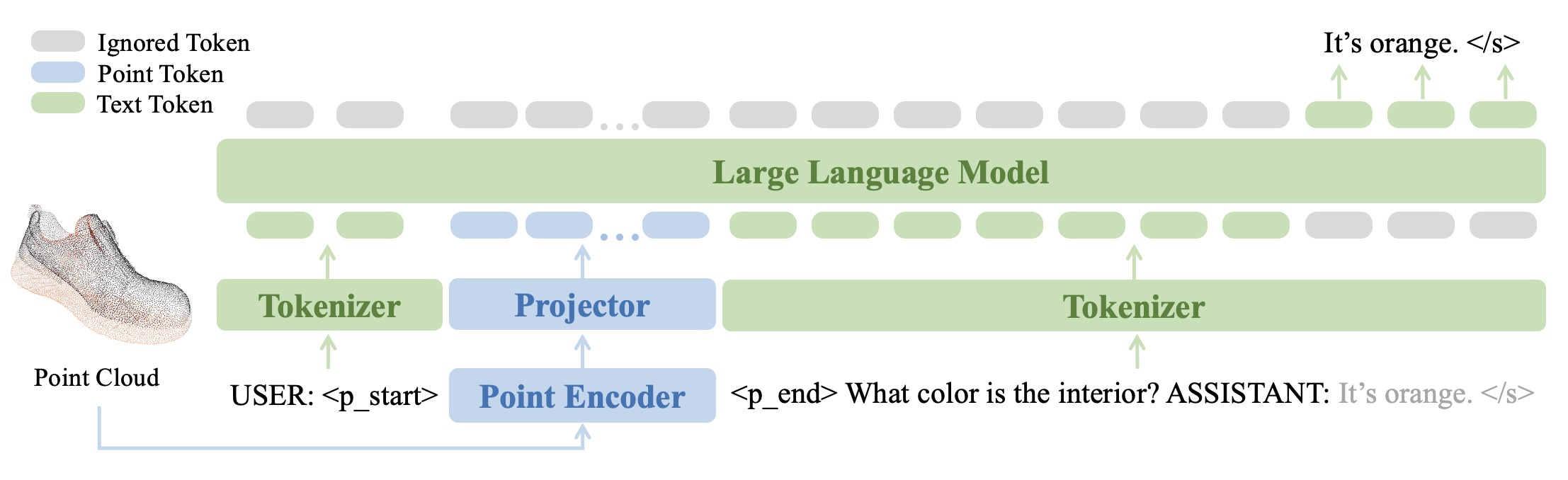
PointLLM
1.0.0
 PointLLM: capacitando grandes modelos de linguagem para compreender nuvens de pontos
PointLLM: capacitando grandes modelos de linguagem para compreender nuvens de pontos Runsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
Universidade Chinesa de Hong Kong Laboratório de IA de Xangai Universidade de Zhejiang

PointLLM está online! Experimente em http://101.230.144.196 ou em OpenXLab/PointLLM.
Você pode conversar com PointLLM sobre os modelos do conjunto de dados Objaverse ou sobre suas próprias nuvens de pontos!
Por favor, não hesite em nos dizer se você tiver algum comentário! ?
