Lovelace
velace's first appearance in these alleys.
Vá ler a documentação do Lovelace.
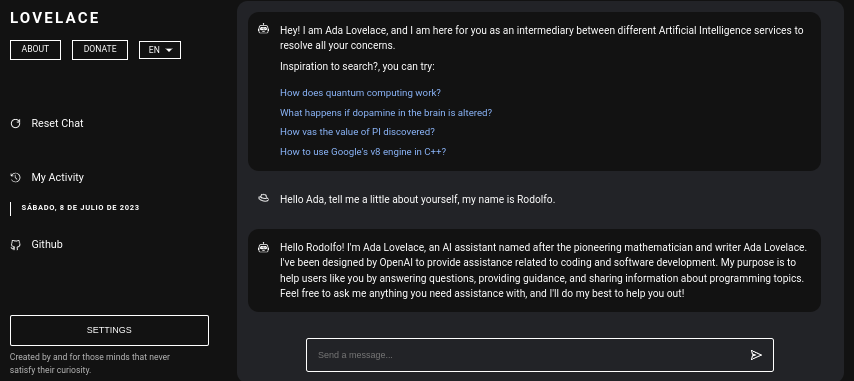
Lovelace é uma aplicação web que permite interação gratuita com ChatGPT usando a biblioteca GPT4FREE do Python. O software é escrito em JavaScript, utilizando NodeJS + Express + SocketIO no lado do servidor e Vite + ReactJS no Frontend.
O backend permite que diferentes clientes se comuniquem com o ChatGPT. Se o seu objetivo com o Lovelace é utilizá-lo para seus próprios fins ou propósitos, você só pode montar o servidor Backend em sua rede e ignorar o outro lado da aplicação, ou seja, o cliente; o backend permite sua interação através da API, ou você pode utilizar a conexão por WebSocket utilizando algum cliente SocketIO.
Índice:
Instalar o Lovelace em seu computador ou servidor é relativamente simples, você não deverá ter grandes complicações no processo; entretanto, antes de começar a clonar o repositório, certifique-se de ter pelo menos NodeJS v18.0.0 e Python v3.10 .
Considere que, caso você não tenha a versão necessária do NodeJS instalada em seu sistema, você pode utilizar o gerenciador de versões NVM (Node Version Manager) .
# Installing NVM on your system...
export NVM_DIR= " $HOME /.nvm " && (
git clone https://github.com/nvm-sh/nvm.git " $NVM_DIR "
cd " $NVM_DIR "
git checkout ` git describe --abbrev=0 --tags --match " v[0-9]* " $( git rev-list --tags --max-count=1 ) `
) && . " $NVM_DIR /nvm.sh "
# Once NVM has been installed, we proceed to install the specified NodeJS version (> 18.0.0)
nvm install 18.0.0 Se você não possui Python v3.10 em seu sistema, considere o seguinte:
# (DEBIAN)
sudo add-apt-repository ppa:deadsnakes/ppa && sudo apt update && sudo apt install python3.10
# (MacOS)
brew install [email protected]Da mesma forma, considere ter o pip instalado em seu sistema, pois ele será utilizado na instalação dos módulos necessários para poder montar o servidor backend dentro da rede.
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.pyAgora, supondo que você tenha as dependências mencionadas instaladas em seu sistema, podemos prosseguir para a próxima etapa...
Antes de começarmos a instalar e configurar o servidor backend como frontend Lovelace, precisamos clonar o repositório Github onde o código-fonte do aplicativo está localizado.
Considere que, neste ponto da leitura, presumo que você já tenha o Python versão 3.10 ou superior e o NodeJS versão 18.0.0; Na leitura anterior, antes de prosseguir com a instalação, foram explicados os passos para instalar cada um deles.
# Cloning the Github repository that contains the source code (I stole it from a cyber).
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace
# Accessing the "Client" folder, which stores the source code of the
# Vite + ReactjS (Frontend) application, and then installing its required modules from NPM.
cd Server && npm install --force && pip install -r Requirements.txt
# Like the previous line, we access the "Server" folder that houses the source code
# for the Lovelace Backend, then we install the NPM packages required to mount on the network.
cd ../Client && npm install --force Você pode preferir executar tudo em apenas uma linha...
