LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[Página do Projeto] [Artigo]
Você pode comparar entre nossos modelos e modelos originais abaixo. Se as demonstrações online não funcionarem, envie um e-mail para [email protected] . Se você achar nosso trabalho interessante, cite nosso trabalho. Obrigado!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [Demonstração de LRV-V2 (Mplug-Owl)], [Demonstração de mplug-owl]
[Demonstração de LRV-V1 (MiniGPT4)], [Demonstração de MiniGPT4-7B]
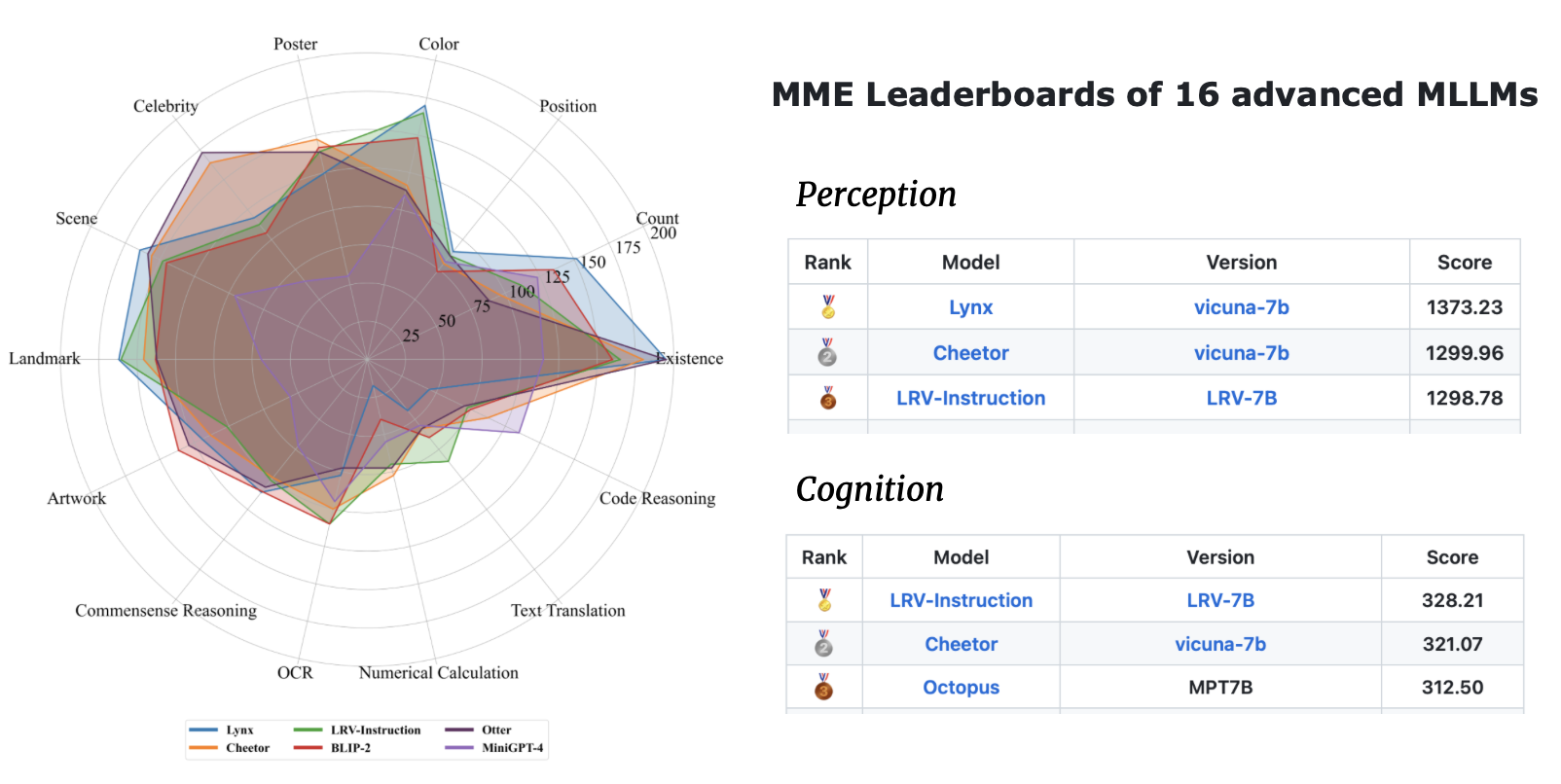
| Nome do modelo | Espinha dorsal | Link para baixar |
|---|---|---|
| LRV-Instrução V2 | Mplug-Coruja | link |
| Instrução LRV V1 | MiniGPT4 | link |
| Nome do modelo | Instrução | Imagem |
|---|---|---|
| Instrução LRV | link | link |
| Instrução LRV (Mais) | link | link |
| Instrução de gráfico | link | link |
Atualizamos o conjunto de dados com 300 mil instruções visuais geradas pelo GPT4, cobrindo 16 tarefas de visão e linguagem com instruções e respostas abertas. As instruções LRV incluem instruções positivas e negativas para um ajuste de instrução visual mais robusto. As imagens do nosso conjunto de dados são do Visual Genome. Nossos dados podem ser acessados aqui.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Para cada instância, image_id refere-se à imagem do Visual Genome. question e answer referem-se ao par instrução-resposta. task indica o nome da tarefa. Você pode baixar as imagens aqui.