| Diálogo 1 | Diálogo 2 | Diálogo 3 | Diálogo 4 |
|---|---|---|---|
 |  |  |  |
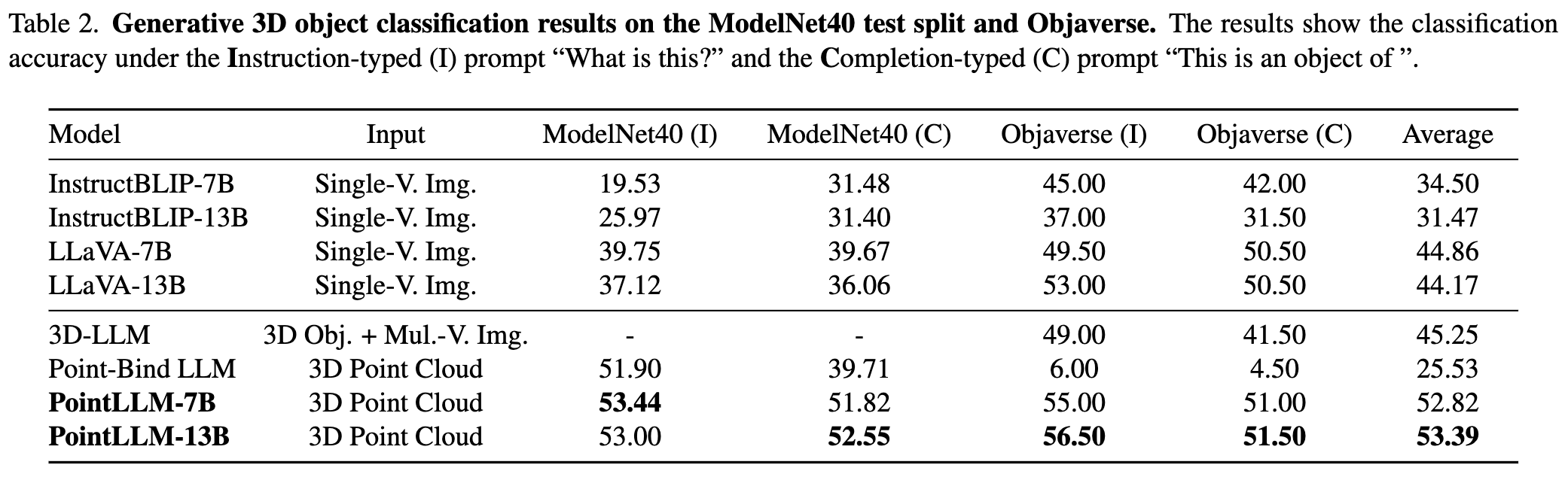
Consulte nosso artigo para obter mais resultados.
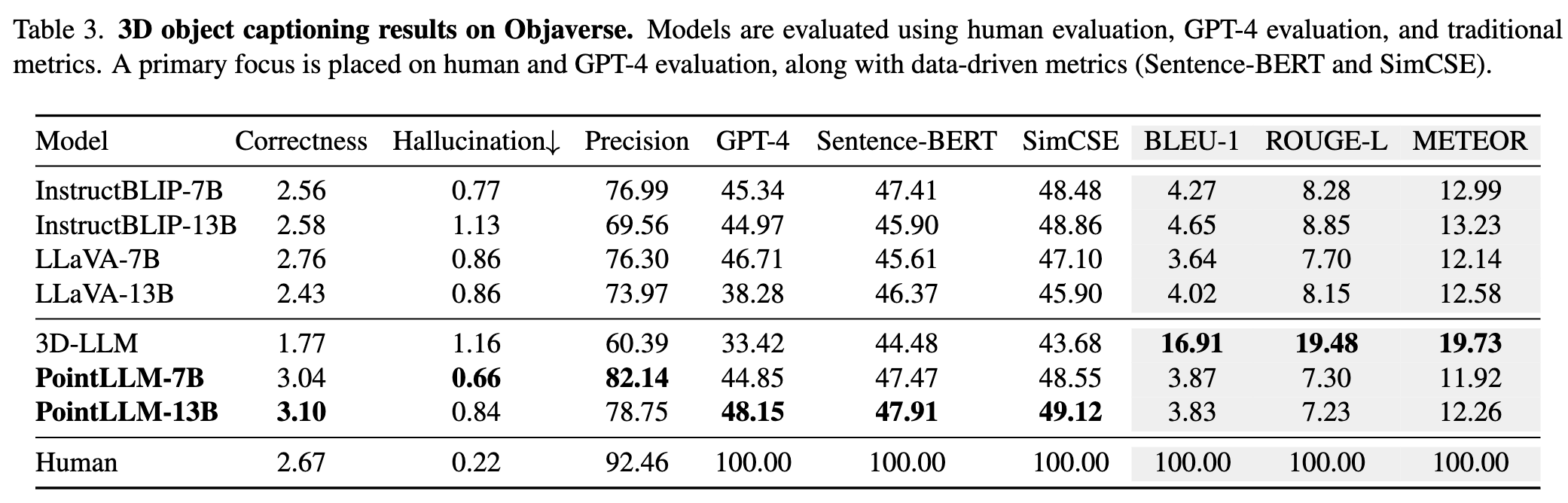
Consulte nosso artigo para obter mais resultados.

