LLM PuzzleTest
1.0.0
PuzzleVQA, nosso novo conjunto de dados revela sérios desafios dos LLMs multimodais na compreensão de padrões abstratos simples. Papel | Site
Estamos lançando AlgoPuzzleVQA, um conjunto de dados novo e desafiador para raciocínio multimodal! Em breve, lançaremos mais conjuntos de dados de quebra-cabeças multimodais. Fique atento! Papel | Site
Temos o prazer de anunciar o lançamento de dois novos conjuntos de dados VQA centrados em quebra-cabeças:
O desempenho dos MLLMs em ambos os conjuntos de dados é notavelmente deficiente, sublinhando a necessidade premente de melhorias substanciais nas suas capacidades de raciocínio multimodal.
Grandes modelos multimodais ampliam as capacidades impressionantes de grandes modelos de linguagem, integrando habilidades de compreensão multimodal. No entanto, não está claro como eles podem emular a inteligência geral e a capacidade de raciocínio dos humanos. Como reconhecer padrões e abstrair conceitos são fundamentais para a inteligência geral, apresentamos o PuzzleVQA, uma coleção de quebra-cabeças baseados em padrões abstratos. Com este conjunto de dados, avaliamos grandes modelos multimodais com padrões abstratos baseados em conceitos fundamentais, incluindo cores, números, tamanhos e formas. Através de nossos experimentos em grandes modelos multimodais de última geração, descobrimos que eles não são capazes de generalizar bem para padrões abstratos simples. Notavelmente, mesmo o GPT-4V não consegue resolver mais da metade dos quebra-cabeças. Para diagnosticar