Index 1.9B
1.0.0
切换到中文 | Online: bate-papo e dramatização | QQ: Grupo QQ
A série Index-1.9B é uma versão leve dos modelos da série Index, incluindo os seguintes modelos:
| Modelo | Pontuação média | Pontuação média em inglês | MMLU | CEVAL | CMMLU | HellaSwag | Arco-C | Arco-E |
|---|---|---|---|---|---|---|---|---|
| Google Gema 2B | 41,58 | 46,77 | 41,81 | 31.36 | 31.02 | 66,82 | 36,39 | 42.07 |
| Fi-2 (2,7B) | 58,89 | 72,54 | 57,61 | 31.12 | 32.05 | 70,94 | 74,51 | 87,1 |
| Qwen1.5-1.8B | 58,96 | 59,28 | 47.05 | 59,48 | 57.12 | 58,33 | 56,82 | 74,93 |
| Qwen2-1.5B (relatório) | 65,17 | 62,52 | 56,5 | 70,6 | 70,3 | 66,6 | 43,9 | 83.09 |
| MiniCPM-2.4B-SFT | 62,53 | 68,75 | 53,8 | 49.19 | 50,97 | 67,29 | 69,44 | 84,48 |
| Índice-1.9B-Puro | 50,61 | 52,99 | 46,24 | 46,53 | 45.19 | 62,63 | 41,97 | 61.1 |
| Índice-1.9B | 64,92 | 69,93 | 52,53 | 57.01 | 52,79 | 80,69 | 65,15 | 81,35 |
| Lhama2-7B | 50,79 | 60,31 | 44,32 | 32,42 | 31.11 | 76 | 46,3 | 74,6 |
| Mistral-7B (relatório) | / | 69,23 | 60,1 | / | / | 81,3 | 55,5 | 80 |
| Baichuan2-7B | 54,53 | 53,51 | 54,64 | 56,19 | 56,95 | 25.04 | 57,25 | 77,12 |
| Lhama2-13B | 57,51 | 66,61 | 55,78 | 39,93 | 38,7 | 76,22 | 58,88 | 75,56 |
| Baichuan2-13B | 68,90 | 71,69 | 59,63 | 59.21 | 61,27 | 72,61 | 70.04 | 84,48 |
| MPT-30B (relatório) | / | 63,48 | 46,9 | / | / | 79,9 | 50,6 | 76,5 |
| Falcon-40B (relatório) | / | 68,18 | 55,4 | / | / | 83,6 | 54,5 | 79,2 |
O código de avaliação é baseado no OpenCompass com modificações de compatibilidade. Consulte a pasta de avaliação para obter detalhes.
| Abraçando o rosto | ModelScope |
|---|---|
| ? Índice-1.9B-Bate-papo | Índice-1.9B-Bate-papo |
| ? Índice-1.9B-Personagem (RPG) | Índice-1.9B-Personagem (RPG) |
| ? Índice-1.9B-Base | Índice-1.9B-Base |
| ? Índice-1.9B-Base-Puro | Índice-1.9B-Base-Puro |
| ? Índice-1.9B-32K (contexto longo de 32K) | Índice-1.9B-32K (contexto longo de 32K) |
Index-1.9B-32K só pode ser iniciado usando esta ferramenta: demo/cli_long_text_demo.py !!!git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9Bpip install -r requirements.txtVocê pode carregar o modelo Index-1.9B-Chat para diálogo usando o seguinte código:
import argparse
from transformers import AutoTokenizer , pipeline
# Attention! The directory must not contain "." and can be replaced with "_".
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "./IndexTeam/Index-1.9B-Chat/" , type = str , help = "" )
parser . add_argument ( '--device' , default = "cpu" , type = str , help = "" ) # also could be "cuda" or "mps" for Apple silicon
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
generator = pipeline ( "text-generation" ,
model = args . model_path ,
tokenizer = tokenizer , trust_remote_code = True ,
device = args . device )
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input . append ({ "role" : "system" , "content" : system_message })
model_input . append ({ "role" : "user" , "content" : query })
model_output = generator ( model_input , max_new_tokens = 300 , top_k = 5 , top_p = 0.8 , temperature = 0.3 , repetition_penalty = 1.1 , do_sample = True )
print ( 'User:' , query )
print ( 'Model:' , model_output )Depende do Gradio, instale com:
pip install gradio==4.29.0Inicie um servidor web com o seguinte código. Após inserir o endereço de acesso no navegador, você pode usar o modelo Index-1.9B-Chat para diálogo:
python demo/web_demo.py --port= ' port ' --model_path= ' /path/to/model/ ' Nota: Index-1.9B-32K só pode ser iniciado usando esta ferramenta: demo/cli_long_text_demo.py !!!