Testamos nossos códigos no seguinte ambiente:
Para começar:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy contendo arquivos de nuvem de pontos de 660 mil chamados {Objaverse_ID}_8192.npy . Cada arquivo é uma matriz numpy com dimensões (8192, 6), onde as três primeiras dimensões são xyz e as três últimas dimensões são rgb no intervalo [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM , crie uma pasta data e crie um link simbólico para o arquivo descompactado no diretório. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data , crie um diretório chamado anno_data .anno_data . O diretório deve ficar assim: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json é filtrado de PointLLM_brief_description_660K.json removendo os 3.000 objetos que reservamos como conjunto de validação. Se quiser reproduzir os resultados em nosso artigo, você deve usar PointLLM_brief_description_660K_filtered.json para treinamento. O PointLLM_complex_instruction_70K.json contém objetos do conjunto de treinamento.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json que usamos para os benchmarks no conjunto de dados Objaverse aqui e coloque-a em PointLLM/data/anno_data . Também fornecemos os 3.000 IDs de objetos que filtramos durante o treinamento aqui e sua referência GT correspondente aqui, que pode ser usada para avaliar todos os 3.000 objetos.modelnet40_data em PointLLM/data . Baixe a divisão de teste das nuvens de pontos ModelNet40 modelnet40_test_8192pts_fps.dat aqui e coloque-a em PointLLM/data/modelnet40_data .PointLLM , crie um diretório chamado checkpoints .checkpoints . cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shNormalmente, você não precisa se preocupar com o conteúdo a seguir. Eles servem apenas para reproduzir os resultados em nosso artigo v1 (PointLLM-v1.1). Se você quiser comparar com nossos modelos ou usar nossos modelos para tarefas posteriores, use PointLLM-v1.2 (consulte nosso artigo v2), que tem melhor desempenho.
PointLLM v1.1 e v1.2 usam codificadores de ponto e projetores pré-treinados ligeiramente diferentes. Se você deseja reproduzir o PointLLM v1.1, edite o arquivo config.json no diretório do LLM inicial e dos pesos do codificador de ponto, por exemplo, vim checkpoints/PointLLM_7B_v1.1_init/config.json .
Altere a chave "point_backbone_config_name" para especificar outra configuração do codificador de ponto:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 Edite o caminho do ponto de verificação do codificador de ponto em scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 para conversar sobre modelos 3D do Objaverse. Os pontos de verificação do modelo serão baixados automaticamente. Você também pode baixar manualmente os pontos de verificação do modelo e especificar seus caminhos. Aqui está um exemplo: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 Você também pode modificar facilmente os códigos para usar nuvens de pontos diferentes daqueles do Objaverse, desde que as nuvens de pontos inseridas no modelo tenham dimensões (N, 6), onde as três primeiras dimensões são xyz e as três últimas dimensões são rgb ( na faixa [0, 1]). Você pode obter uma amostra das nuvens de pontos para ter 8.192 pontos, pois nosso modelo é treinado nessas nuvens de pontos.
A tabela a seguir mostra os requisitos de GPU para diferentes modelos e tipos de dados. Recomendamos usar torch.bfloat16 se aplicável, que é usado nos experimentos de nosso artigo.
| Modelo | Tipo de dados | Memória GPU |
|---|---|---|
| PontoLLM-7B | tocha.float16 | 14 GB |
| PontoLLM-7B | tocha.float32 | 28 GB |
| PontoLLM-13B | tocha.float16 | 26 GB |
| PontoLLM-13B | tocha.float32 | 52 GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation como um ditado com o seguinte formato: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C . Isso salvará os resultados temporários. Se ocorrer um erro durante a avaliação, o script também salvará o estado atual. Você pode retomar a avaliação de onde parou executando o mesmo comando novamente.{model_name}/evaluation como outro dict. Algumas das métricas são explicadas a seguir: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval e especificando --gpt_type . Por exemplo: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputContribuições da comunidade são bem-vindas!? Se precisar de suporte, sinta-se à vontade para abrir um problema ou entrar em contato conosco.
Se você achar nosso trabalho e esta base de código úteis, considere marcar este repositório com estrela. e citar:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
Este trabalho está sob a licença Creative Commons Atribuição-NãoComercial-Compartilhamento pela mesma Licença 4.0 Internacional.
Juntos, vamos tornar o LLM para 3D excelente!


