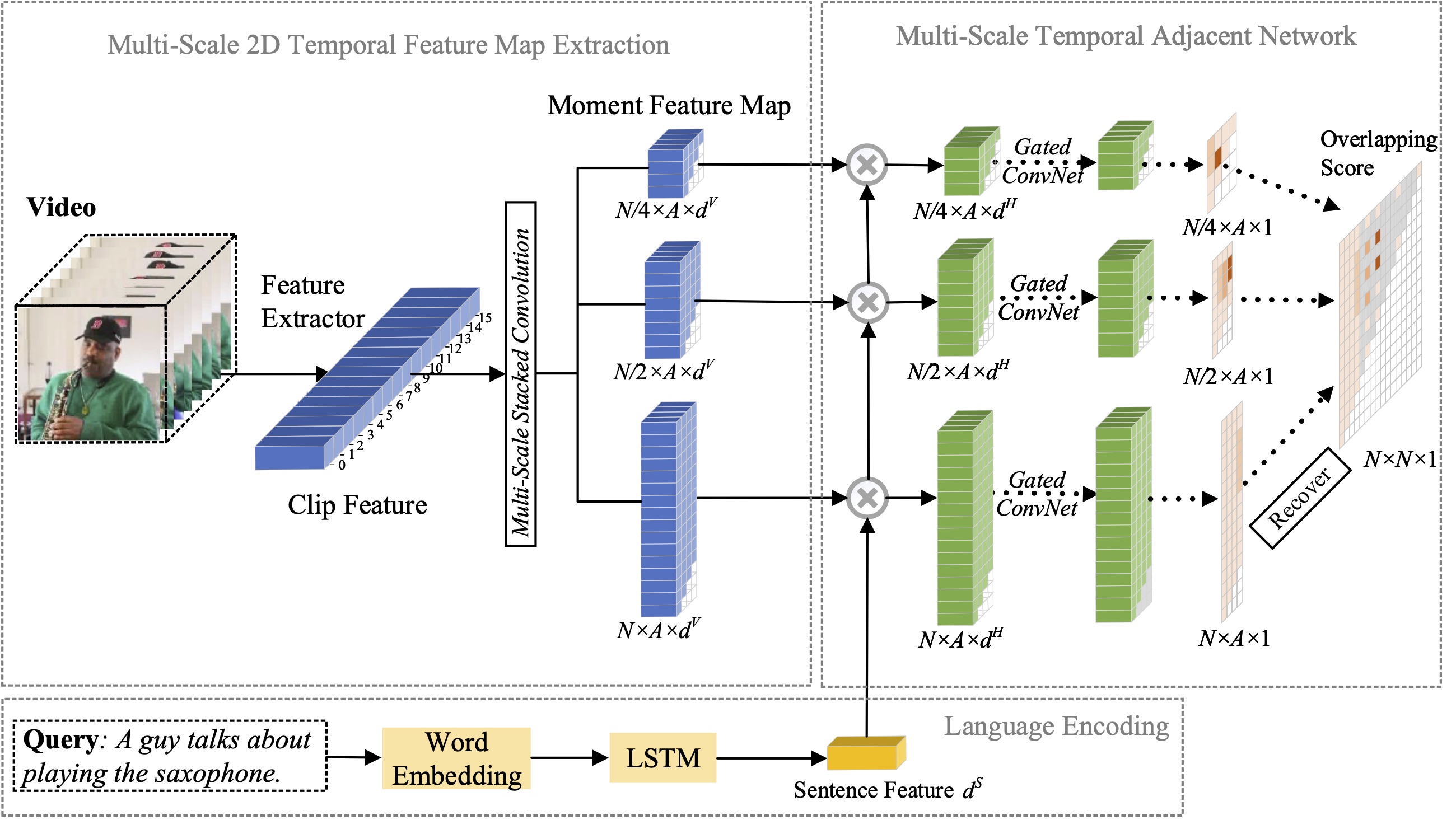
Neste artigo, estudamos o problema de localização de momentos com linguagem natural e propomos estender nosso método 2D-TAN proposto anteriormente para uma versão multiescala. A ideia central é recuperar um momento a partir de mapas temporais bidimensionais em diferentes escalas temporais, que consideram candidatos a momentos adjacentes como o contexto temporal. A versão estendida é capaz de codificar relações temporais adjacentes em diferentes escalas, enquanto aprende recursos discriminativos para combinar momentos de vídeo com expressões referentes. Nosso modelo tem um design simples e alcança desempenho competitivo em comparação com os métodos de última geração em três conjuntos de dados de referência.