Inicie uma demonstração de terminal com o seguinte código para usar o modelo Index-1.9B-Chat para diálogo:
python demo/cli_demo.py --model_path= ' /path/to/model/ 'Depende do Flask, instale com:
pip install flask==2.2.5Inicie uma API Flask com o seguinte código:
python demo/openai_demo.py --model_path= ' /path/to/model/ 'Você pode conduzir diálogos via linha de comando:
curl http://127.0.0.1:8010/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
} 'Index-1.9B-32K é um modelo de linguagem com apenas 1,9 bilhão de parâmetros, mas suporta um comprimento de contexto de 32K (o que significa que este modelo extremamente pequeno pode ler documentos com mais de 35.000 palavras de uma só vez). O modelo passou por pré-treinamento contínuo e ajuste fino supervisionado (SFT) especificamente para textos com mais de 32 mil tokens, com base em dados de treinamento de texto longo cuidadosamente selecionados e conjuntos de instruções de texto longo autoconstruídos. O modelo agora é de código aberto tanto no Hugging Face quanto no ModelScope.
Apesar de seu tamanho pequeno (cerca de 2% de modelos como o GPT-4), o Index-1.9B-32K demonstra excelentes capacidades de processamento de texto longo. Conforme mostrado na figura abaixo, a pontuação do nosso modelo de tamanho 1,9B supera até mesmo a do modelo de tamanho 7B. Abaixo está uma comparação com modelos como GPT-4 e Qwen2:
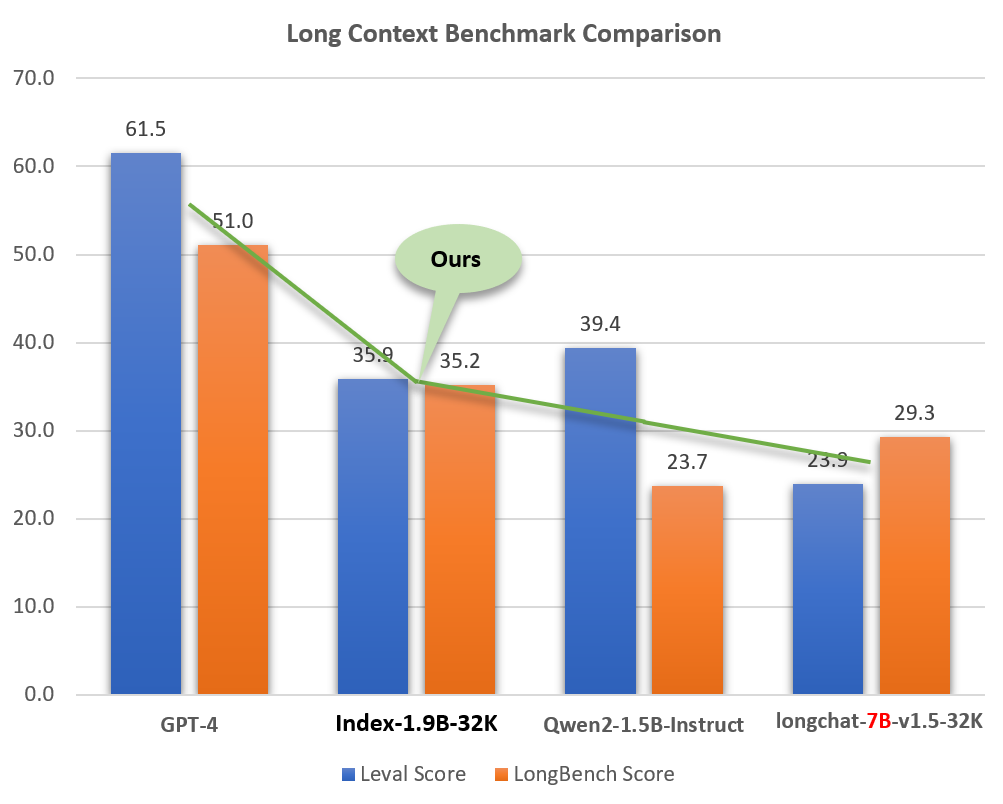
Comparação do Index-1.9B-32K com GPT-4, Qwen2 e outros modelos em capacidade de contexto longo
Em um teste de agulha em um palheiro de comprimento 32K, o Índice-1.9B-32K obteve excelentes resultados, conforme mostrado na figura abaixo. A única exceção foi uma pequena mancha amarela (91,08 pontos) na região de (32K de comprimento, 10% de profundidade), com todas as outras áreas apresentando excelente desempenho em zonas predominantemente verdes.
