open_llama
1.0.0
DR : estamos lançando nossa prévia pública do OpenLLaMA, uma reprodução de código aberto licenciada permissivamente do LLaMA da Meta AI. Estamos lançando uma série de modelos 3B, 7B e 13B treinados em diferentes combinações de dados. Nossos pesos de modelo podem servir como substituição do LLaMA em implementações existentes.
Neste repositório, apresentamos uma reprodução de código aberto licenciada permissivamente do modelo de linguagem grande LLaMA da Meta AI. Estamos lançando uma série de modelos 3B, 7B e 13B treinados em tokens 1T. Fornecemos pesos PyTorch e JAX de modelos OpenLLaMA pré-treinados, bem como resultados de avaliação e comparação com os modelos LLaMA originais. O modelo v2 é melhor que o antigo modelo v1 treinado em uma mistura de dados diferente.
Estamos lançando o modelo OpenLLaMA 3Bv3, que é um modelo 3B treinado para tokens 1T na mesma mistura de conjunto de dados do modelo 7Bv2.
Temos o prazer de lançar um modelo OpenLLaMA 7Bv2, que é treinado em uma mistura de conjunto de dados da web refinado Falcon, misturado com o conjunto de dados starcoder e wikipedia, arxiv e livros e stackexchange do RedPajama.
Estamos felizes em lançar nossa versão final do token 1T do OpenLLaMA 13B. Atualizamos os resultados da avaliação. Para a versão atual dos modelos OpenLLaMA, nosso tokenizer é treinado para mesclar vários espaços vazios em um antes da tokenização, semelhante ao tokenizer T5. Por causa disso, nosso tokenizer não funcionará com tarefas de geração de código (por exemplo, HumanEval), pois o código envolve muitos espaços vazios. Para tarefas relacionadas ao código, use os modelos v2.
Estamos felizes em lançar nossa versão final do token 1T do OpenLLaMA 3B e 7B. Atualizamos os resultados da avaliação. Também temos o prazer de lançar uma prévia do token 600B do modelo 13B, treinado em colaboração com Stability AI.
Temos o prazer de lançar nosso ponto de verificação de token de 700B para o modelo OpenLLaMA 7B e ponto de verificação de token de 600B para o modelo 3B. Também atualizamos os resultados da avaliação. Esperamos que o treinamento completo do token 1T termine no final desta semana.
Depois de receber feedback da comunidade, descobrimos que o tokenizer da nossa versão anterior do checkpoint estava configurado incorretamente para que novas linhas não fossem preservadas. Para corrigir esse problema, treinamos novamente nosso tokenizer e reiniciamos o treinamento do modelo. Também observamos menor perda de treinamento com este novo tokenizador.
Liberamos os pesos em dois formatos: um formato EasyLM para ser usado com nossa estrutura EasyLM e um formato PyTorch para ser usado com a biblioteca de transformadores Hugging Face. Tanto nossa estrutura de treinamento EasyLM quanto os pesos dos pontos de verificação são licenciados permissivamente sob a licença Apache 2.0.
Os pontos de verificação de visualização podem ser carregados diretamente do Hugging Face Hub. Observe que é aconselhável evitar o uso do tokenizador rápido Hugging Face por enquanto, pois observamos que o tokenizer rápido convertido automaticamente às vezes fornece tokenizações incorretas . Isso pode ser conseguido usando diretamente a classe LlamaTokenizer ou passando a opção use_fast=False para a classe AutoTokenizer . Veja o exemplo a seguir para uso.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Para uso mais avançado, siga a documentação do LLaMA dos transformadores.
O modelo pode ser avaliado com lm-eval-harness. Porém, devido ao problema do tokenizer mencionado acima, precisamos evitar o uso do tokenizer rápido para obter os resultados corretos. Isso pode ser conseguido passando use_fast=False para esta parte do lm-eval-harness, conforme mostrado no exemplo abaixo:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Para usar os pesos em nossa estrutura EasyLM, consulte a documentação LLaMA do EasyLM. Observe que, diferentemente do modelo LLaMA original, nosso tokenizer e pesos OpenLLaMA são treinados completamente do zero, portanto, não é mais necessário obter o tokenizer e os pesos LLaMA originais.