git clone https://github.com/CodeWithRodi/Lovelace/ && cd Lovelace && cd Server && npm install --force && pip install -r Requirements.txt && cd ../Client && npm install --force && cd .. Lembre-se que, ao instalar os módulos necessários para rodar o servidor, o comando pip install -r Requirements.txt é executado para instalar os pacotes necessários para poder utilizar a biblioteca GPT4FREE . do Python. Se você não tiver pip instalado ou não instalar os pacotes Python, mesmo tendo o servidor backend e o cliente montados na rede, você não poderá fazer nada, pois quando uma solicitação for feita para tanto através de WebSocket's quanto via API utilizando a biblioteca NodeJS python-shell do backend, a comunicação é feita com o arquivo Python correspondente que se encarrega de retornar a resposta e caso não possua os requisitos necessários gerará um erro.
Depois de clonar o repositório Github, podemos prosseguir para a configuração e montagem em rede dos aplicativos frontend e backend, no entanto, vamos nos aprofundar um pouco mais no que armazena cada subpasta que contém a pasta gerada pela clonagem do repositório.
| Pasta | Descrição |
|---|---|
| Cliente | A pasta “Cliente” armazena o código fonte da aplicação Vite + React, ou seja, o frontend Lovelace, onde você pode montar o site na sua rede para poder se comunicar com o backend e estabelecer conversas de qualidade com a IA! |
| Documentação | A pasta "Documentação" contém o código-fonte dos documentos do software: https://lovelace-docs.codewithrodi.com/. |
| Servidor | A pasta "Server" abriga o código-fonte do backend Lovelace, onde é construído em NodeJS usando Express para fornecer a API e SocketIO para transmissão de respostas em WebSocket's. |
Além das pastas, você encontrará alguns arquivos, que da mesma forma serão apresentados juntamente com uma descrição abaixo.
| Arquivo | Descrição |
|---|---|
| .clocignore | É utilizado pelo software “cloc”, que permite contar as linhas de código do software, separando-as por tecnologia e pelos comentários que a linguagem de programação utilizada possa ter. Dentro do arquivo "clocignore" estão os caminhos dos arquivos e diretórios que o software deve ignorar na contagem. |
| LICENÇA | Contém a licença Lovelace à qual estão sujeitos o código fonte do Cliente e do Servidor. Este software está licenciado sob a licença MIT. |
Depois que o repositório tiver sido clonado e você tiver instalado posteriormente os módulos NPM de servidor e cliente necessários, é hora de configurar o back-end para começar a usar o software.
Vamos começar pelo servidor, é aqui que a mágica vai acontecer, você pode se comunicar com a IA através de solicitações de API ou usando WebSocket's; A seguir, será apresentada uma série de comandos para poder montar o servidor na rede.
# Accessing the <Server> folder that houses the repository you cloned earlier
cd Server/
# Running the server...
npm run start Se você fez tudo corretamente, o servidor já deverá estar rodando em seu sistema. Você pode verificar acessando http://0.0.0.0:8000/api/v1/ !
Script ( npm run <script_name> ) | Descrição |
|---|---|
| começar | Inicia-se a execução normal do servidor, você pode considerar esta opção caso queira montá-lo em produção. |
| desenvolvedor | Inicie a execução do servidor em modo de desenvolvimento com a ajuda do pacote "nodemon". |
Você deve saber que variáveis de ambiente são valores de caracteres dinâmicos, que permitem armazenar informações relacionadas a credenciais, configurações, etc..., então será apresentado o arquivo ".env" localizado dentro do código fonte do servidor, onde por sua vez você terá uma descrição sobre o funcionamento das variáveis disponíveis.
# Specifies the execution mode of the server, considers the value of <NODE_ENV>
# can be <development> and <production>.
NODE_ENV = production
# Address of the server where the client application is running.
CLIENT_HOST = https://lovelace.codewithrodi.com/
# Port where the server will
# start executing over the network.
SERVER_PORT = 8000
# Hostname where the server will be launched in
# complement with the previously established
# port on the network.
SERVER_HOST = 0.0.0.0
# If you have an SSL certificate, you must
# specify the certificate and then the key.
SSL_CERT =
SSL_KEY =
# Others...
CORS_ORIGIN = *
BODY_MAX_SIZE = 100kbSupondo que neste ponto da leitura você já tenha o servidor backend configurado na rede, podemos continuar configurando o servidor do cliente, onde, desta forma, você poderá começar a interagir com a IA através do site que você configurarei a seguir...