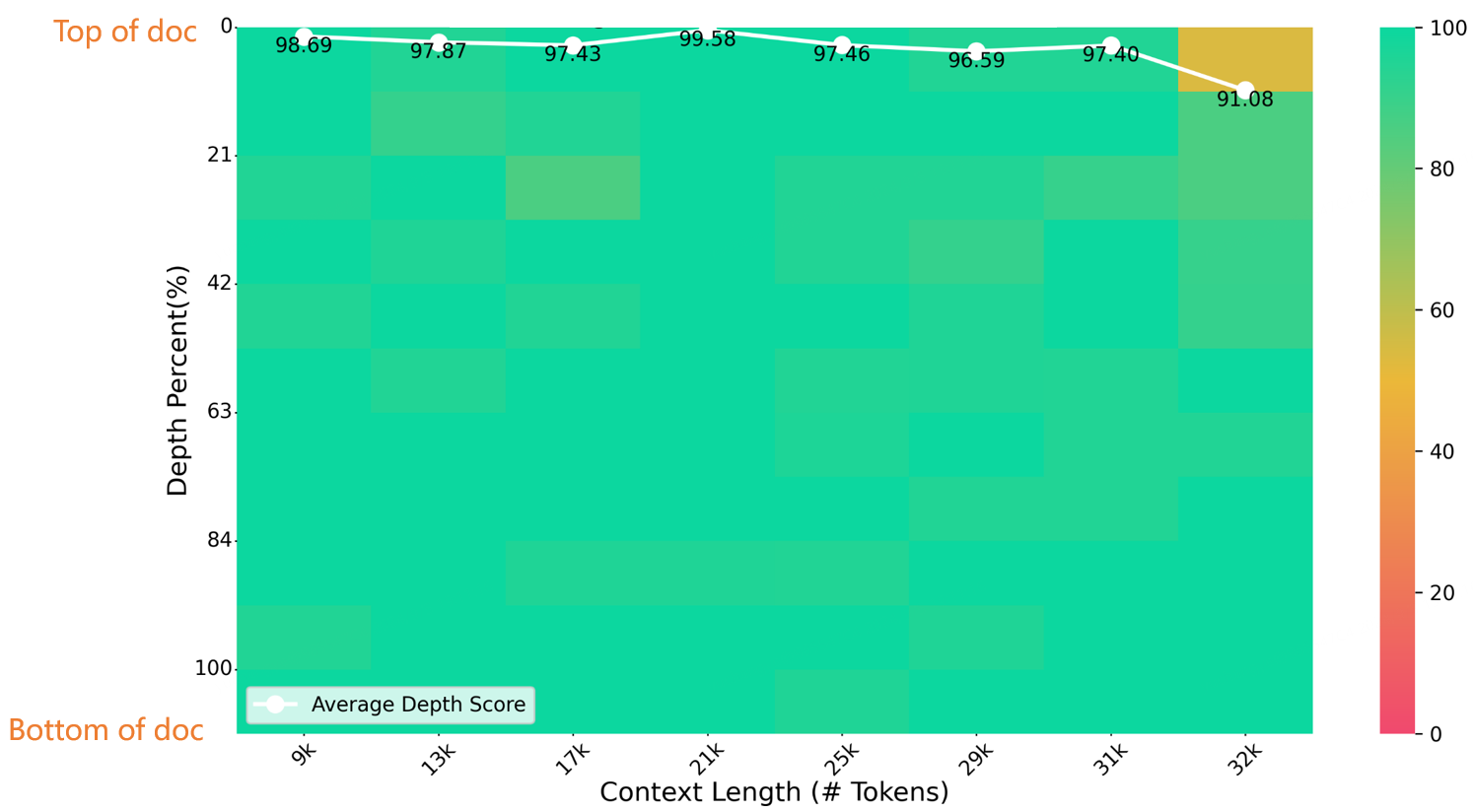
Avaliação do NeedleBench
Para obter detalhes sobre download, uso e relatório técnico do Index-1.9B-32K, consulte:
Relatório técnico de contexto longo Index-1.9B-32Kweb_demo.py para obter resultados do Index-1.9B-Chat. 