os desafios de raciocínio em grandes modelos multimodais, orientamos progressivamente os modelos com nossas explicações de raciocínio verdadeiro para percepção visual, raciocínio indutivo e raciocínio dedutivo. Nossa análise sistemática constata que os principais gargalos do GPT-4V são a percepção visual mais fraca e as habilidades de raciocínio indutivo. Através deste trabalho, esperamos esclarecer as limitações dos grandes modelos multimodais e como eles podem emular melhor os processos cognitivos humanos no futuro.
PuzzleVQA está disponível aqui e também no Huggingface.
A figura abaixo mostra um exemplo de pergunta que envolve o conceito de cor no PuzzleVQA e uma resposta incorreta do GPT-4V. Geralmente existem três estágios que podem ser observados no processo de resolução: percepção visual (azul), raciocínio indutivo (verde) e raciocínio dedutivo (vermelho). Aqui, a percepção visual estava incompleta, causando um erro durante o raciocínio dedutivo.

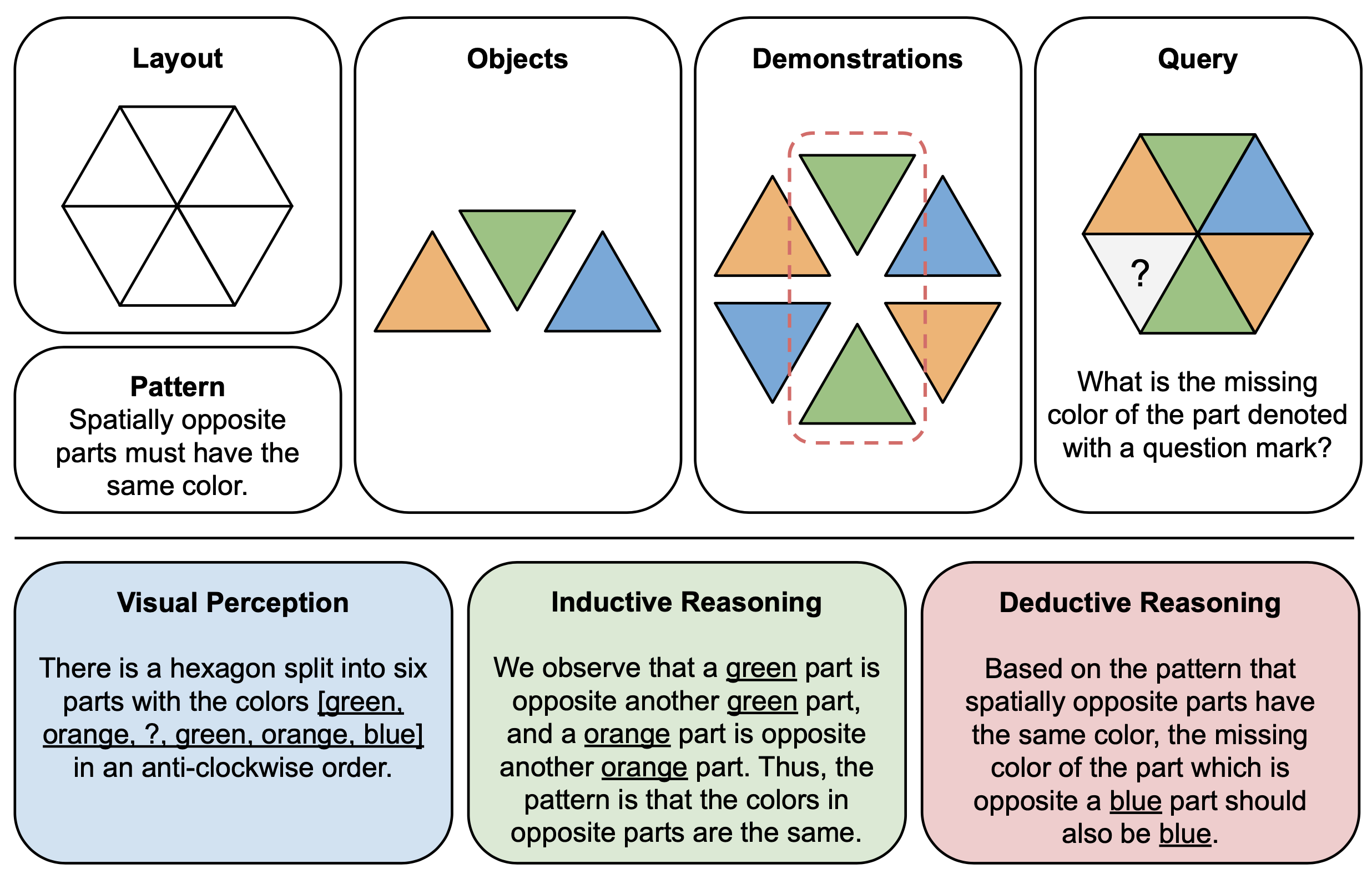
A figura abaixo mostra um exemplo ilustrativo de componentes (parte superior) e explicações de raciocínio (parte inferior) para quebra-cabeças abstratos no PuzzleVQA. Para construir cada instância do quebra-cabeça, primeiro definimos o layout e o padrão de um modelo multimodal e preenchemos o modelo com objetos adequados que demonstram o padrão subjacente. Para facilitar a interpretabilidade, também construímos explicações de raciocínio verdadeiro para interpretar o quebra-cabeça e explicar os estágios gerais da solução.