O aplicativo cliente é construído com ReactJS usando Vite como ferramenta de desenvolvimento. Com apenas alguns comandos de terminal, você pode configurar e implantar rapidamente o aplicativo em sua rede! Seguindo nossas instruções e utilizando o poder do ReactJS e Vite, você experimentará um processo de configuração contínuo e eficiente.
Certifique-se de que, para utilizar a aplicação web corretamente, é necessário que o servidor já esteja rodando na rede.
# Accessing the existing <Client> folder within the cloned repository
cd Client/
# Assuming you have already installed the necessary npm packages <npm install --force>
# we will proceed to start the server in development mode
npm run dev Feliz hacking!... Seu servidor deve estar rodando em http://0.0.0.0:5173/ .
Da mesma forma que foi feito na leitura anterior, será apresentada a seguir a lista de variáveis de ambiente que a aplicação cliente possui em seu arquivo ".env", juntamente com uma descrição da mesma.
# Address where the backend server was mounted, you must
# be sure to specify in the address if you have ridden
# the server under HTTPS, changing <http> to <https> ;)
VITE_SERVER = http://0.0.0.0:8000
# The server has a suffix to be able to access its respective API
# in this case we use v1
VITE_API_SUFFIX = /api/v1
# Others...
VITE_DONATE_LINK = https://ko-fi.com/codewithrodi
VITE_GPT4FREE_LINK = https://github.com/xtekky/gpt4free
VITE_SOFTWARE_REPOSITORY_LINK = https://github.com/codewithrodi/Lovelace Caso queira modificar o endereço de rede ou a porta usada ao iniciar o servidor Vite na rede, considere modificar o arquivo vite.config.js . Este arquivo contém as definições de configuração do servidor Vite. Abaixo está o conteúdo do arquivo vite.config.js :
export default defineConfig ( {
plugins : [ react ( ) ] ,
server : {
// If you want to change the network address where the server will be mounted
// you must change <0.0.0.0> to the desired one.
host : '0.0.0.0' ,
// Following the same line above, you must modify the port <5173>
// for which you want to ride on the network.
port : 5173
} ,
define : {
global : { }
}
} ) ;Observe que a modificação dessas configurações deve ser feita com cuidado, pois pode afetar a acessibilidade do servidor. Certifique-se de escolher um endereço de rede adequado e uma porta que ainda não esteja em uso.
Vite é uma escolha popular para desenvolver aplicações web escritas em JavaScript devido ao seu ambiente altamente eficiente. Oferece vantagens significativas, como reduzir drasticamente o tempo de inicialização ao carregar novos módulos ou compilar o código-fonte durante o processo de desenvolvimento. Ao aproveitar o Vite, os desenvolvedores podem experimentar maior produtividade e ciclos de desenvolvimento mais rápidos. Suas otimizações de velocidade e desempenho o tornam uma ferramenta valiosa para projetos de desenvolvimento web.
A aplicação web tem a capacidade de detectar o idioma do navegador a partir do qual a plataforma é acessada, para posteriormente poder detectar se há tradução do conteúdo disponível no idioma solicitado, caso não exista, um a tradução será devolvida. por padrão, que corresponde ao inglês.
Considere que, para adicionar novas traduções, você pode acessar Client/src/Locale/ , onde esta última pasta Locale/ abriga uma série de JSONs que estão no seguinte formato {LANGUAGE_IN_ISO_369}.json ; Caso queira adicionar uma nova tradução, basta seguir o formato e copiar as respectivas chaves cujo valor é atualizado para o idioma desejado que você está criando.
Atualmente, existem as seguintes traduções na aplicação web: French - Arabic - Chinese - German - English - Spanish - Italian - Portuguese - Russian - Turkish .
Se sua intenção é utilizar Lovelace para suas necessidades e objetivos individuais, você pode desconsiderar a aplicação Client implementada em ReactJS. Em vez disso, desvie sua atenção para o Servidor, pois é onde o encantamento realmente acontece.
Lembre-se que ao se comunicar com o backend utilizando API ou WebSocket's, os dados enviados como Model or Role não diferenciam maiúsculas de minúsculas, ou seja, se o valor de Model for gPT-3.5-TUrbO não importará, pois será formatado a partir do backend, o Prompt obviamente também não é importante, mas o valor atribuído ao Provider é, em leituras posteriores você aprenderá como obter os provedores disponíveis para poder utilizar ao estabelecer uma interação com a IA, da mesma forma que você poderá saber quais são seus respectivos modelos, ou agora poderá acessar o mesmo caminho /api/v1/chat/providers/ da instância pública do backend lovelace e visualizar as informações.
