llm4data
v0.0.9
LLM4Data é uma biblioteca Python projetada para facilitar a aplicação de grandes modelos de linguagem (LLMs) e inteligência artificial para desenvolvimento de dados e descoberta de conhecimento. O objetivo é capacitar usuários e organizações a descobrir e interagir com dados de desenvolvimento de maneiras inovadoras por meio de linguagem natural.
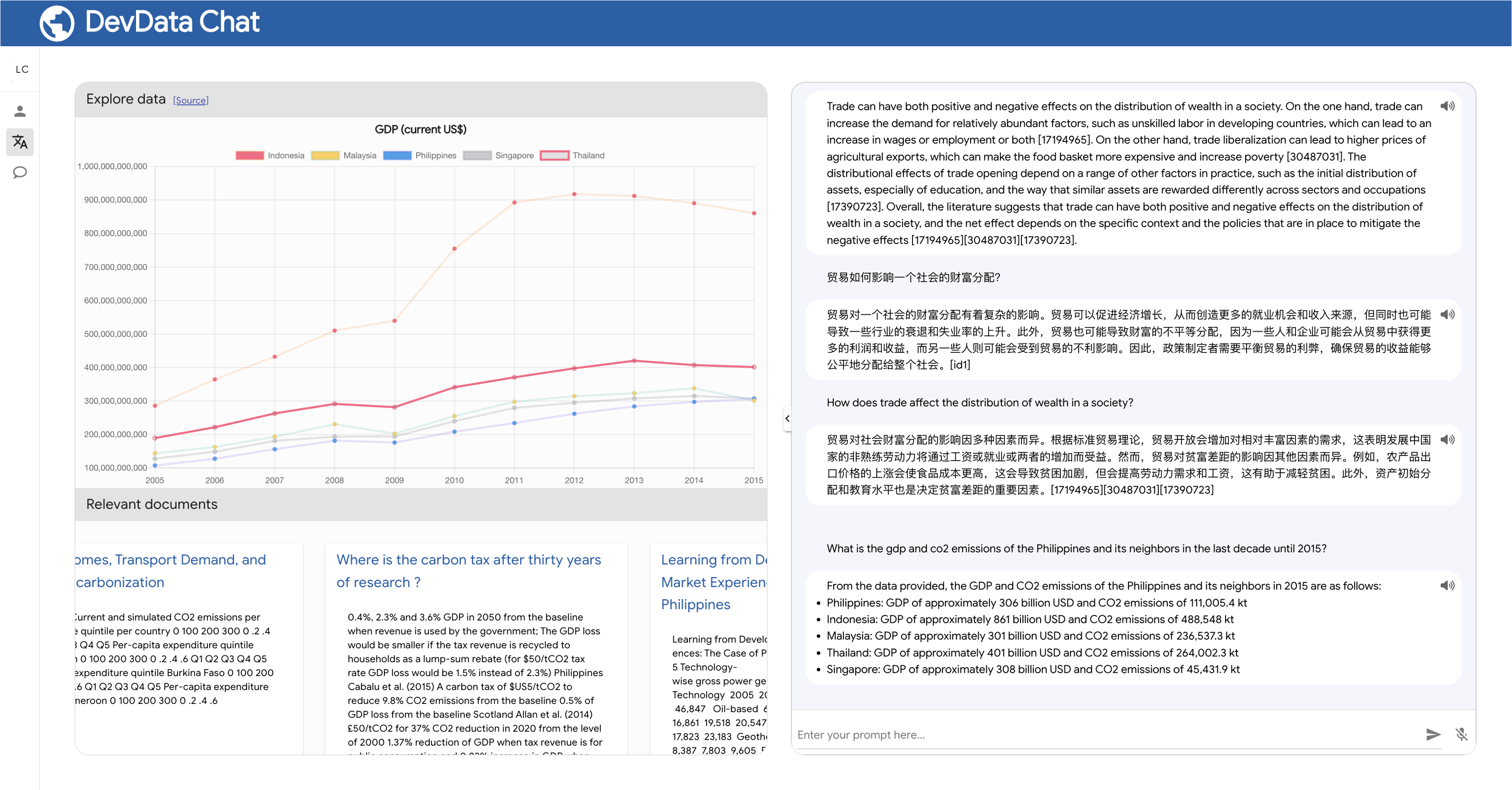
O LLM4Data alimenta o aplicativo DevData Chat, que em breve estará disponível como um projeto de código aberto. Esta aplicação demonstra as diversas maneiras pelas quais o LLM (Modelo de Linguagem) e a IA melhoram a descoberta e a interação com dados e conhecimento, trazendo soluções inovadoras para ajudar a resolver lacunas de descoberta e acessibilidade.
A biblioteca LLM4Data contém uma coleção de soluções de descoberta e aumento de dados para vários tipos de dados, incluindo documentos, indicadores, microdados, dados geoespaciais e muito mais. A versão atual da biblioteca inclui soluções para os indicadores WDI. Soluções adicionais serão adicionadas em versões futuras.
Construído em torno de padrões e esquemas de metadados existentes, usuários e organizações podem se beneficiar dos LLMs para aprimorar aplicativos orientados a dados, permitindo processamento de linguagem natural, geração de texto e muito mais com LLM4Data. A biblioteca serve como uma ponte entre LLMs e dados de desenvolvimento usando bibliotecas de código aberto, oferecendo uma interface perfeita para aproveitar os recursos desses poderosos modelos de linguagem.
Use o gerenciador de pacotes pip para instalar o LLM4Data.
pip install llm4dataOs exemplos a seguir demonstram como usar LLM4Data para gerar URLs de API WDI e consultas SQL a partir de prompts.
