DiagGPT
1.0.0
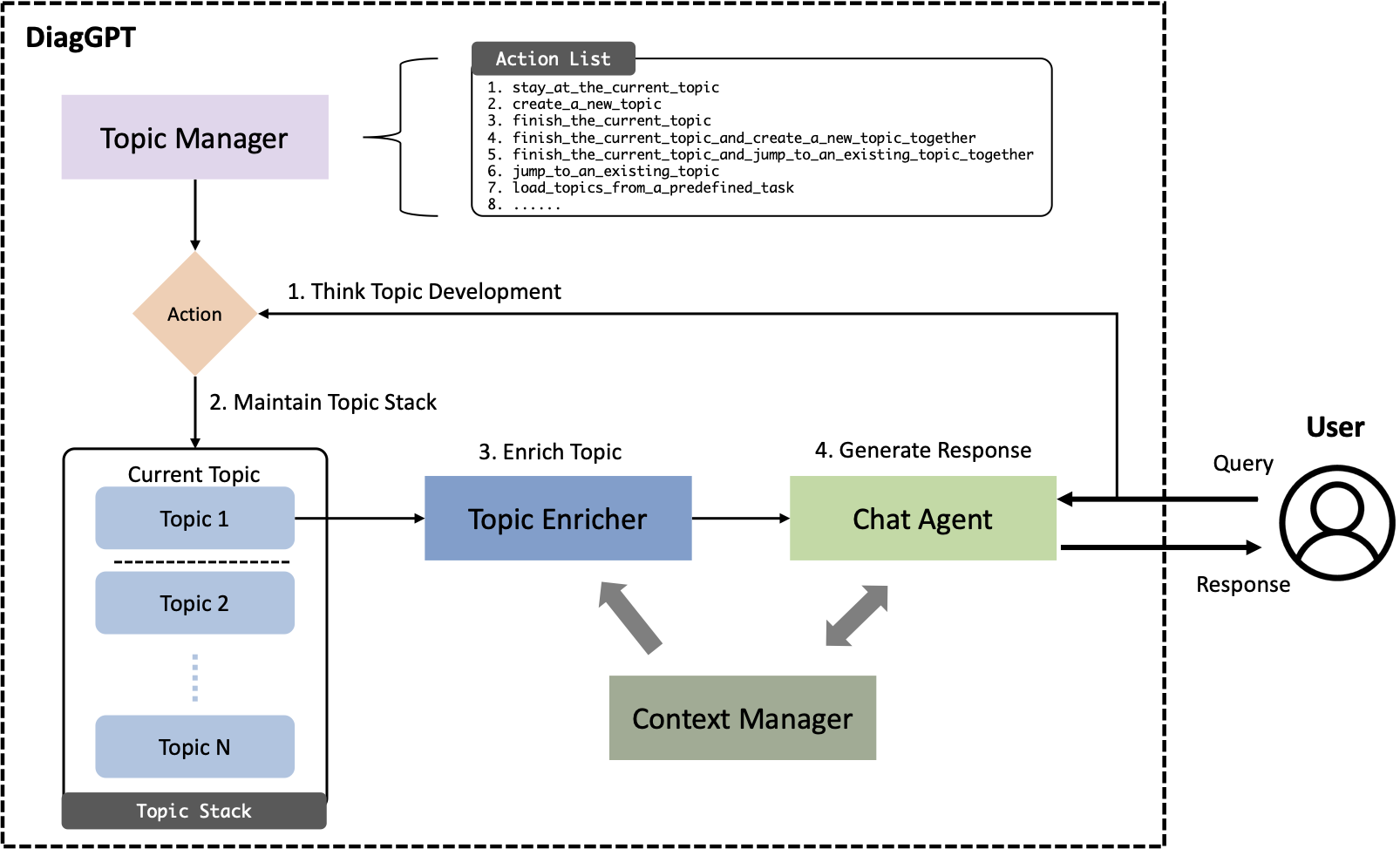
Uma aplicação significativa de Large Language Models (LLMs), como ChatGPT, é sua implantação como agentes de chat, que respondem a consultas humanas em vários domínios. Embora os LLMs atuais respondam com proficiência a perguntas gerais, eles muitas vezes ficam aquém em cenários diagnósticos complexos, como consultas jurídicas, médicas ou outras consultas especializadas. Esses cenários normalmente exigem Diálogo Orientado a Tarefas (TOD), em que um agente de chat de IA deve fazer perguntas proativamente e orientar os usuários em direção a metas específicas ou à conclusão de tarefas. Os modelos anteriores de ajuste fino tiveram desempenho inferior em TOD e todo o potencial da capacidade de conversação nos LLMs atuais ainda não foi totalmente explorado. Neste artigo, apresentamos o DiagGPT (Dialogue in Diagnosis GPT), uma abordagem inovadora que estende LLMs a mais cenários TOD. Além de orientar os usuários na conclusão das tarefas, o DiagGPT pode gerenciar com eficácia o status de todos os tópicos durante o desenvolvimento do diálogo. Este recurso aprimora a experiência do usuário e oferece uma interação mais flexível no TOD. Nossos experimentos demonstram que o DiagGPT apresenta excelente desempenho na condução de TOD com usuários, mostrando seu potencial para aplicações práticas em diversos campos.
Construímos um novo conjunto de dados, LLM-TOD (diálogo orientado a tarefas para conjuntos de dados de modelos de linguagem grandes). É usado para avaliar quantitativamente o desempenho de modelos de diálogo orientados a tarefas baseados em LLM. O conjunto de dados é composto por 20 dados, cada um representando um tema diferente: clínica, restaurante, hotel, hospital, trem, polícia, ônibus, atração, aeroporto, bar, biblioteca, museu, parque, academia, cinema, escritório, barbearia, padaria, zoológico, e banco.
.
├── chatgpt # implementation of base chatgpt
├── data
│ └── LLM-TOD # LLM-TOD dataset
├── demo.py # DiagGPT for demo test