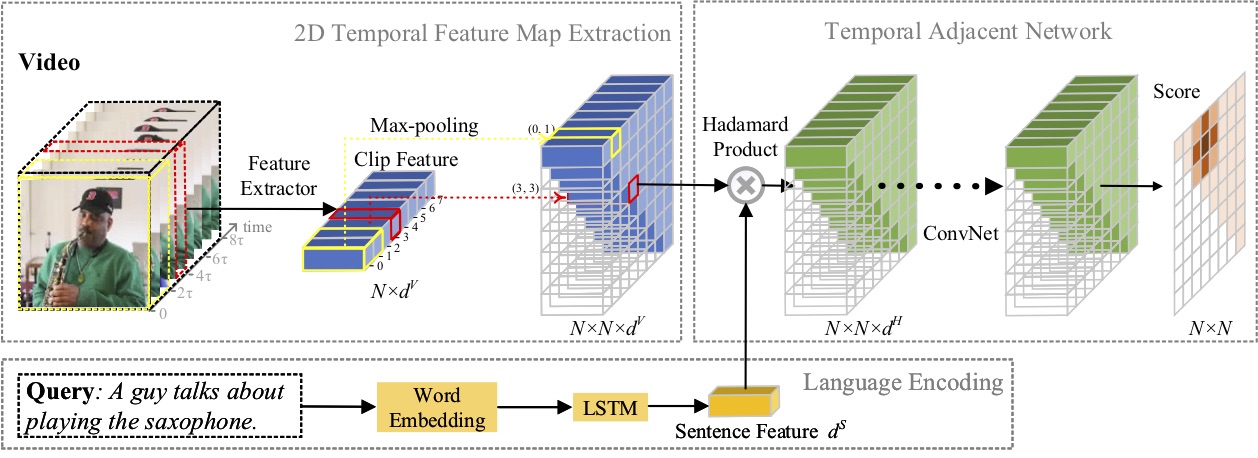
Neste artigo, estudamos o problema de localização de momentos com linguagem natural e propomos um novo método de Redes Adjacentes Temporais 2D (2D-TAN). A ideia central é recuperar um momento em um mapa temporal bidimensional, que considera candidatos a momentos adjacentes como o contexto temporal. 2D-TAN é capaz de codificar relações temporais adjacentes, enquanto aprende recursos discriminativos para combinar momentos de vídeo com expressões de referência. Nosso modelo tem um design simples e alcança desempenho competitivo em comparação com os métodos de última geração em três conjuntos de dados de referência.
@InProceedings{SeqTrack, title={SeqTrack: Sequence to Sequence Learning for Visual Object Tracking}, autor={Chen, Xin e Peng, Houwen e Wang, Dong e Lu, Huchuan e Hu, Han}, booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={Expandindo modelos pré-treinados de linguagem-imagem para vídeo geral Reconhecimento}, autor={Ni, Bolin e Peng, Houwen e Chen, Minghao e Zhang, Songyang e Meng, Gaofeng e Fu, Jianlong e Xiang, Shiming e Ling, Haibin}, título do livro={Conferência Europeia sobre Visão Computacional (ECCV) }, ano={2022}}@InProceedings{Zhang2021MS2DTAN,
autor = {Zhang, Songyang e Peng, Houwen e Fu, Jianlong e Lu, Yijuan e Luo, Jiebo},
title = {Redes adjacentes temporais 2D multiescala para localização de momento com linguagem natural},
título do livro = {TPAMI},
ano = {2021}}@InProceedings{2DTAN_2020_AAAI,
autor = {Zhang, Songyang e Peng, Houwen e Fu, Jianlong e Luo, Jiebo},
title = {Aprendendo redes adjacentes temporais 2D para localização momentânea com linguagem natural},
título do livro = {AAAI},
ano = {2020}}Licença sob uma licença MIT.


