Q Bench
1.0.0
Como funcionam os LLMs multimodais na visão computacional de baixo nível?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 Universidade Tecnológica de Nanyang, 2 Universidade Shanghai Jiaotong, 3 Sensetime Research
* Contribuição igual. # Autor correspondente.
Refletor ICLR2024
Papel | Página do Projeto | GitHub | Dados (LLVisionQA) | Dados (LLDescribe) |质衡 (Chinês-Q-Bench)


O Q-Bench proposto inclui três domínios para visão de baixo nível: percepção (A1), descrição (A2) e avaliação (A3).
Para percepção (A1)/descrição (A2), coletamos dois conjuntos de dados de benchmark LLVisionQA/LLDescribe.
Estamos abertos à avaliação baseada em submissões para as duas tarefas. Os detalhes para envio são os seguintes.
Para avaliação (A3), como usamos conjuntos de dados públicos , fornecemos um código de avaliação abstrato para MLLMs arbitrários para qualquer pessoa testar.
datasets Para o Q-Bench-A1 (com questões de múltipla escolha), nós os convertemos em conjuntos de dados no formato HF que podem ser baixados automaticamente e usados com a API datasets . Consulte as seguintes instruções:
conjuntos de dados de instalação pip
de conjuntos de dados importar load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'Como está a iluminação deste edifício?',### 'opção0': 'Alto',### 'opção1': 'Baixo',### 'opção2': 'Médio',### 'opção3': 'N/A', ### 'question_type': 2,### 'question_concern': 3,### 'correct_choice': 'B'} de conjuntos de dados importar load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image modo de imagem = tamanho RGB = 4032x3024>,### 'image2': <imagem PIL.JpegImagePlugin.JpegImageFile mode=RGB size=864x1152>,### 'question': 'Comparado com a primeira imagem, como está a clareza da segunda imagem?',### 'option0': 'Mais desfocado',### 'option1 ': 'Mais claro',### 'option2': 'Sobre o mesmo',### 'option3': 'N/A',### 'question_type': 2,### 'question_concern': 0,### 'correct_choice': 'B'}[2024/8/8] A parte da tarefa de comparação de visão de baixo nível do Q-bench + (também conhecido como Q-Bench2) acaba de ser aceita pelo TPAMI! Venha testar seu MLLM com Q-bench+_Dataset.
[2024/8/1] O Q-Bench foi lançado no VLMEvalKit, venha e teste seu LMM com um comando como `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
[2024/6/17] O Q-Bench , Q-Bench2 (Q-bench +) e A-Bench agora se juntaram ao lmms-eval, o que torna mais fácil testar o LMM !!
[2024/6/3] O repositório Github para A-Bench está online. Você quer descobrir se o seu LMM é mestre na avaliação de imagens geradas por IA? Venha testar no A-Bench !!
[3/1] Estamos lançando o Co-instruct , Rumo à comparação aberta de qualidade visual aqui. Mais detalhes estarão disponíveis em breve.
[2/27] Nosso trabalho Q-Insturct foi aceito pelo CVPR 2024, tente aprender os detalhes sobre como instruir MLLMs sobre visão de baixo nível!
[2/23] A parte da tarefa de comparação de visão de baixo nível do Q-bench + agora foi lançada no Q-bench + (Dataset)!
[2/10] Estamos lançando o Q-bench+ estendido, que desafia os MLLMs com imagens únicas e pares de imagens em visão de baixo nível. O LeaderBoard está no local, confira a capacidade de visão de baixo nível para seus MLLMs favoritos!! Mais detalhes em breve.
[1/16] Nosso trabalho "Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision" foi aceito pelo ICLR2024 como Spotlight Presentation .

Testamos em três modelos de API de código próximo, GPT-4V-Turbo ( gpt-4-vision-preview , substituindo os resultados da versão antiga do GPT-4V que não estão mais disponíveis), Gemini Pro ( gemini-pro-vision ) e Qwen -VL-Plus ( qwen-vl-plus ). Ligeiramente melhorado em comparação com a versão mais antiga, o GPT-4V ainda está no topo entre todos os MLLMs e no desempenho de quase um ser humano de nível júnior. Gemini Pro e Qwen-VL-Plus seguem atrás, ainda melhores que os melhores MLLMs de código aberto (0,65 no geral).
Atualização em [2024/7/18], temos o prazer de lançar o novo desempenho SOTA do BlueImage-GPT (código próximo).