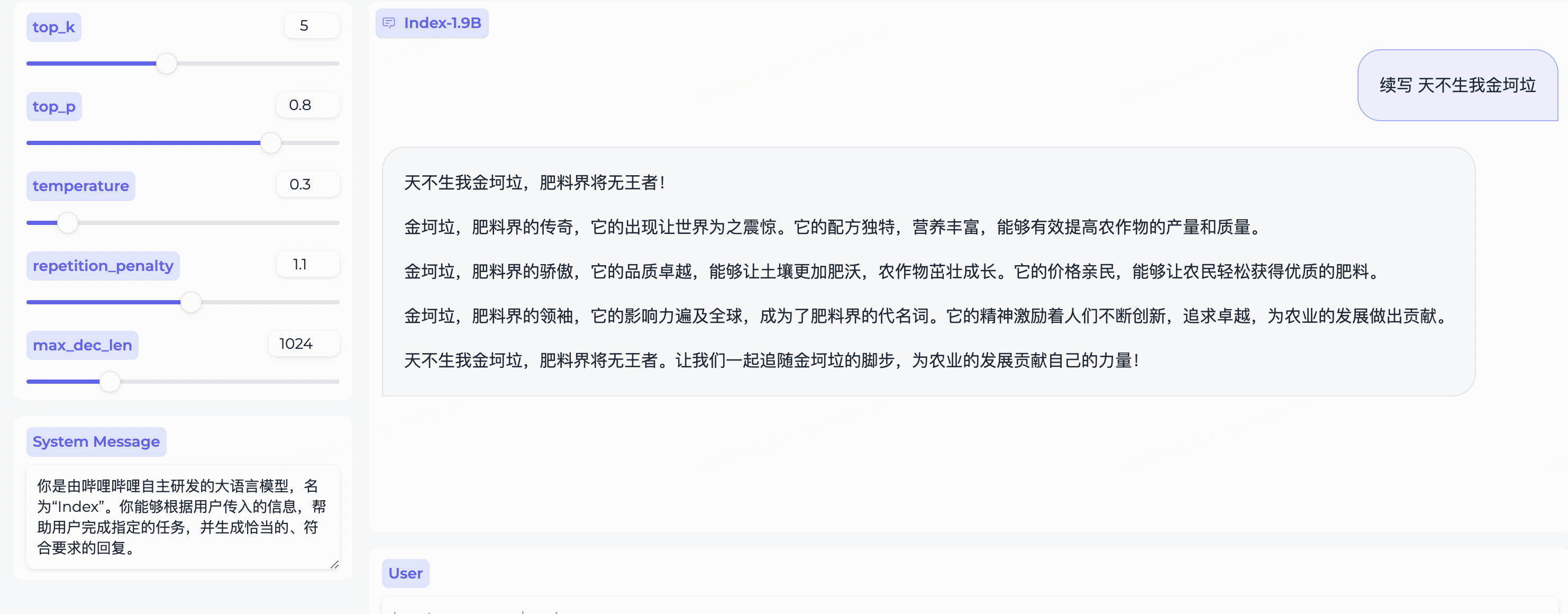
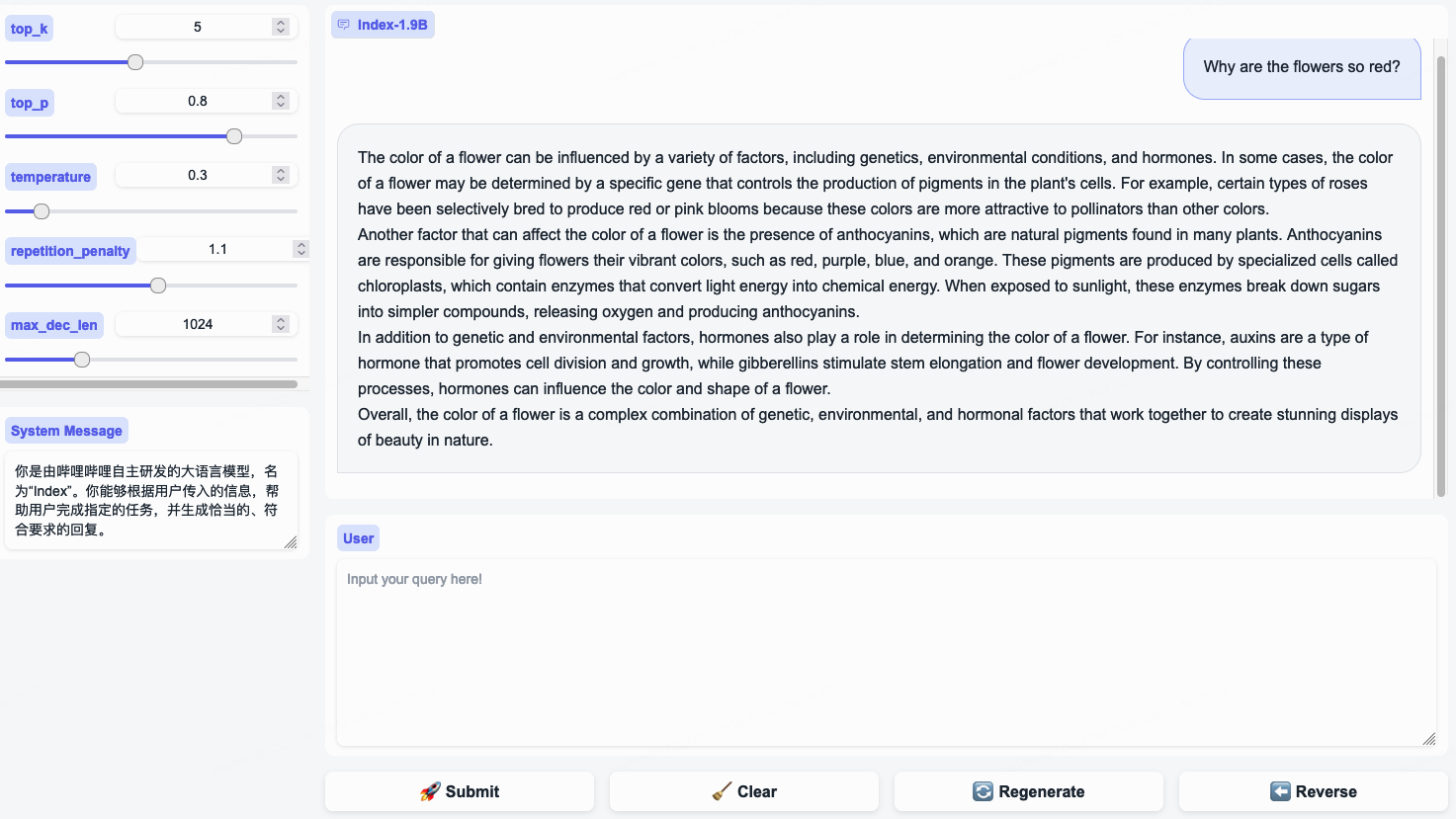
System Message para representar um estereótipo de usuário bilibili! 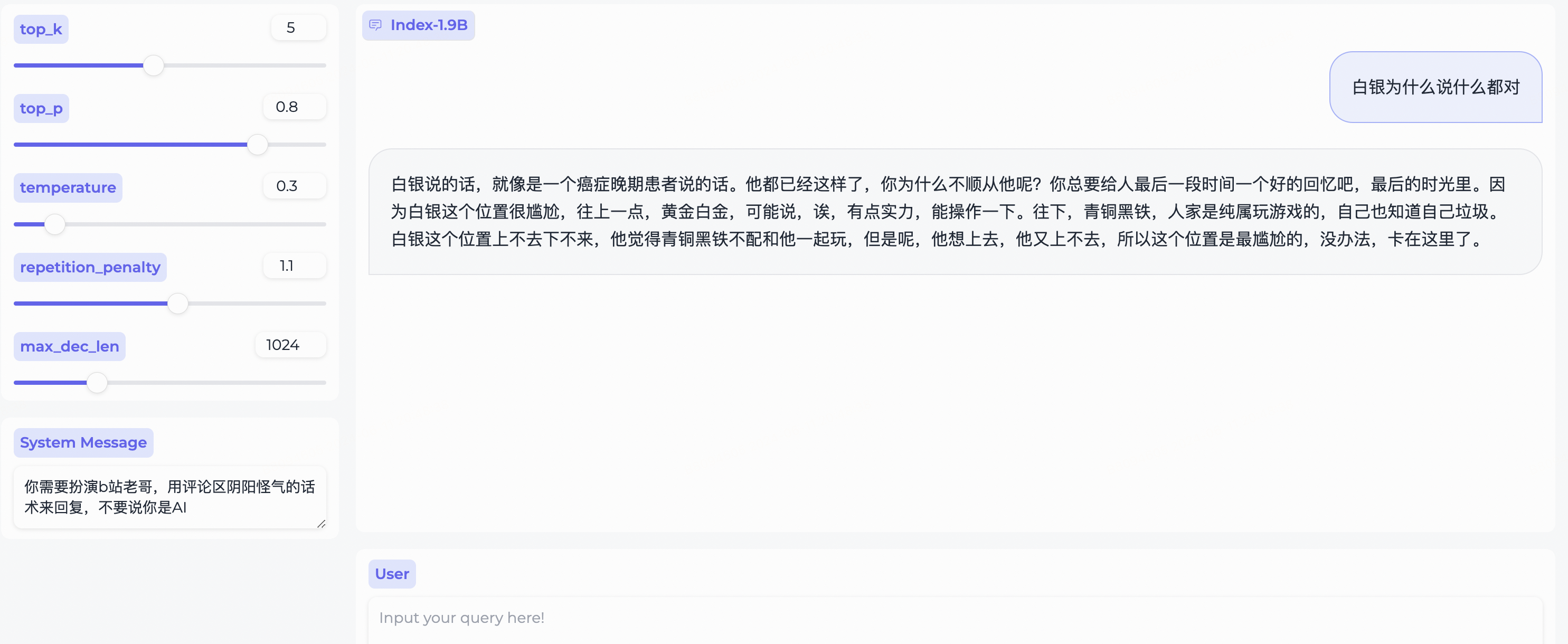
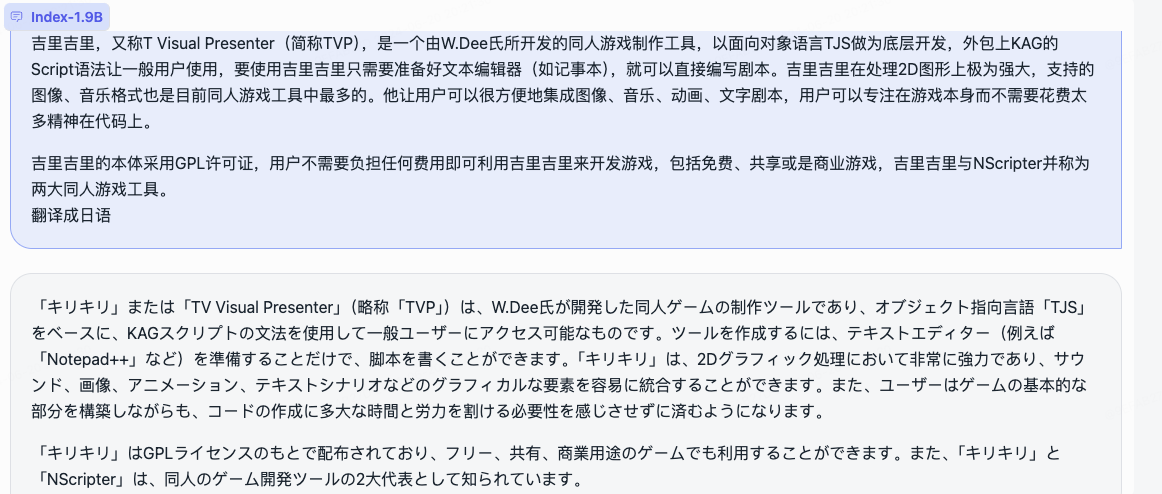