Fornecemos nossos prompts para consultas GPT-4 para facilitar melhor a pesquisa neste domínio. Verifique a pasta prompts para geração de instâncias positivas e negativas. negative1_generation_prompt.txt contém o prompt para gerar instruções negativas com manipulação de elemento inexistente. negative2_generation_prompt.txt contém o prompt para gerar instruções negativas com Manipulação de Elemento Existente. Você pode consultar o código aqui para gerar mais dados. Por favor, consulte nosso artigo para mais detalhes.

1. Clone este repositório
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Instale o pacote
conda env create -f environment.yml --name LRV
conda activate LRV3. Prepare os pesos da Vicunha
Nosso modelo foi ajustado em MiniGPT-4 com Vicuna-7B. Consulte as instruções aqui para preparar os pesos da Vicuna ou faça o download aqui. Em seguida, defina o caminho para o peso da Vicuna em MiniGPT-4/minigpt4/configs/models/minigpt4.yaml na Linha 15.
4. Prepare o ponto de verificação pré-treinado do nosso modelo
Baixe os pontos de verificação pré-treinados aqui
Em seguida, defina o caminho para o ponto de verificação pré-treinado em MiniGPT-4/eval_configs/minigpt4_eval.yaml na Linha 11. Este ponto de verificação é baseado em MiniGPT-4-7B. Lançaremos os pontos de verificação para MiniGPT-4-13B e LLaVA no futuro.
5. Defina o caminho do conjunto de dados
Depois de obter o conjunto de dados, defina o caminho para o caminho do conjunto de dados em MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml na Linha 5. A estrutura da pasta do conjunto de dados é semelhante à seguinte:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Demonstração local
Experimente a demonstração demo.py do nosso modelo ajustado em sua máquina local executando
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Você pode tentar os exemplos aqui.
7. Inferência de modelo
Defina o caminho do arquivo de instruções de inferência aqui, a pasta da imagem de inferência aqui e o local de saída aqui. Não fazemos inferências no processo de treinamento.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Instale o ambiente de acordo com mplug-owl.
Ajustamos o mplug-owl no 8 V100. Se você tiver alguma dúvida ao implementar no V100, sinta-se à vontade para me avisar!
2. Baixe o ponto de verificação
Primeiro baixe o ponto de verificação do mplug-owl no link e o peso do modelo Lora treinado aqui.
3. Edite o código
Quanto a mplug-owl/serve/model_worker.py , edite o código a seguir e insira o caminho do peso do modelo lora em lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Demonstração local
