RWKV LM
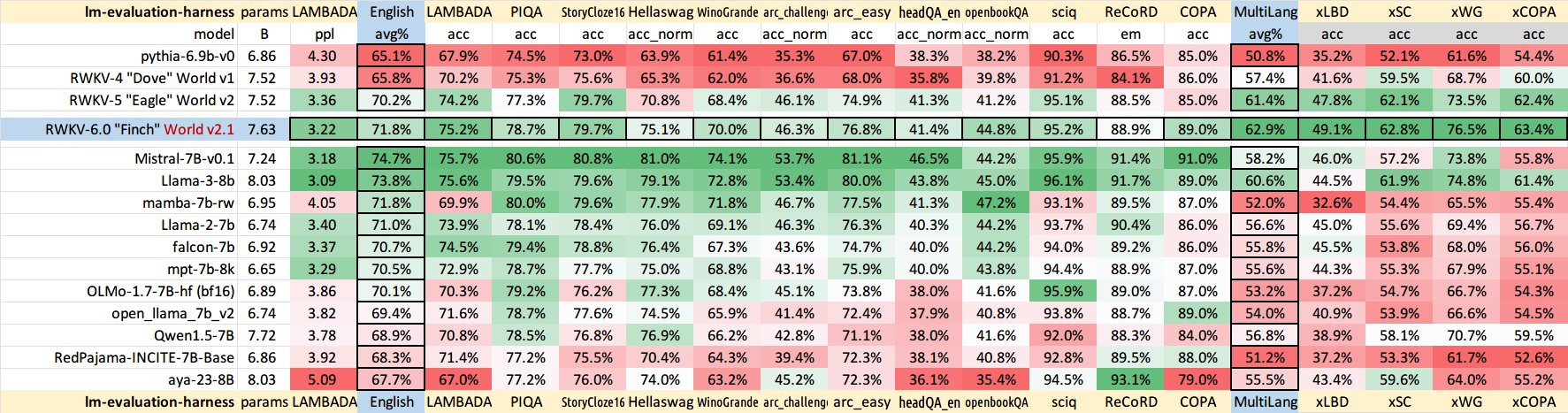
v5
Página inicial da RWKV: https://www.rwkv.com
Papel RWKV-5/6 Eagle/Finch : https://arxiv.org/abs/2404.05892
Impressionante RWKV em visão: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
Demonstração RWKV-6 3B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Demonstração RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
Código de demonstração do modo GPT RWKV-6 (com comentários e explicações) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
Demonstração do modo RNN RWKV-6: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Para referência, use python 3.10+, torch 2.5+, cuda 12.5+, deepspeed mais recente, mas mantenha pytorch-lightning==1.9.5
Treine RWKV-6 : use /RWKV-v5/ e use --my_testing "x060" em demo-training-prepare.sh e demo-training-run.sh
Treine RWKV-7 : use /RWKV-v5/ e use --my_testing "x070" em demo-training-prepare.sh e demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
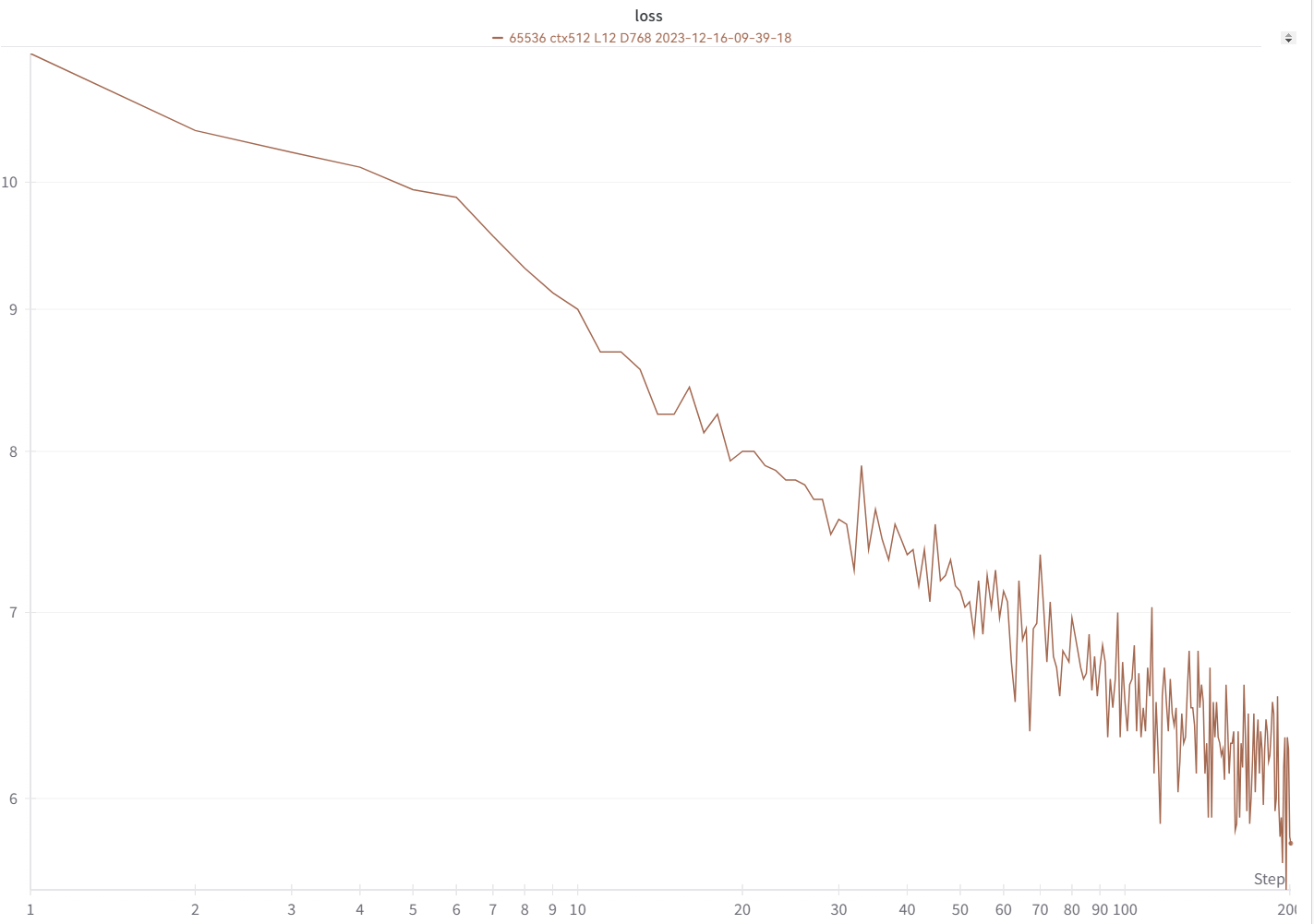
Sua curva de perda deve ser quase exatamente igual a esta, com os mesmos altos e baixos (se você usar o mesmo bsz & config):
Você pode executar seu modelo usando https://pypi.org/project/rwkv/ (use "rwkv_vocab_v20230424" em vez de "20B_tokenizer.json")
Use https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py para preparar dados binidx de jsonl e calcular "--my_exit_tokens" e "--magic_prime".
Tokenizer muito mais rápido de grandes dados: https://github.com/cahya-wirawan/json2bin
A "época" em train.py é "mini-época" (não é época real. Apenas por conveniência) e 1 mini-época = 40320 * tokens ctx_len.
Por exemplo, se seu binidx tiver 1498226207 tokens e ctxlen = 4096, defina "--my_exit_tokens 1498226207" (isso substituirá epoch_count) e será 1498226207/(40320 * 4096) = 9,07 miniépocas. O treinador sairá automaticamente após os tokens "--my_exit_tokens". Defina "--magic_prime" como o maior 3n+2 primo menor que datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), que é "--magic_prime 365759" neste caso.
simples: prepare SFT jsonl => repita seus dados SFT 3 ou 4 vezes em make_data.py. mais repetição leva ao overfitting.
avançado: repita seus dados SFT 3 ou 4 vezes em seu jsonl (observe que make_data.py irá embaralhar todos os itens jsonl) => adicione alguns dados de base (como slimpajama) ao seu jsonl => e repita apenas 1 vez em make_data.py.
Corrigir picos de treinamento : consulte a parte "Consertando picos RWKV-6" nesta página.