Simultaneamente, abrimos o código-fonte do modelo de role-playing e da estrutura que o acompanha. 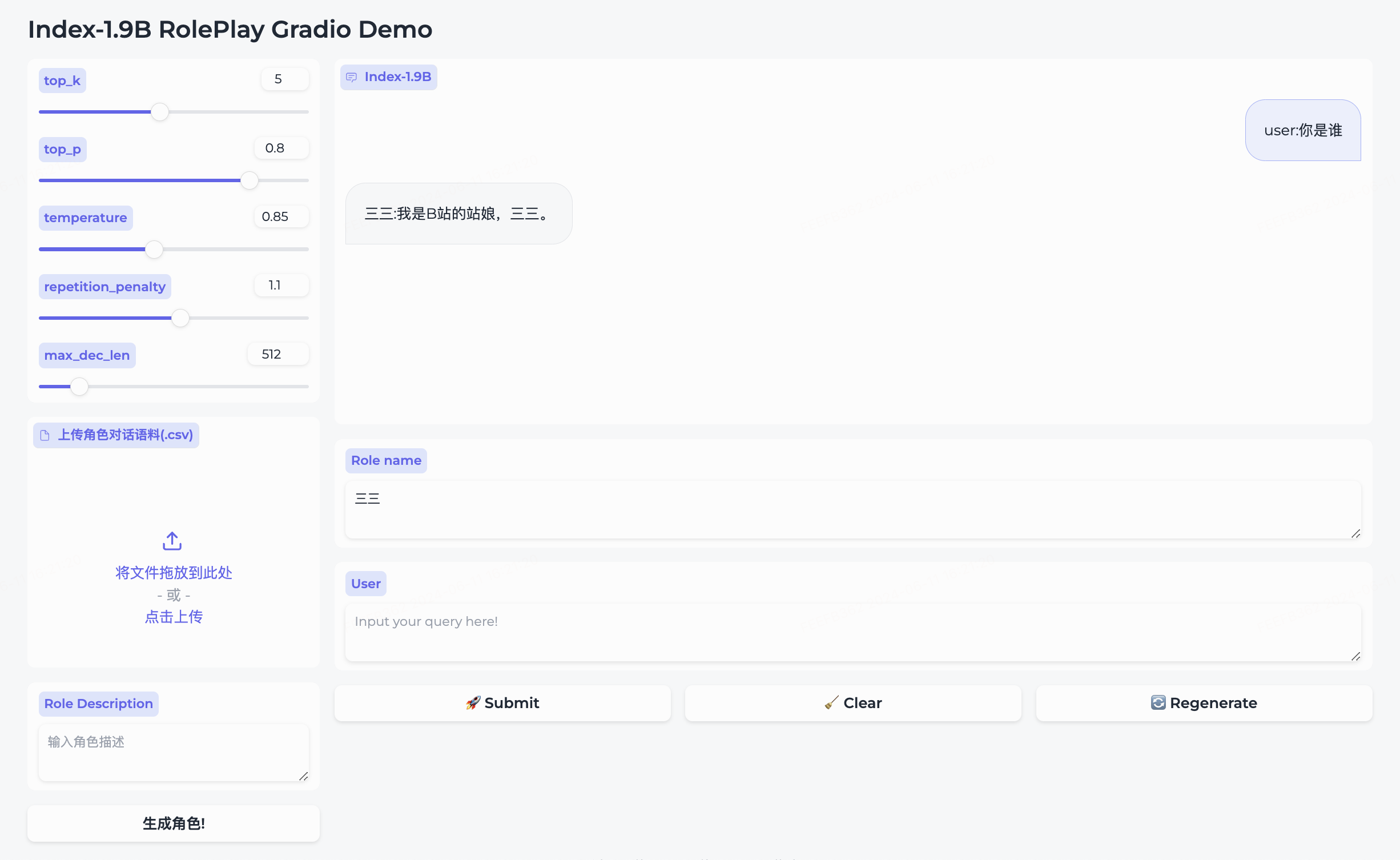
三三integrado.生成角色para criá-lo com sucesso.Role name , insira sua query e clique em submit para iniciar a conversa.Para uso detalhado, consulte a pasta roleplay.