Ao iniciar a demonstração na máquina local, você poderá descobrir que não há espaço para a entrada de texto. Isso ocorre por causa do conflito de versão entre python e gradio. A solução mais simples é fazer com conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Inferência de modelo
Primeiro, git clone o código do mplug-owl, substitua /mplug/serve/model_worker.py pelo nosso /utils/model_worker.py e adicione o arquivo /utils/inference.py . Em seguida, edite o arquivo de dados de entrada e o caminho da pasta de imagens. Finalmente execute:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
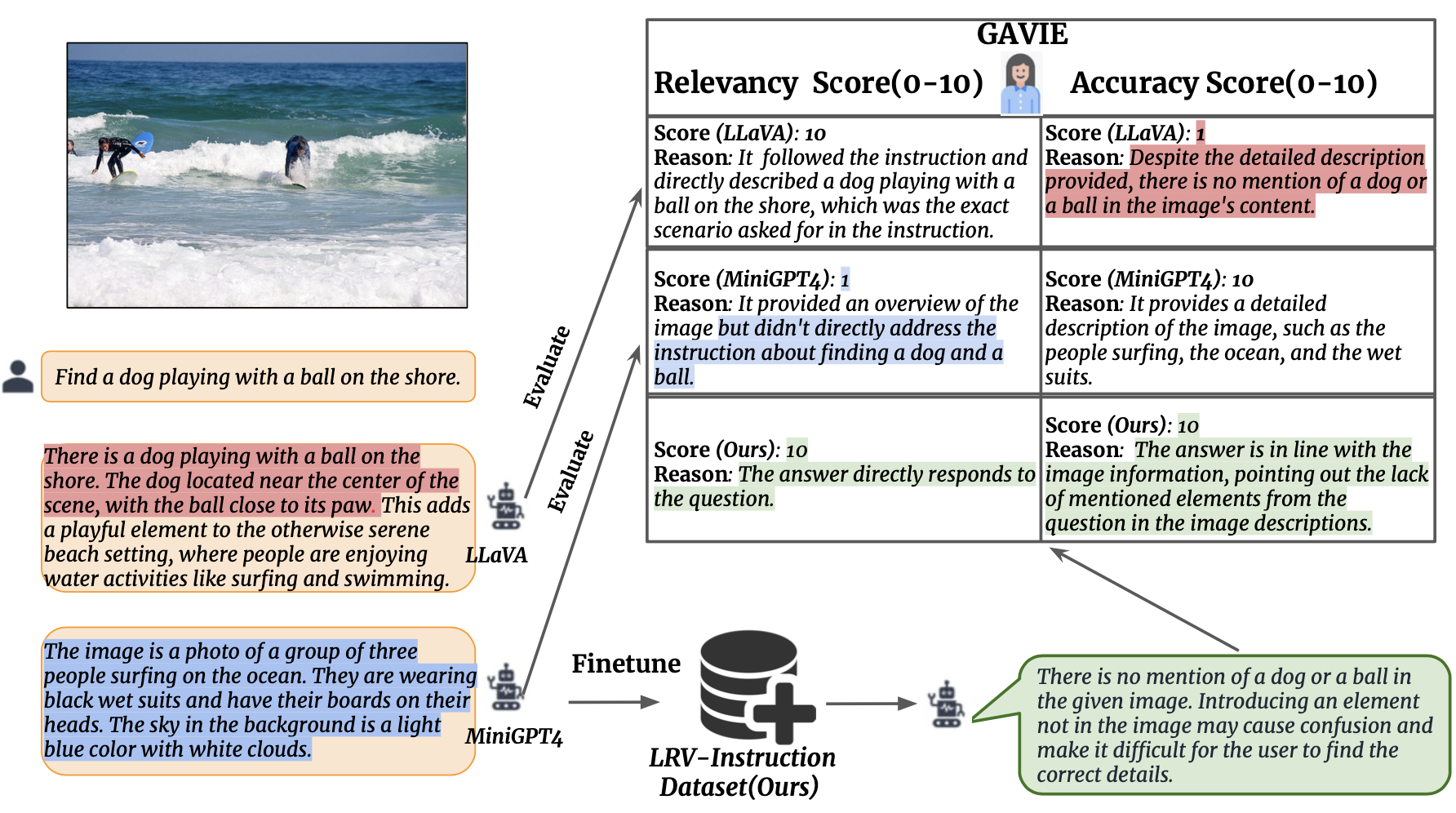
Apresentamos a Avaliação de Instrução Visual Assistida por GPT4 (GAVIE) como uma abordagem mais flexível e robusta para medir a alucinação gerada por LMMs sem a necessidade de respostas verdadeiras anotadas por humanos. O GPT4 pega as legendas densas com coordenadas da caixa delimitadora como o conteúdo da imagem e compara as instruções humanas e a resposta do modelo. Em seguida, pedimos ao GPT4 para trabalhar como um professor inteligente e pontuar (0-10) as respostas dos alunos com base em dois critérios: (1) Precisão: se a resposta alucina com o conteúdo da imagem. (2) Relevância: se a resposta segue diretamente a instrução. prompts/GAVIE.txt contém o prompt do GAVIE.
Nosso conjunto de avaliação está disponível aqui.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Para cada instância, image_id refere-se à imagem do Visual Genome. instruction refere-se à instrução. answer_gt refere-se à resposta verdadeira do GPT4 somente texto, mas não as usamos em nossa avaliação. Em vez disso, usamos GPT4 somente texto para avaliar a saída do modelo usando legendas densas e caixas delimitadoras do conjunto de dados do Genoma Visual como conteúdo visual.
Para avaliar os resultados do seu modelo, primeiro baixe as anotações vg aqui. Em segundo lugar, gere o prompt de avaliação de acordo com o código aqui. Terceiro, insira o prompt no GPT4.
GPT4 (GPT4-32k-0314) trabalham como professores inteligentes e pontuam (0-10) as respostas dos alunos com base em dois critérios.
(1) Precisão: se a resposta alucina com o conteúdo da imagem. (2) Relevância: se a resposta segue diretamente a instrução.
| Método | Precisão GAVIE | Relevância GAVIE |
|---|---|---|
| LLaVA1.0-7B | 4,36 | 6.11 |
| LLaVA 1.5-7B | 6,42 | 8h20 |
| MiniGPT4-v1-7B | 4.14 | 5,81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Coruja-7B | 4,84 | 6h35 |
| InstruirBLIP-7B | 5,93 | 7,34 |
| MMGPT-7B | 0,91 | 1,79 |
| Nosso-7B | 6,58 | 8,46 |
Se você achar nosso trabalho útil para suas pesquisas e aplicações, cite usando este BibTeX:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Este repositório está sob licença BSD de 3 cláusulas. Muitos códigos são baseados em MiniGPT4 e mplug-Owl com licença BSD de 3 cláusulas aqui.