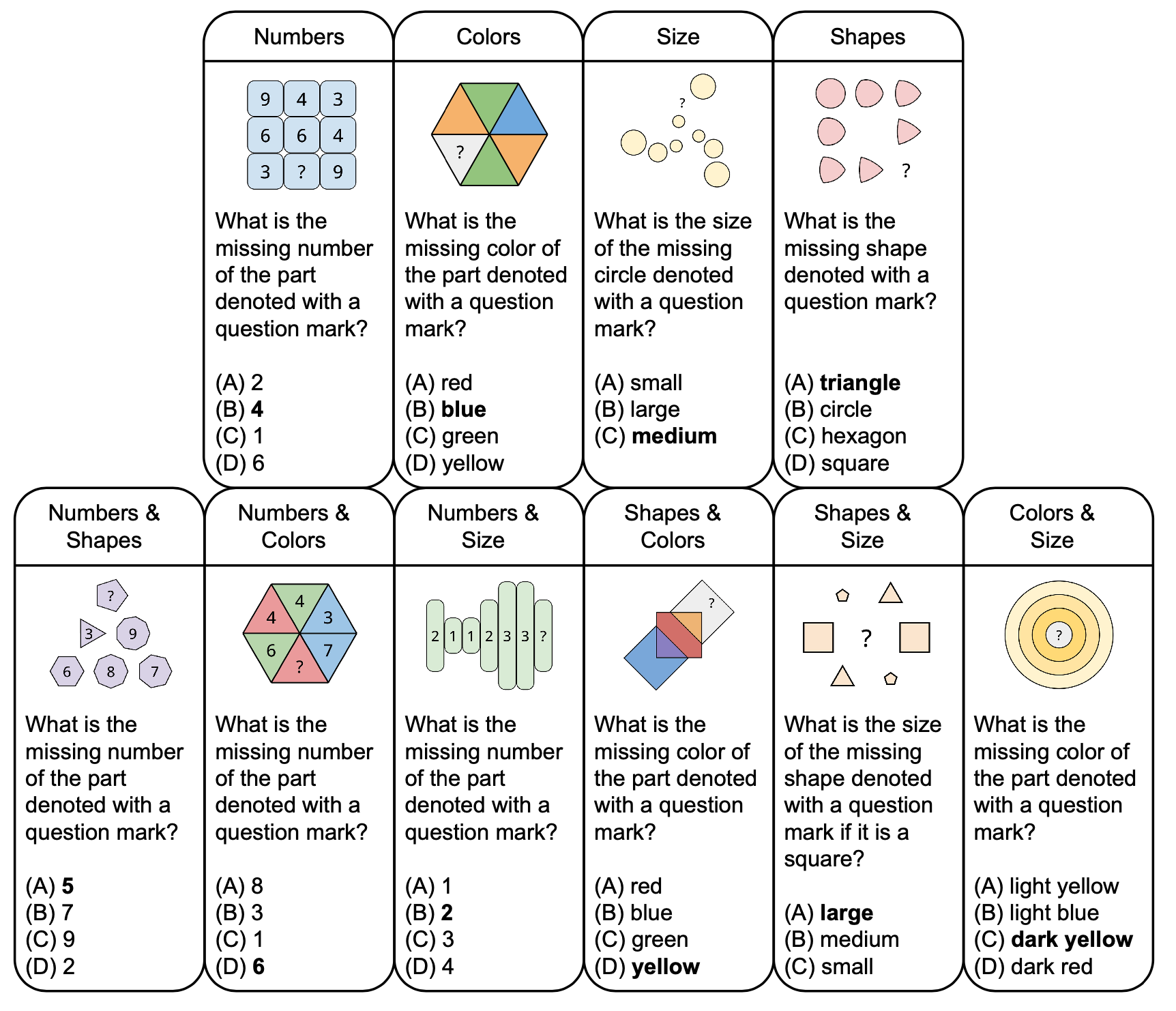
A figura abaixo mostra a taxonomia de quebra-cabeças abstratos no PuzzleVQA com exemplos de perguntas, baseadas em conceitos fundamentais como cores e tamanho. Para aumentar a diversidade, criamos quebra-cabeças de conceito único e de conceito duplo.