cd demo/
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path ' /path/to/model/ ' --input_file_path data/user_long_text.txt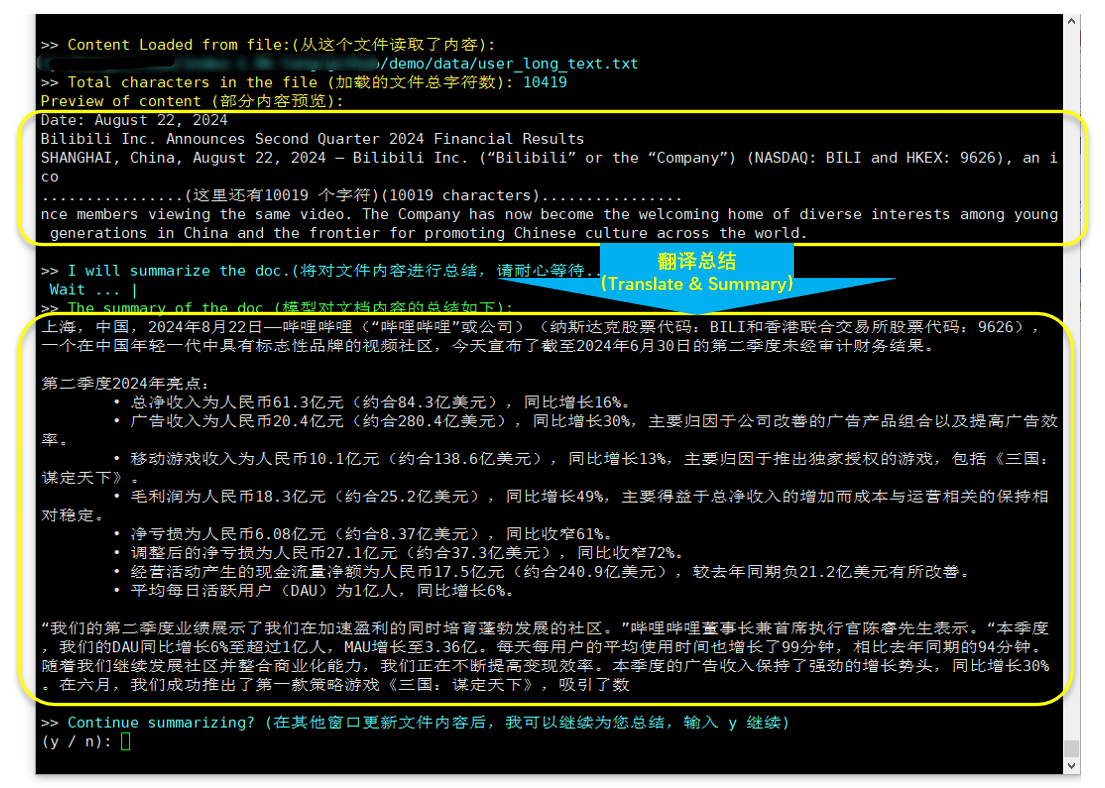
Tradução e resumo (relatório financeiro Bilibili divulgado em 2024.8.22)
Depende de bits e bytes, comando de instalação:
pip install bitsandbytes==0.43.0Você pode usar o script a seguir para realizar a quantização int4, que apresenta menos perda de desempenho e economiza ainda mais o uso da memória de vídeo.
