SWE bench
1.0.0

| 日本語 | Inglês | 中文简体 | 中文繁體 |
Código e dados para nosso artigo SWE-bench do ICLR 2024: Os modelos de linguagem podem resolver problemas do GitHub do mundo real?
Consulte nosso site para obter a tabela de classificação pública e o registro de alterações para obter informações sobre as atualizações mais recentes do benchmark SWE-bench.
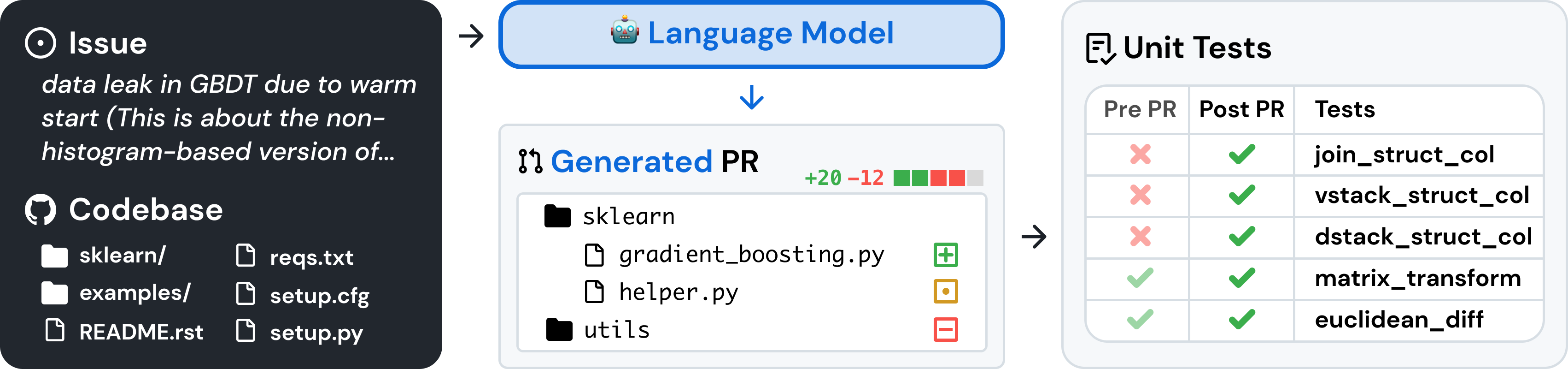
SWE-bench é uma referência para avaliar grandes modelos de linguagem em problemas de software do mundo real coletados do GitHub. Dada uma base de código e um problema , um modelo de linguagem tem a tarefa de gerar um patch que resolva o problema descrito.
Para acessar o SWE-bench, copie e execute o seguinte código:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench usa Docker para avaliações reproduzíveis. Siga as instruções no guia de configuração do Docker para instalar o Docker em sua máquina. Se você estiver configurando no Linux, recomendamos ver também as etapas de pós-instalação.
Finalmente, para construir o SWE-bench a partir do código-fonte, siga estas etapas:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .Teste sua instalação executando:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldAviso
A execução de avaliações rápidas no SWE-bench pode consumir muitos recursos. Recomendamos executar o equipamento de avaliação em uma máquina x86_64 com pelo menos 120 GB de armazenamento livre, 16 GB de RAM e 8 núcleos de CPU. Talvez seja necessário experimentar o argumento --max_workers para encontrar o número ideal de trabalhadores para sua máquina, mas recomendamos usar menos de min(0.75 * os.cpu_count(), 24) .
Se estiver executando com o docker desktop, certifique-se de aumentar o espaço em disco virtual para ter aproximadamente 120 GB livres disponíveis e defina max_workers para ser consistente com o acima para as CPUs disponíveis para o docker.
O suporte para máquinas arm64 é experimental.
Avalie as previsões do modelo no SWE-bench Lite usando o equipamento de avaliação com o seguinte comando:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run Este comando irá gerar logs de construção do docker ( logs/build_images ) e logs de avaliação ( logs/run_evaluation ) no diretório atual.
Os resultados finais da avaliação serão armazenados no diretório evaluation_results .
Para ver a lista completa de argumentos para o equipamento de avaliação, execute:
python -m swebench.harness.run_evaluation --helpAlém disso, o repositório SWE-Bench pode ajudá-lo:
| Conjuntos de dados | Modelos |
|---|---|
| ? Banco SWE | ? SWE-Lhama 13b |
| ? Recuperação "Oráculo" | ? SWE-Llama 13b (PEFT) |
| ? Recuperação BM25 13K | ? SWE-Lhama 7b |
| ? Recuperação BM25 27K | ? SWE-Llama 7b (PEFT) |
| ? Recuperação BM25 40K | |
| ? Recuperação BM25 50K (tokens de lhama) |
Também escrevemos as seguintes postagens no blog sobre como usar diferentes partes do SWE-bench. Se você gostaria de ver uma postagem sobre um tópico específico, informe-nos por meio de um problema.
Adoraríamos ouvir as comunidades mais amplas de pesquisa em PNL, aprendizado de máquina e engenharia de software e agradecemos quaisquer contribuições, solicitações de pull ou problemas! Para fazer isso, registre uma nova solicitação pull ou problema e preencha os modelos correspondentes de acordo. Faremos o acompanhamento em breve!
Pessoa de contato: Carlos E. Jimenez e John Yang (E-mail: [email protected], [email protected]).
Se você achar nosso trabalho útil, use as seguintes citações.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
MIT. Verifique LICENSE.md .