Percepção, A1-Single
| Nome do participante | sim ou não | o que | como | distorção | outros | distorção no contexto | outros no contexto | geral |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,7574 | 0,7325 | 0,5733 | 0,6488 | 0,7324 | 0,6867 | 0,7056 | 0,6893 |
BlueImage-GPT ( from VIVO Novo Campeão ) | 0,8467 | 0,8351 | 0,7469 | 0,7819 | 0,8594 | 0,7995 | 0,8240 | 0,8107 |
Gêmeos-Pro ( gemini-pro-vision ) | 0,7221 | 0,7300 | 0,6645 | 0,6530 | 0,7291 | 0,7082 | 0,7665 | 0,7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0,7722 | 0,7839 | 0,6645 | 0,7101 | 0,7107 | 0,7936 | 0,7891 | 0,7410 |
| GPT-4V ( versão antiga ) | 0,7792 | 0,7918 | 0,6268 | 0,7058 | 0,7303 | 0,7466 | 0,7795 | 0,7336 |
| humano-1-júnior | 0,8248 | 0,7939 | 0,6029 | 0,7562 | 0,7208 | 0,7637 | 0,7300 | 0,7431 |
| humano-2-sênior | 0,8431 | 0,8894 | 0,7202 | 0,7965 | 0,7947 | 0,8390 | 0,8707 | 0,8174 |
Percepção, Par A1
| Nome do participante | sim ou não | o que | como | distorção | outros | comparar | articulação | geral |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,6685 | 0,5579 | 0,5991 | 0,6246 | 0,5877 | 0,6217 | 0,5920 | 0,6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0,6765 | 0,6756 | 0,6535 | 0,6909 | 0,6118 | 0,6865 | 0,6129 | 0,6699 |
BlueImage-GPT ( from VIVO Novo Campeão ) | 0,8843 | 0,8033 | 0,7958 | 0,8464 | 0,8062 | 0,8462 | 0,7955 | 0,8348 |
Gêmeos-Pro ( gemini-pro-vision ) | 0,6578 | 0,5661 | 0,5674 | 0,6042 | 0,6055 | 0,6046 | 0,6044 | 0,6046 |
GPT-4V ( gpt-4-vision ) | 0,7975 | 0,6949 | 0,8442 | 0,7732 | 0,7993 | 0,8100 | 0,6800 | 0,7807 |
| Humano de nível júnior | 0,7811 | 0,7704 | 0,8233 | 0,7817 | 0,7722 | 0,8026 | 0,7639 | 0,8012 |
| Humano de nível sênior | 0,8300 | 0,8481 | 0,8985 | 0,8313 | 0,9078 | 0,8655 | 0,8225 | 0,8548 |
Também avaliamos recentemente vários novos modelos de código aberto e divulgaremos seus resultados em breve.
Agora fornecemos duas maneiras de baixar os conjuntos de dados (LLVisionQA e LLDescribe)
via GitHub Release: Consulte nosso lançamento para obter detalhes.
via conjuntos de dados Huggingface: consulte as notas de lançamento de dados para baixar as imagens.
É altamente recomendável converter seu modelo para o formato Huggingface para testar esses dados sem problemas. Veja os scripts de exemplo do IDEFICS-9B-Instruct do Huggingface como exemplo e modifique-os para que seu modelo personalizado seja testado em seu modelo.
Envie um e-mail para [email protected] para enviar seu resultado em formato json.
Você também pode enviar seu modelo (pode ser Huggingface AutoModel ou ModelScope AutoModel) para nós, junto com seus scripts de avaliação personalizados. Seus scripts personalizados podem ser modificados a partir dos scripts de modelo que funcionam para LLaVA-v1.5 (para A1/A2) e aqui (para avaliação de qualidade de imagem).
Envie um e-mail para [email protected] para enviar seu modelo se você estiver fora da China continental. Envie um e-mail para [email protected] para enviar seu modelo se você estiver na China continental.
Um instantâneo do conjunto de dados de referência LLVisionQA para capacidade de percepção de baixo nível de MLLM é o seguinte. Veja a tabela de classificação aqui.