Aqui está um exemplo usando a API por meio da função Fetch nativa:
const Data = {
// Select the model you want to use for the request.
// <GPT-3.5-Turbo> | <GPT-4>
Model : 'GPT-3.5-Turbo' , // Recommended Model
// Use a provider according to the model you used, consider
// that you can see the list of providers next to the models
// that have available in:
// [GET REQUEST]: http://lovelace-backend.codewithrodi.com/api/v1/chat/providers/
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
// Prompt that you will send to the model
Prompt : 'Hi Ada, Who are you?'
} ;
// Note that if you want to use your own instance replace
// <https://lovelace-backend.codewithrodi.com> for the address
// from your server, or <http://0.0.0.0:8000> in case it is
// is running locally.
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
// We will make the request with the Fetch API provided in a way
// native by JavaScript, specified in the first instance
// the endpoint where our request will be made, while as a second
// parameter we specify by means of an object the method, the header and the
// body that will have the request.
fetch ( Endpoint , {
// /api/v1/chat/completions/
method : 'POST' ,
// We are sending a JSON, we specify the format
// in the request header
headers : { 'Content-Type' : 'application/json' } ,
body : JSON . stringify ( Data )
} )
// We transform the response into JSON
. then ( ( Response ) => Response . json ( ) )
// Once the response has been transformed to the desired format, we proceed
// to display the response from the AI in the console.
. then ( ( Response ) => console . log ( Response . Data . Answer ) )
// Consider that <Response> has the following structure
// Response -> { Data: { Answer: String }, Status: String(Success | ClientError) }
. catch ( ( RequestError ) => console . error ( RequestError ) ) ;Caso queira utilizar Axios na hora de fazer a comunicação, você pode considerar:
const Axios = require ( 'axios' ) ;
const Data = {
Model : 'GPT-3.5-Turbo' , // Recommended Model
Provider : 'GetGpt' , // Recommended Provider, you can also use 'DeepAi'
// GPT Role
Role : 'User' ,
Prompt : 'Hi Ada, Who are you?'
} ;
const Endpoint = 'https://lovelace-backend.codewithrodi.com/api/v1/chat/completions' ;
( async function ( ) {
const Response = ( await Axios . post ( Endpoint , Data , { headers : { 'Content-Type' : 'application/json' } } ) ) . data ;
console . log ( Response . Data . Answer ) ;
} ) ( ) ; Você pode ver como o cliente se comunica com o back-end por meio da API observando os arquivos Client/src/Services/Chat/Context.jsx e Client/src/Services/Chat/Service.js , onde a mágica acontece.
A partir do servidor backend, é fornecido um servidor WebSocket com a ajuda do SocketIO, portanto é recomendado utilizar um cliente fornecido pela mesma biblioteca, como npm i socket.io-client no caso do NodeJS. Recomenda-se utilizar este tipo de comunicação caso se queira uma resposta “instantânea”, pois a resposta da IA, ao contrário do uso da comunicação via API, não se deve esperar que a IA termine de processar a resposta para ser exibida . . Utilizando WebSocket's a resposta da IA é transmitida em partes, gerando uma interação com o cliente instantaneamente.
const { io } = require ( 'socket.io-client' ) ;
// Using the NodeJS 'readline' module, like this
// allow <Prompts> to be created by the user
// to our console application.
const ReadLine = require ( 'readline' ) . createInterface ( {
input : process . stdin ,
output : process . stdout
} ) ;
// We store the address where the Lovelace backend is mounted.
// In case your instance is running locally
// you can change the value of <Endpoint> to something like <http://0.0.0.0:8000>.
const Endpoint = 'http://lovelace-backend.codewithrodi.com/' ;
( async function ( ) {
const Socket = io ( Endpoint ) . connect ( ) ;
console . log ( `Connecting to the server... [ ${ Endpoint } ]` ) ;
Socket . on ( 'connect' , ( ) => {
console . log ( 'Connected, happy hacking!' ) ;
RunApplicationLoop ( ) ;
} ) ;
Socket . on ( 'disconnect' , ( ) => {
console . log ( 'nDisconnected, bye bye...!' ) ;
process . exit ( 0 ) ;
} ) ;
// We use <process.stdout.write(...)> instead of <console.log(...)> because
// in this way we print directly to the console without each time
// that a part of the response is received, a new line (n) is executed.