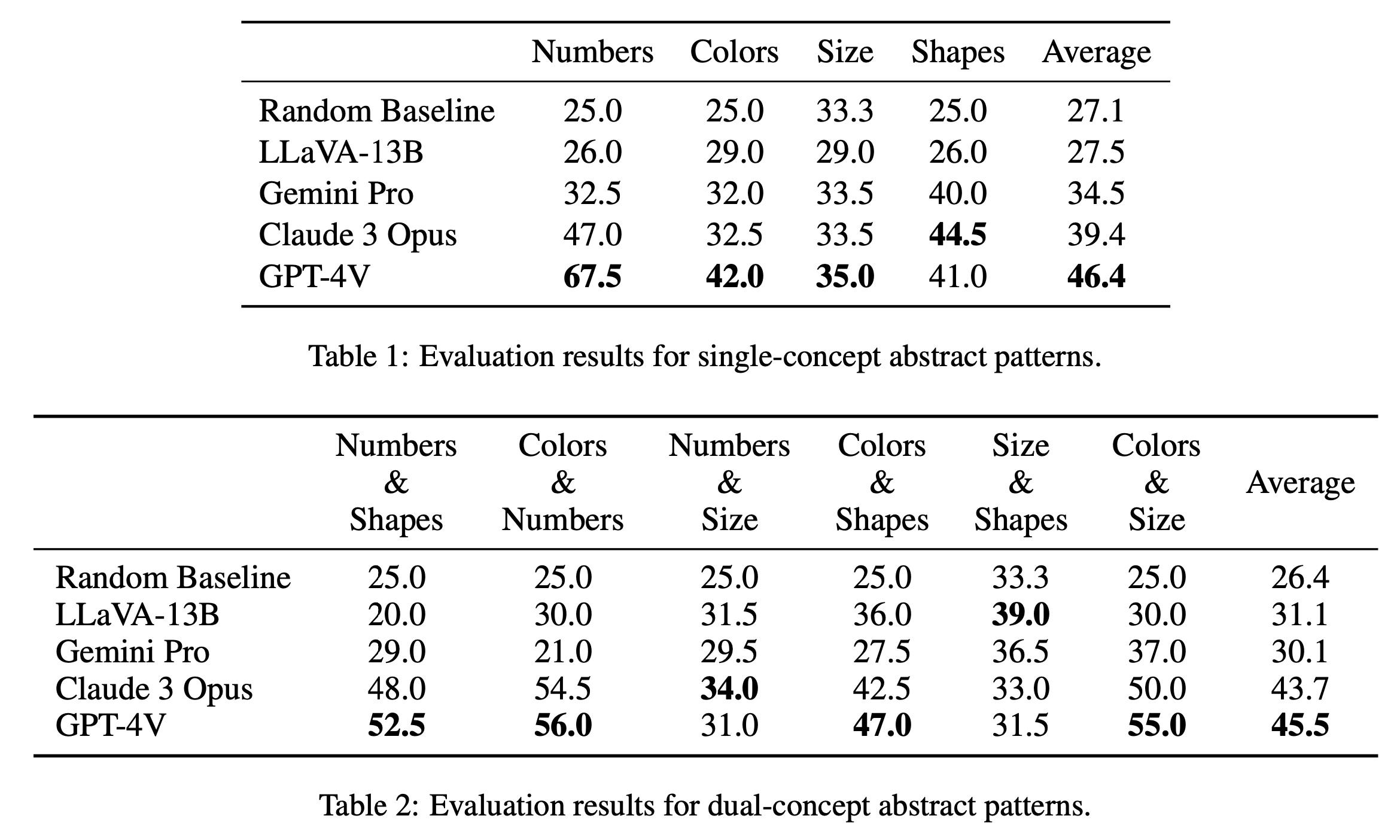
Relatamos os principais resultados da avaliação em quebra-cabeças de conceito único e de conceito duplo na Tabela 1 e na Tabela 2, respectivamente. Os resultados da avaliação para quebra-cabeças de conceito único, conforme mostrado na Tabela 1, revelam diferenças notáveis no desempenho entre os modelos de código aberto e de código fechado. GPT-4V se destaca com a pontuação média mais alta de 46,4, demonstrando raciocínio de padrões abstratos superior em quebra-cabeças de conceito único, como números, cores e tamanho. Destaca-se particularmente na categoria “Números” com uma pontuação de 67,5, superando em muito outros modelos, o que pode ser devido à sua vantagem em tarefas de raciocínio matemático (Yang et al., 2023). Claude 3 Opus segue com média geral de 39,4, mostrando sua força na categoria “Formas” com nota máxima de 44,5. Os outros modelos, incluindo Gemini Pro e LLaVA-13B, ficam atrás com médias de 34,5 e 27,5 respectivamente, apresentando desempenho semelhante à linha de base aleatória em diversas categorias.