import torch
import argparse
from transformers import (
AutoModelForCausalLM ,
AutoTokenizer ,
TextIteratorStreamer ,
GenerationConfig ,
BitsAndBytesConfig
)
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "" , type = str , help = "" )
parser . add_argument ( '--save_model_path' , default = "" , type = str , help = "" )
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
quantization_config = BitsAndBytesConfig (
load_in_4bit = True ,
bnb_4bit_compute_dtype = torch . float16 ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_quant_type = "nf4" ,
llm_int8_threshold = 6.0 ,
llm_int8_has_fp16_weight = False ,
)
model = AutoModelForCausalLM . from_pretrained ( args . model_path ,
device_map = "auto" ,
torch_dtype = torch . float16 ,
quantization_config = quantization_config ,
trust_remote_code = True )
model . save_pretrained ( args . save_model_path )
tokenizer . save_pretrained ( args . save_model_path )Siga as etapas do tutorial de ajuste fino para ajustar rapidamente o modelo Index-1.9B-Chat. Experimente e personalize seu modelo de índice exclusivo!
O Índice-1.9B pode gerar conteúdo impreciso, tendencioso ou de outra forma questionável em determinadas situações. O modelo não consegue compreender, expressar opiniões pessoais ou fazer julgamentos de valor. Seus resultados não representam as opiniões e posições dos desenvolvedores do modelo. Portanto, use o conteúdo gerado com cautela. Os usuários devem avaliar e verificar de forma independente o conteúdo gerado pelo modelo e não devem divulgar conteúdo prejudicial. Os desenvolvedores devem realizar testes de segurança e ajustes de acordo com aplicações específicas antes de implantar quaisquer aplicações relacionadas.
Aconselhamos vivamente a não utilização destes modelos para criar ou disseminar informações prejudiciais ou para se envolver em atividades que possam prejudicar a segurança pública, nacional ou social ou violar regulamentos. Não use os modelos para serviços de Internet sem a devida revisão e arquivamento de segurança. Fizemos todos os esforços para garantir a conformidade dos dados de treinamento, mas devido à complexidade do modelo e dos dados, ainda podem existir problemas imprevistos. Não seremos responsabilizados por quaisquer problemas decorrentes da utilização destes modelos, sejam eles relacionados à segurança dos dados, riscos de opinião pública ou quaisquer riscos e problemas causados por mal-entendidos, uso indevido, disseminação ou uso não conforme do modelo.
O uso do código-fonte deste repositório requer conformidade com o Apache-2.0. O uso dos pesos do modelo Index-1.9B requer conformidade com o INDEX_MODEL_LICENSE.
Os pesos do modelo Index-1.9B são totalmente abertos para pesquisas acadêmicas e suportam uso comercial gratuito .
Se você acha que nosso trabalho é útil para você, sinta-se à vontade para citá-lo!
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}
libllm: https://github.com/ling0322/libllm/blob/main/examples/python/run_bilibili_index.py
chatllm.cpp: https://github.com/foldl/chatllm.cpp/blob/master/docs/rag.md#role-play-with-rag
ollama: https://ollama.com/milkey/bilibili-index
auto llm: https://github.com/datawhalechina/self-llm/blob/master/bilibili_Index-1.9B/04-Index-1.9B-Chat%20Lora%20微调.md