Socket . on ( 'Response' , ( StreamedAnswer ) => process . stdout . write ( StreamedAnswer ) ) ;
const BaseQuery = {
// We indicate the model that we want to use to communicate with the AI
// 'GPT-3.5-Turbo' - 'GPT-4'
Model : 'GPT-3.5-Turbo' ,
// Provider to use in the communication, keep in mind that not all
// providers offer ChatGPT 3.5 or ChatGPT 4. You can make a request
// [GET] to <https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/>
Provider : 'GetGpt' ,
Role : 'User' ,
} ;
const HandleClientPrompt = ( ) => new Promise ( ( Resolve , Reject ) => {
const HandleStreamedResponseEnd = ( MaybeError ) => {
if ( MaybeError ) {
return Reject ( MaybeError ) ;
}
Resolve ( ) ;
} ;
ReadLine . question ( 'Prompt > ' , ( Prompt ) => {
// We issue <Prompt> to the server, where as the second parameter
// send the Query to it, specifying the Model, Provider, Role and Prompt.
// The last parameter corresponds to the Callback that will be called
// once the transmission of the response is finished, consider that this
// callback receives a parameter, which corresponds to whether there is an error
// or not during transmission, its content is therefore the error.
Socket . emit ( 'Prompt' , { Prompt , ... BaseQuery } , HandleStreamedResponseEnd ) ;
} ) ;
} ) ;
const RunApplicationLoop = async ( ) => {
while ( true ) {
await HandleClientPrompt ( ) ;
console . log ( 'n' ) ;
}
} ;
} ) ( ) ; Caso queira estabelecer comunicação com o Backend Lovelace através de WebSocket's em outra linguagem que não a apresentada, você pode considerar:
Considere que, apesar de a biblioteca python GPT4FREE ser utilizada no backend, os provedores desta última são diferentes daqueles oferecidos pela Lovelace. Você pode obter a lista de provedores disponíveis através da API, onde obterá informações como os modelos que permite utilizar, o endereço web onde o serviço está hospedado e o nome que deve ser especificado ao interagir com a IA como você viu nos exemplos. anterior (API, WS).
A resposta que você deve obter de https://lovelace-backend.codewithrodi.com/api/v1/chat/providers/ deve ser:
{
"Status" : " Success " ,
"Data" :{
"Providers" :{
// List of providers available to use on WebSocket's
"WS" :[
{
// Name to specify when making the query
"Name" : " DeepAi " ,
// Web address where the service is hosted
"Website" : " https://deepai.org " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others WebSocket's providers...
{ "Name" : " Theb " , "Website" : " https://theb.ai " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
],
// List of Providers available to be able to use through the API
"API" :[
{
// Name to specify when making the query
"Name" : " Aichat " ,
// Web address where the service is hosted
"Website" : " https://chat-gpt.org/chat " ,
// Available models
"Models" :[ " gpt-3.5-turbo " ]
},
// ! Others API providers...
{ "Name" : " ChatgptLogin " , "Website" : " https://chatgptlogin.ac " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " DeepAi " , "Website" : " https://deepai.org " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " Yqcloud " , "Website" : " https://chat9.yqcloud.top/ " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " You " , "Website" : " https://you.com " , "Models" :[ " gpt-3.5-turbo " ] },
{ "Name" : " GetGpt " , "Website" : " https://chat.getgpt.world/ " , "Models" :[ " gpt-3.5-turbo " ] }
]
}
}
}Como você viu, a lista de provedores está dividida em 2 partes, uma para aquelas consultas feitas através da API e outra para aquelas que utilizam WebSocket's.
Ao contrário de outros exemplos onde estão envolvidas solicitações ao servidor backend Lovelace, obter a lista de provedores e seus respectivos modelos disponíveis é uma tarefa bastante fácil, pois basta enviar uma solicitação [GET] para /api/v1 /chat/providers/ , onde a resposta será o JSON que foi mostrado anteriormente.
Para o exemplo a seguir, usaremos Axios dentro do NodeJS, que você pode instalar usando o gerenciador de pacotes NPM usando o comando npm i axios .
const Axios = require ( 'axios' ) ;
( async function ( ) {
// Consider that, you can replace <https://lovelace-backend.codewithrodi.com> with
// the address where your backend server is mounted. If t