Na avaliação dos quebra-cabeças de conceito duplo, conforme mostrado na Tabela 2, o GPT-4V se destaca novamente com a maior pontuação média de 45,5. Teve um desempenho particularmente bom em categorias como "Cores e Números" e "Cores e Tamanho", com uma pontuação de 56,0 e 55,0, respectivamente. Claude 3 Opus segue de perto com média de 43,7, apresentando forte desempenho em "Números e Tamanho" com pontuação máxima de 34,0. Curiosamente, o LLaVA-13B, apesar de sua média geral mais baixa de 31,1, tem a pontuação mais alta na categoria “Tamanho e Formas”, com 39,0. O Gemini Pro, por outro lado, tem um desempenho mais equilibrado entre as categorias, mas com uma média geral ligeiramente inferior de 30,1. No geral, descobrimos que os modelos têm desempenho semelhante, em média, para padrões de conceito único e de conceito duplo, o que sugere que eles são capazes de relacionar vários conceitos, como cores e números.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Apresentamos a nova tarefa de resolução de quebra-cabeças multimodais, enquadrada no contexto da resposta visual a perguntas. Apresentamos um novo conjunto de dados, AlgoPuzzleVQA, projetado para desafiar e avaliar as capacidades de modelos de linguagem multimodais na resolução de quebra-cabeças algorítmicos que exigem compreensão visual, compreensão de linguagem e raciocínio algorítmico complexo. Criamos os quebra-cabeças para abranger uma gama diversificada de tópicos matemáticos e algorítmicos, como lógica booleana, combinatória, teoria dos grafos, otimização, pesquisa, etc., com o objetivo de avaliar a lacuna entre a interpretação visual de dados e as habilidades algorítmicas de resolução de problemas. O conjunto de dados é gerado automaticamente a partir de código de autoria humana. Todos os nossos quebra-cabeças têm soluções exatas que podem ser encontradas no algoritmo sem tediosos cálculos humanos. Isso garante que nosso conjunto de dados possa ser ampliado arbitrariamente em termos de complexidade de raciocínio e tamanho do conjunto de dados. Nossa investigação revela que grandes modelos de linguagem (LLMs), como GPT4V e Gemini, apresentam desempenho limitado em tarefas de resolução de quebra-cabeças. Descobrimos que seu desempenho é quase aleatório em uma configuração de resposta a perguntas de múltipla escolha para um número significativo de quebra-cabeças. As descobertas enfatizam os desafios de integração do conhecimento visual, linguístico e algorítmico para resolver problemas complexos de raciocínio.