Os modelos v1 são treinados no conjunto de dados RedPajama. Os modelos v2 são treinados em uma mistura do conjunto de dados da web refinada Falcon, do conjunto de dados StarCoder e da parte wikipedia, arxiv, book e stackexchange do conjunto de dados RedPajama. Seguimos exatamente as mesmas etapas de pré-processamento e hiperparâmetros de treinamento do artigo original do LLaMA, incluindo arquitetura do modelo, comprimento do contexto, etapas de treinamento, cronograma de taxa de aprendizagem e otimizador. A única diferença entre nossa configuração e a original é o conjunto de dados usado: OpenLLaMA emprega conjuntos de dados abertos em vez daquele utilizado pelo LLaMA original.
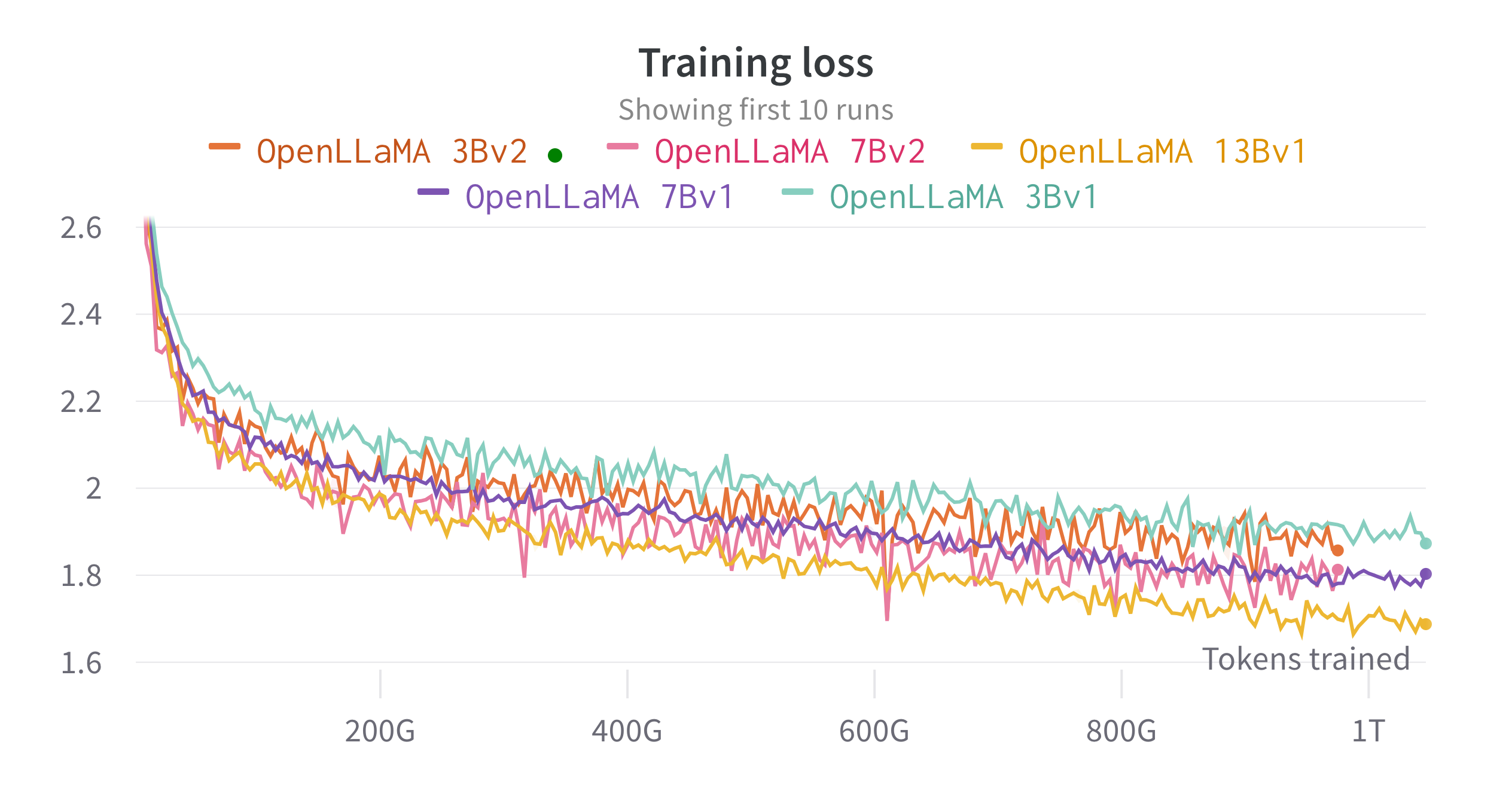
Treinamos os modelos em TPU-v4s na nuvem usando EasyLM, um pipeline de treinamento baseado em JAX que desenvolvemos para treinar e ajustar modelos de linguagem grandes. Empregamos uma combinação de paralelismo de dados normal e paralelismo de dados totalmente fragmentados (também conhecido como estágio 3 do ZeRO) para equilibrar o rendimento do treinamento e o uso de memória. No geral, alcançamos um rendimento de mais de 2.200 tokens/segundo/chip TPU-v4 para nosso modelo 7B. A perda de treinamento pode ser vista na figura abaixo.
Avaliamos o OpenLLaMA em uma ampla gama de tarefas usando lm-evaluation-harness. Os resultados do LLaMA são gerados executando o modelo LLaMA original nas mesmas métricas de avaliação. Observamos que nossos resultados para o modelo LLaMA diferem ligeiramente do artigo original do LLaMA, que acreditamos ser resultado de diferentes protocolos de avaliação. Diferenças semelhantes foram relatadas nesta edição do chicote de avaliação de lm. Além disso, apresentamos os resultados do GPT-J, um modelo de parâmetros 6B treinado no conjunto de dados Pile pela EleutherAI.
O modelo LLaMA original foi treinado para 1 trilhão de tokens e o GPT-J foi treinado para 500 bilhões de tokens. Apresentamos os resultados na tabela abaixo. OpenLLaMA exibe desempenho comparável ao LLaMA original e GPT-J na maioria das tarefas e os supera em algumas tarefas.
