LLM4Decompile
1.0.0
![]()
Resultados | ? Modelos | Início rápido | HumanEval-Descompilar | ? Citação | Papel | Colab |
Engenharia reversa: descompilando código binário com grandes modelos de linguagem
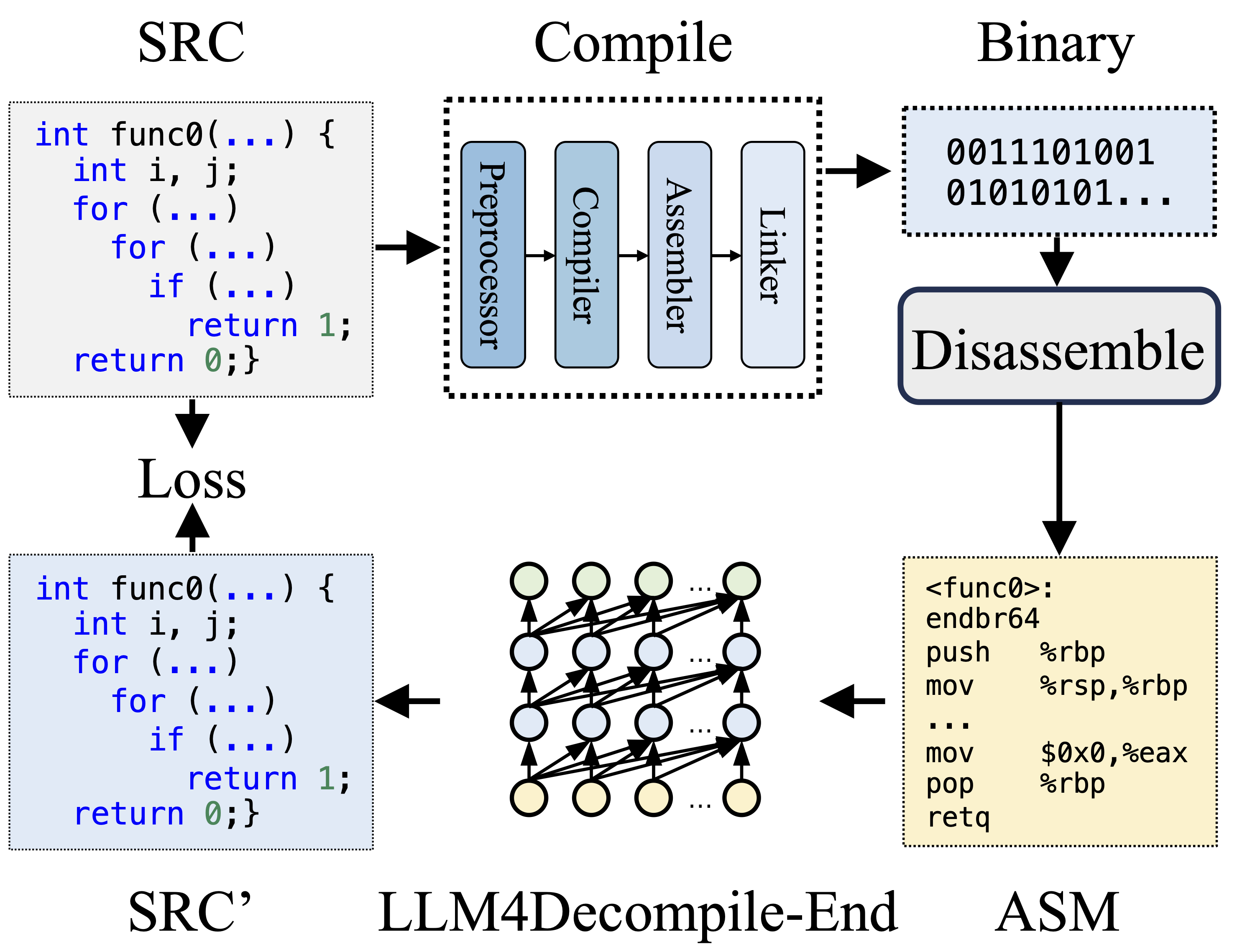
Durante a compilação, o Pré-processador processa o código-fonte (SRC) para eliminar comentários e expandir macros ou inclusões. O código limpo é então encaminhado ao compilador, que o converte em código assembly (ASM). Este ASM é transformado em código binário (0s e 1s) pelo Assembler. O Linker finaliza o processo vinculando chamadas de função para criar um arquivo executável. A descompilação, por outro lado, envolve a conversão do código binário de volta em um arquivo fonte. Os LLMs, sendo treinados em texto, não têm a capacidade de processar dados binários diretamente. Portanto, os binários devem ser desmontados primeiro pelo Objdump em linguagem assembly (ASM). Deve-se notar que ASM binário e desmontado são equivalentes, podem ser interconvertidos e, portanto, nos referimos a eles de forma intercambiável. Finalmente, a perda é calculada entre o código descompilado e o código-fonte para orientar o treinamento. Para avaliar a qualidade do código descompilado (SRC'), sua funcionalidade é testada por meio de asserções de teste (reexecutabilidade).