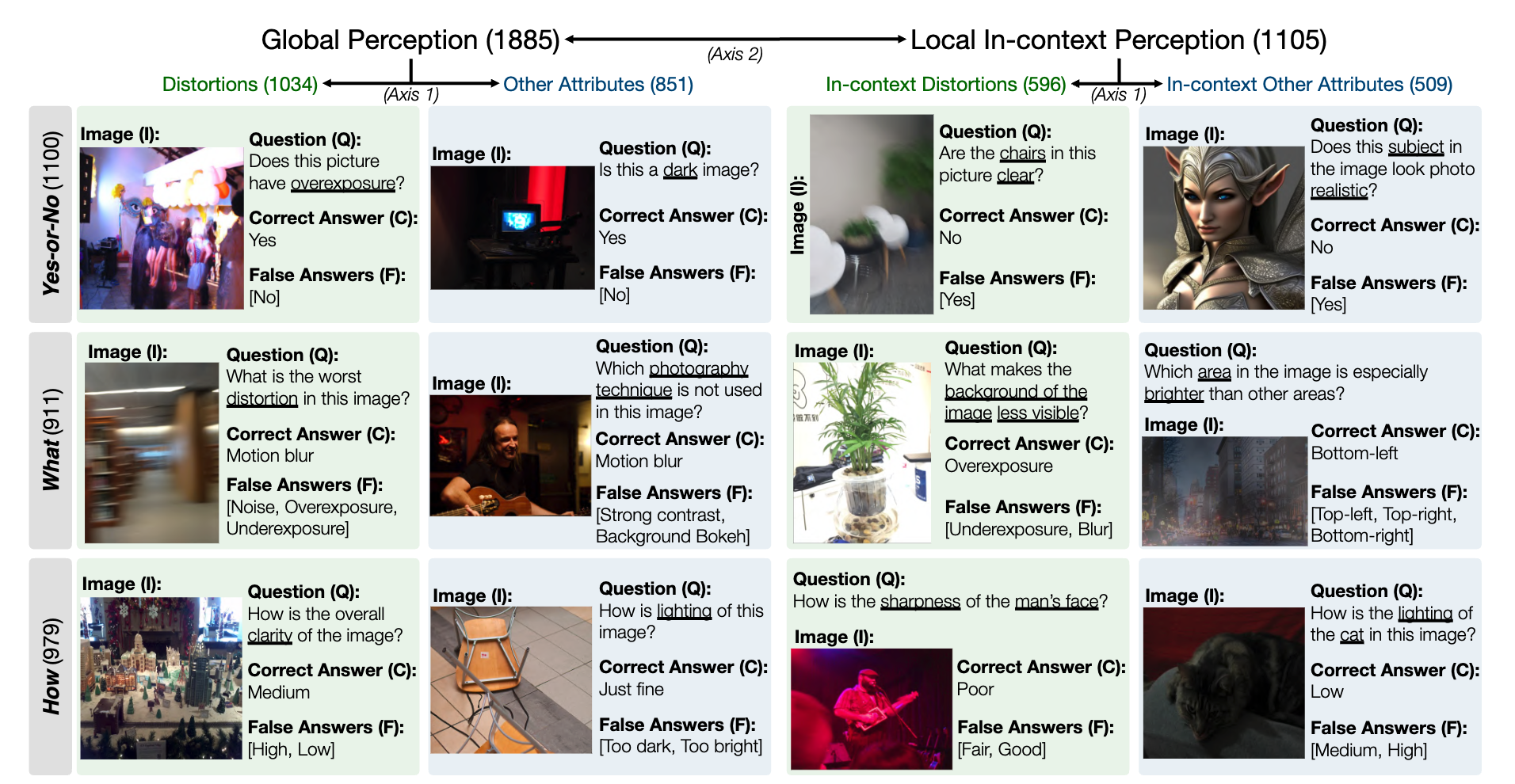
Medimos a precisão da resposta dos MLLMs (fornecidos com a pergunta e todas as opções) como a métrica aqui.
Um instantâneo do conjunto de dados de benchmark LLDescribe para capacidade de descrição de baixo nível do MLLM é o seguinte. Veja a tabela de classificação aqui.

Medimos a integridade , a precisão e a relevância das descrições do MLLM como métrica aqui.
Uma habilidade interessante que os MLLMs são capazes de prever pontuações quantitativas para IQA!