Exemplos adicionais podem ser encontrados aqui.
This example uses the OpenAI API. Before you proceed, make sure to set your API keys in the `.env` file. See the [setup instructions](https://worldbank.github.io/llm4data/notebooks/examples/getting-started/openai-api.html) for more details.
from llm4data . prompts . indicators import wdi
# Create a WDI API prompt object
wdi_api = wdi . WDIAPIPrompt ()
# Send a prompt to the LLM to get a WDI API URL relevant to the prompt
response = wdi_api . send_prompt (
"What is the gdp and the co2 emissions of the philippines and its neighbors in the last decade?"
)
# Parse the response to get the WDI API URL
wdi_api_url = wdi_api . parse_response ( response )
print ( wdi_api_url )A saída será semelhante a esta:
https://api.worldbank.org/v2/country/PHL;IDN;MYS;SGP;THA;VNM/indicator/NY.GDP.MKTP.CD;EN.ATM.CO2E.KT?date=2013:2022&format=json&source=2
Observe que a URL gerada já inclui os códigos de país e indicadores relevantes para o prompt. Compreende quais países são vizinhos das Filipinas. Também compreende quais códigos de indicadores são suscetíveis de fornecer os dados relevantes sobre o PIB e as emissões de CO2.
O URL também inclui o intervalo de datas, formato e fonte dos dados. O usuário pode então ajustar o URL conforme necessário e usá-lo para consultar a API WDI.
Make sure you have set up your environment first. The example below requires a working database engine, e.g., postgresql. If you want to use SQLite, make sure to update the `.env` file and set the environment variables.
Embora os dados WDI possam ser carregados em um dataframe do Pandas, nem sempre é prático fazê-lo; por exemplo, desenvolvendo aplicativos que possam responder a questões de dados arbitrárias.
A biblioteca LLM4Data inclui uma interface SQL para dados WDI, permitindo aos usuários consultar os dados usando SQL.
Esta interface permitirá aos usuários consultar os dados usando SQL e retornar os resultados como um dataframe do Pandas. A interface também permite aos usuários consultar os dados usando SQL e retornar os resultados como um objeto JSON.
import json
from llm4data . prompts . indicators import templates , wdi
from llm4data . llm . indicators import wdi_sql
prompt = "What is the GDP and army spending of the Philippines in 2020?"
sql_data = wdi_sql . WDISQL (). llm2sql_answer ( prompt , as_dict = True )
print ( sql_data )
# # {'sql': "SELECT country, value AS gdp, (SELECT value FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'MS.MIL.XPND.GD.ZS' AND year = 2020) AS army_spending FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'NY.GDP.MKTP.CD' AND year = 2020 AND value IS NOT NULL",
# # 'params': {},
# # 'data': {'data': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}],
# # 'sample': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}]},
# # 'num_samples': 20}A biblioteca LLM4Data também inclui suporte para gerar explicações narrativas de respostas de consultas SQL. Isso é útil para gerar descrições de dados em linguagem natural, que podem ser usadas para fornecer contexto aos usuários e explicar os resultados de consultas de dados.
from llm4data . prompts . indicators import templates
# Send the prompt to the LLM for a narrative explanation of the response.
# This is optional and can be skipped.
# Note that we pass only a sample in the `context_data`.
# This could limit the quality of the response.
# This is a limitation of the current version of the LLM which is constrained by the context length and cost.
explainer = templates . IndicatorPrompt ()
description = explainer . send_prompt ( prompt = prompt , context_data = json . dumps ( sql_data [ "data" ][ "sample" ]))
print ( description [ "content" ])
# # Based on the data provided, the GDP of the Philippines in 2020 was approximately 362 billion USD. Meanwhile, the country's army spending in the same year was around 1.01 billion USD. It is worth noting that while army spending is an important aspect of a country's budget, it is not the only factor that contributes to its economic growth and development. Other factors such as infrastructure, education, and healthcare also play a crucial role in shaping a country's economy. Langchain é uma ótima biblioteca e possui um wrapper para bancos de dados SQL que permite consultá-los usando linguagem natural. O wrapper é chamado SQLDatabaseChain e pode ser usado da seguinte maneira:
from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "sqlite:///../llm4dev/data/sqldb/wdi.db" )
llm = OpenAI ( temperature = 0 , verbose = True )
db_chain = SQLDatabaseChain . from_llm ( llm , db , verbose = True , return_intermediate_steps = True )
out = db_chain ( "What is the GDP and army spending of the Philippines in 2020?" ) > Entering new SQLDatabaseChain chain...
What is the GDP and army spending of the Philippines in 2020 ?
SQLQuery:SELECT " value " FROM wdi WHERE " name " = ' GDP (current US$) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
UNION
SELECT " value " FROM wdi WHERE " name " = ' Military expenditure (% of GDP) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
SQLResult: [(1.01242392260698,), (361751116292.541,)]
Answer:The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541.
> Finished chain. Infelizmente, a resposta The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541. está incorreto porque os valores foram trocados.
Um dos objetivos do LLM4Data é desenvolver soluções em torno das limitações das soluções de código aberto existentes aplicadas a dados de desenvolvimento e descoberta de conhecimento.
Solicitações pull são bem-vindas. Para mudanças importantes, abra primeiro uma edição para discutir o que você gostaria de mudar.
Consulte CONTRIBUTING.md para obter mais informações.
LLM4Data é licenciado sob o Contrato de Licença Comunitária Master do Banco Mundial.