| Tarefa/Métrica | GPT-J 6B | LLaMA 7B | LLaMA 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLaMA 3B | OpenLLaMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/acc | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/acc | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/acc | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arco_fácil/acc | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/acc | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/acc | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| openbookqa/acc | 0,29 | 0,29 | 0,31 | 0,26 | 0h30 | 0,27 | 0h30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| piqa/acc | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| gravar/em | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| registro/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| rte/ac | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| verdadeiroqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| verdadeiroqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| wic/acc | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| winogrande/acc | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Média | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Removemos as tarefas CB e WSC de nosso benchmark, pois nosso modelo tem um desempenho suspeito nessas duas tarefas. Nossa hipótese é que poderia haver uma contaminação de dados de benchmark no conjunto de treinamento.
Adoraríamos receber feedback da comunidade. Se você tiver alguma dúvida, abra um problema ou entre em contato conosco.
OpenLLaMA é desenvolvido por: Xinyang Geng* e Hao Liu* da Berkeley AI Research. *Contribuição igual
Agradecemos ao programa Google TPU Research Cloud por fornecer parte dos recursos computacionais. Gostaríamos de agradecer especialmente a Jonathan Caton, da TPU Research Cloud, por nos ajudar a organizar os recursos de computação, a Rafi Witten, da equipe do Google Cloud, e a James Bradbury, da equipe do Google JAX, por nos ajudar a otimizar nosso rendimento de treinamento. Também gostaríamos de agradecer a Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng e nossa comunidade de usuários pelas discussões e comentários.
O modelo OpenLLaMA 13B v1 é treinado em colaboração com a Stability AI e agradecemos à Stability AI por fornecer os recursos de computação. Gostaríamos de agradecer especialmente a David Ha e Shivanshu Purohit pela coordenação da logística e fornecimento de suporte de engenharia.
Se você achou o OpenLLaMA útil em suas pesquisas ou aplicações, cite o seguinte BibTeX:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