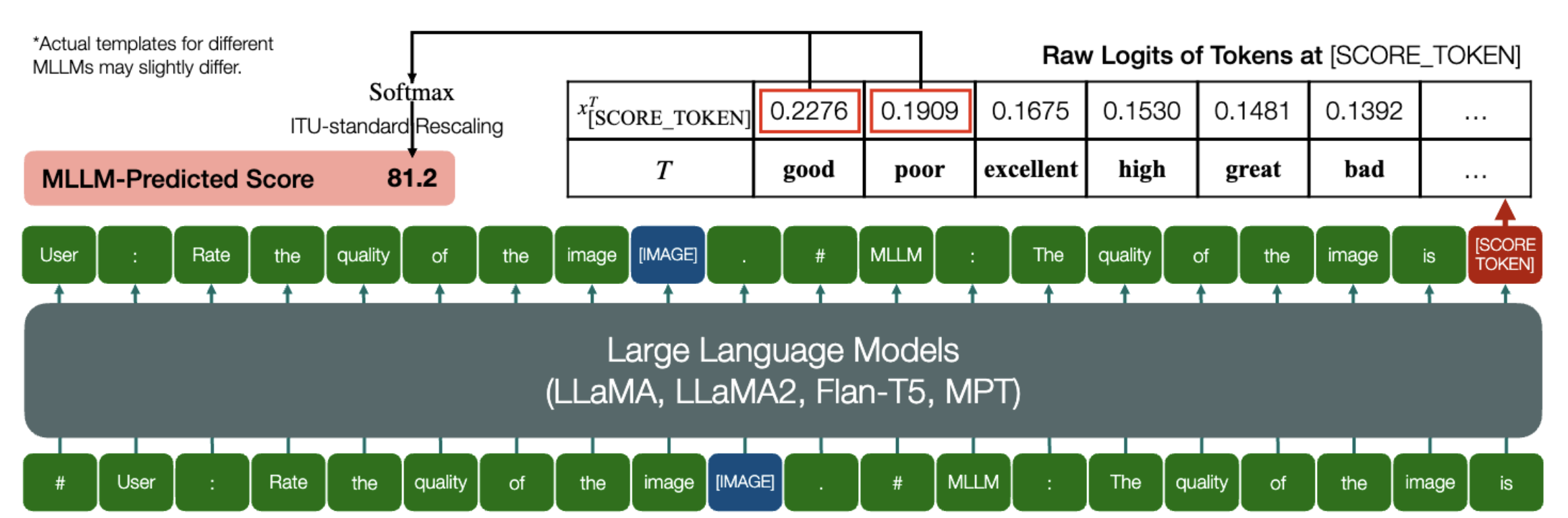
Da mesma forma que acima, desde que um modelo (baseado em modelos de linguagem causal) tenha os dois métodos a seguir: embed_image_and_text (para permitir entradas multimodais) e forward (para computar logits), a Avaliação de Qualidade de Imagem (IQA) com o modelo pode ser alcançado da seguinte forma:
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: Classifique a qualidade da imagem.n"
"##Assistant: A qualidade da imagem é" ### Esta linha pode ser modificada com base no comportamento padrão do MLLM.good_idx, pobre_idx = tokenizer(["good","poor"]).tolist()image = Image. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(image, prompt)output_logits = modelo(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[bom_idx, pobre_idx]] / 100).softmax(0)[0]*Observe que você pode modificar a segunda linha com base no formato padrão do seu modelo, por exemplo , para Shikra, o "##Assistente: A qualidade da imagem é" é modificado como "##Assistente: A resposta é". Não há problema se o seu MLLM responder primeiro "Ok, gostaria de ajudar! A qualidade da imagem é", basta substituir na linha 2 do prompt.
Fornecemos ainda uma implementação completa do IDEFICS no IQA. Veja exemplo de como executar IQA com este MLLM. Outros MLLMs também podem ser modificados da mesma forma para uso no IQA.
Preparamos pontuações de opinião humana (MOS) em formato JSON para os sete bancos de dados IQA avaliados em nosso benchmark.
Consulte IQA_databases para obter detalhes.
Movido para tabelas de classificação. Por favor clique para ver detalhes.
Entre em contato com qualquer um dos primeiros autores deste artigo para dúvidas.
Haoning Wu, [email protected] , @teowu
Zicheng Zhang, [email protected] , @zzc-1998
Erli Zhang, [email protected] , @ZhangErliCarl
Se você achar nosso trabalho interessante, sinta-se à vontade para citar nosso artigo:
@inproceedings{wu2024qbench,autor = {Wu, Haoning e Zhang, Zicheng e Zhang, Erli e Chen, Chaofeng e Liao, Liang e Wang, Annan e Li, Chunyi e Sun, Wenxiu e Yan, Qiong e Zhai, Guangtao e Lin, Weisi},title = {Q-Bench: uma referência para modelos básicos de uso geral em visão de baixo nível},booktitle = {ICLR}, ano = {2024}} 