├── diaggpt # simple version of DiagGPT for quantitative experiments
├── diaggpt_medical # full version of DiagGPT in the medical consulting scenario
│ ├── embedding # file store, retrieval, etc.
│ ├── main.py # main code of implementation
│ ├── prompts # all prompts in DiagGPT
│ ...
├── evalgpt # implementation of GPT evaluation
├── exp.py # code of quantitative experiments
├── exp_output # experiment results
├── openai_api_key.txt # openai key
├── requirements.txt # dependencies
├── usergpt # simulation of the user for quantitative experiments
...pip install -r requirements.txttouch openai_api_key.txt # put your openai api key in it
python demo.py # demo test
python exp.py # run quantitative experimentsAqui está uma demonstração muito simples do processo de chat do chatbot em um cenário de diagnóstico médico. Simulamos o processo de um paciente visitando um médico. (Algumas entradas do paciente/usuário são geradas pelo GPT-4.)
Nesse processo, o médico está constantemente coletando informações dos pacientes e analisando-as passo a passo
Actualmente, as funções existentes do projecto são muito preliminares. É apenas uma versão de demonstração para mostrar a capacidade de gerenciamento de tópicos dos LLMs, que não pode atender às necessidades de consulta profissional real.
O objetivo principal deste experimento é demonstrar o potencial do GPT-4, porém, é importante observar que este não é um aplicativo ou produto totalmente polido, mas sim um projeto experimental. É possível que o GPT-4 não tenha um desempenho ideal em cenários de negócios complexos do mundo real. Incentivamos você a aprimorá-lo e aplicá-lo em vários cenários, e ficaríamos encantados em ouvir sobre seus resultados!
Se você achar este repositório útil, cite o seguinte artigo:
@misc{cao2023diaggpt,
title={DiagGPT: An LLM-based and Multi-agent Dialogue System with Automatic Topic Management for Flexible Task-Oriented Dialogue},
author={Lang Cao},
year={2023},
eprint={2308.08043},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