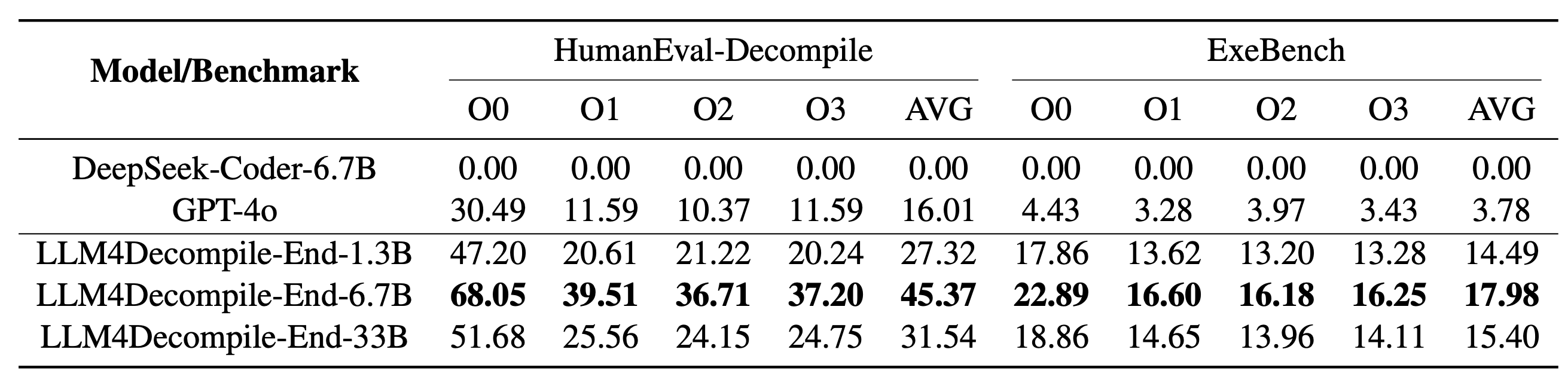
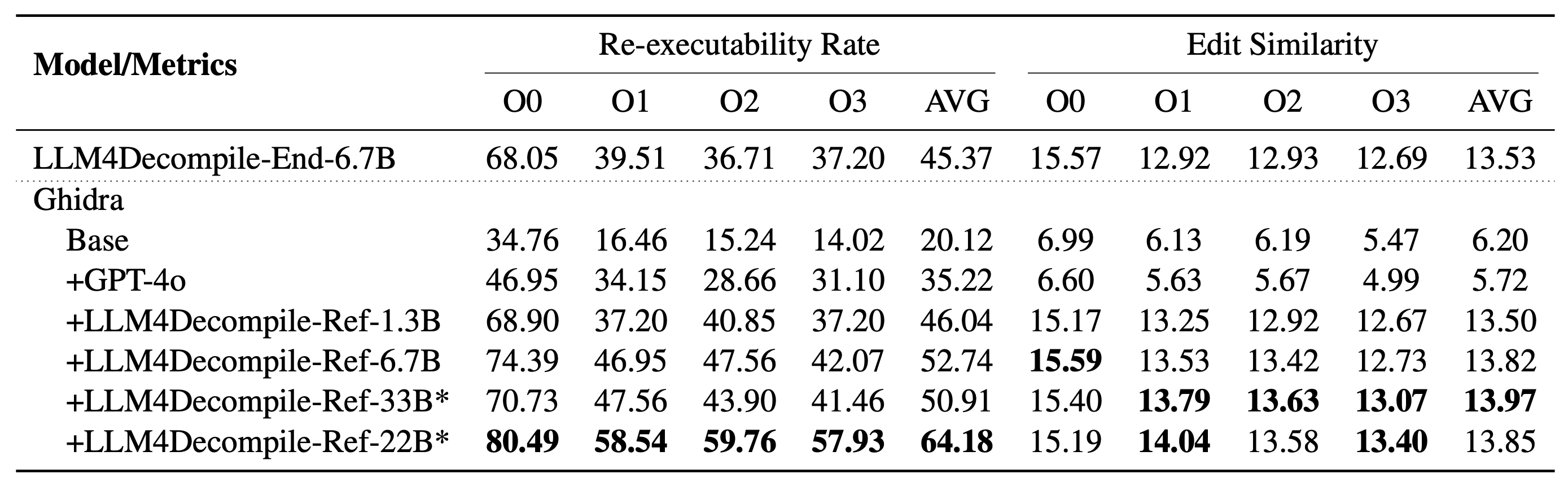
Nosso LLM4Decompile inclui modelos com tamanhos entre 1,3 bilhão e 33 bilhões de parâmetros, e disponibilizamos esses modelos no Hugging Face.
| Modelo | Ponto de verificação | Tamanho | Reexecutabilidade | Observação |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? Ligação HF | 1,3B | 27,3% | Nota 3 |
| llm4decompile-6.7b-v1.5 | ? Ligação HF | 6.7B | 45,4% | Nota 3 |
| llm4decompile-1.3b-v2 | ? Ligação HF | 1,3B | 46,0% | Nota 4 |
| llm4decompile-6.7b-v2 | ? Ligação HF | 6.7B | 52,7% | Nota 4 |
| llm4decompile-9b-v2 | ? Ligação HF | 9B | 64,9% | Nota 4 |
| llm4decompile-22b-v2 | ? Ligação HF | 22B | 63,6% | Nota 4 |
Nota 3: A série V1.5 é treinada com um conjunto de dados maior (15B tokens) e um tamanho máximo de token de 4.096, com desempenho notável (melhoria de mais de 100%) em comparação com o modelo anterior.
Nota 4: A série V2 é construída em Ghidra e treinada em 2 bilhões de tokens para refinar o pseudocódigo descompilado de Ghidra. Verifique a pasta ghidra para obter detalhes.
Configuração: Use o script abaixo para instalar o ambiente necessário.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Aqui está um exemplo de como usar nosso modelo (revisado para V1.5. Para modelos anteriores, verifique a página do modelo correspondente em HF). Nota: Substitua "func0" pelo nome da função que deseja descompilar .
Pré-processamento: compile o código C em binário e desmonte o binário em instruções assembly.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )As instruções de montagem devem estar no formato:
<FUNCTION_NAME>:nOPERATIONSnOPERATIONSn
As instruções de montagem típicas podem ser assim:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Descompilação: Use LLM4Decompile para traduzir as instruções de montagem em C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Os dados são armazenados em llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json , usando o formato de lista JSON. Existem 164*4 (O0, O1, O2, O3) amostras, cada uma com cinco teclas:
task_id : indica o ID do problema.type : o estágio de otimização, é um de [O0, O1, O2, O3].c_func : solução C para o problema HumanEval.c_test : asserções de teste C.input_asm_prompt : instruções assembly com prompts, podem ser derivadas como em nosso exemplo de pré-processamento.Por favor, verifique os scripts de avaliação.
Este repositório de código é licenciado sob a licença MIT e DeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