PuzzleVQA está disponível aqui e também no Huggingface.
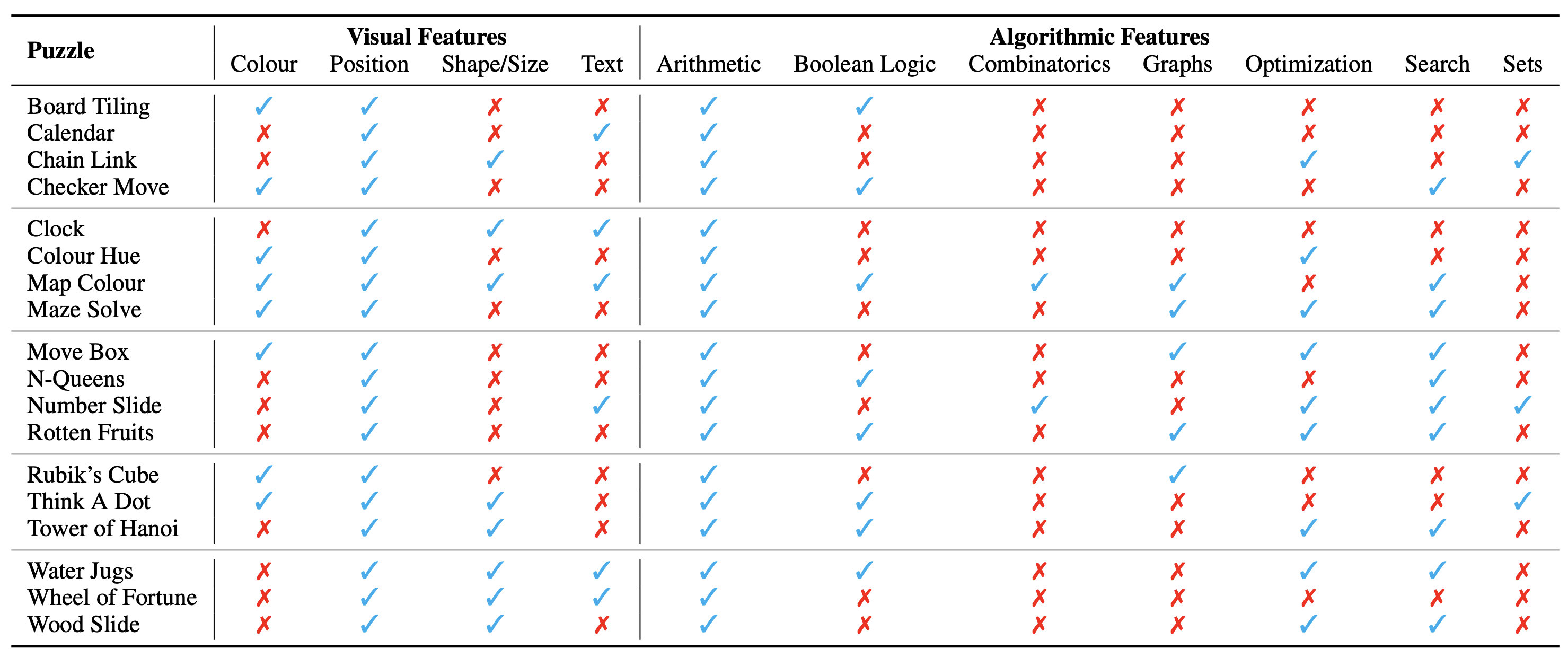
A configuração do quebra-cabeça/problema é apresentada como uma imagem, que constitui seu contexto visual. Identificamos os seguintes aspectos fundamentais do contexto visual que influenciam a natureza dos quebra-cabeças:

Também identificamos os conceitos algorítmicos necessários para resolver os quebra-cabeças, ou seja, para responder às perguntas das instâncias do quebra-cabeça. Eles são os seguintes:

As categorias algorítmicas não são mutuamente exclusivas, pois precisamos usar duas ou mais categorias para derivar a resposta para a maioria dos quebra-cabeças.
O conjunto de dados está disponível aqui neste formato. Criamos um total de 18 quebra-cabeças diferentes abrangendo vários tópicos algorítmicos e matemáticos. Muitos desses quebra-cabeças são populares em vários ambientes recreativos ou acadêmicos.
No total, temos 1.800 instâncias dos 18 quebra-cabeças diferentes. Essas instâncias são análogas a diferentes casos de teste do quebra-cabeça, ou seja, possuem diferentes combinações de entrada, estados iniciais e de meta, etc. A solução confiável de todas as instâncias exigiria encontrar o algoritmo exato a ser usado e, em seguida, aplicá-lo com precisão. Isto é semelhante à forma como verificamos a precisão de um programa de computador que visa resolver uma tarefa específica através de uma ampla gama de casos de teste.
Atualmente consideramos o conjunto de dados completo como uma referência apenas para avaliação . Os exemplos detalhados de todos os quebra-cabeças são mostrados aqui.
Instruções para gerar o conjunto de dados podem ser encontradas aqui. O número de instâncias e a dificuldade dos quebra-cabeças podem ser dimensionados arbitrariamente para qualquer tamanho ou nível desejado.
A categorização ontológica dos quebra-cabeças é a seguinte:
A configuração experimental e os scripts podem ser encontrados no diretório AlgoPuzzleVQA.
Considere citar o seguinte artigo se você achou nosso trabalho útil:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