Inferência simples para RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Inferência simples para RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Nota: Em [estado = kv + w * estado] tudo deve estar em fp32 porque w pode estar muito próximo de 1. Portanto, podemos manter o estado e w em fp32 e converter kv em fp32.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
demonstração de bate-papo para desenvolvedores: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Dicas para modelos pequenos/dados pequenos : Quando treino modelos musicais RWKV, uso dimensões profundas e estreitas (como L29-D512) e aplico wd e dropout (como wd=2 dropout=0,02). Nota O abandono do RWKV-LM é muito eficaz - use 1/4 do seu valor normal.
Use o formato .jsonl para seus dados (consulte https://huggingface.co/BlinkDL/rwkv-5-world para formatos).
Use https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py para tokenizá-lo usando o tokenizer mundial em binidx, adequado para ajustar modelos mundiais.
Renomeie o ponto de verificação base na pasta do modelo para rwkv-init.pth e altere os comandos de treinamento para usar --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 para 7B.
0,1B = --n_camada 12 --n_embd 768 // 0,4B = --n_camada 24 --n_embd 1024 // 1,5B = --n_camada 24 --n_embd 2048 // 3B = --n_camada 32 --n_embd 2560 / / 7B = --n_camada 32 --n_embd 4096
Implementação atualmente não otimizada, utiliza o mesmo vram do SFT completo
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
use rwkv 0.8.26+ para carregar automaticamente o "time_state" treinado
Ao treinar RWKV do zero, tente minha inicialização para obter melhor desempenho. Verifique generate_init_weight() de src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Se você estiver usando incorporação posicional, talvez seja melhor remover block.0.ln0 e usar a inicialização padrão para emb.weight em vez de meu uniform_(a=-1e-4, b=1e-4) !!!
ao treinar do zero, adicione "k = k * torch.clamp(w, max=0).exp()" antes de "RUN_CUDA_RWKV6(r, k, v, w, u)" e lembre-se de alterar seu código de inferência também . você verá uma convergência mais rápida.
use "--adam_eps 1e-18"
"--beta2 0,95" se você observar picos
em trainer.py faça "lr = lr * (0,01 + 0,99 * trainer.global_step / w_step)" (originalmente 0,2 + 0,8) e "--warmup_steps 20"
"--weight_decay 0.1" leva a uma melhor perda final se você estiver treinando muitos dados. defina lr_final como 1/100 de lr_init ao fazer isso.
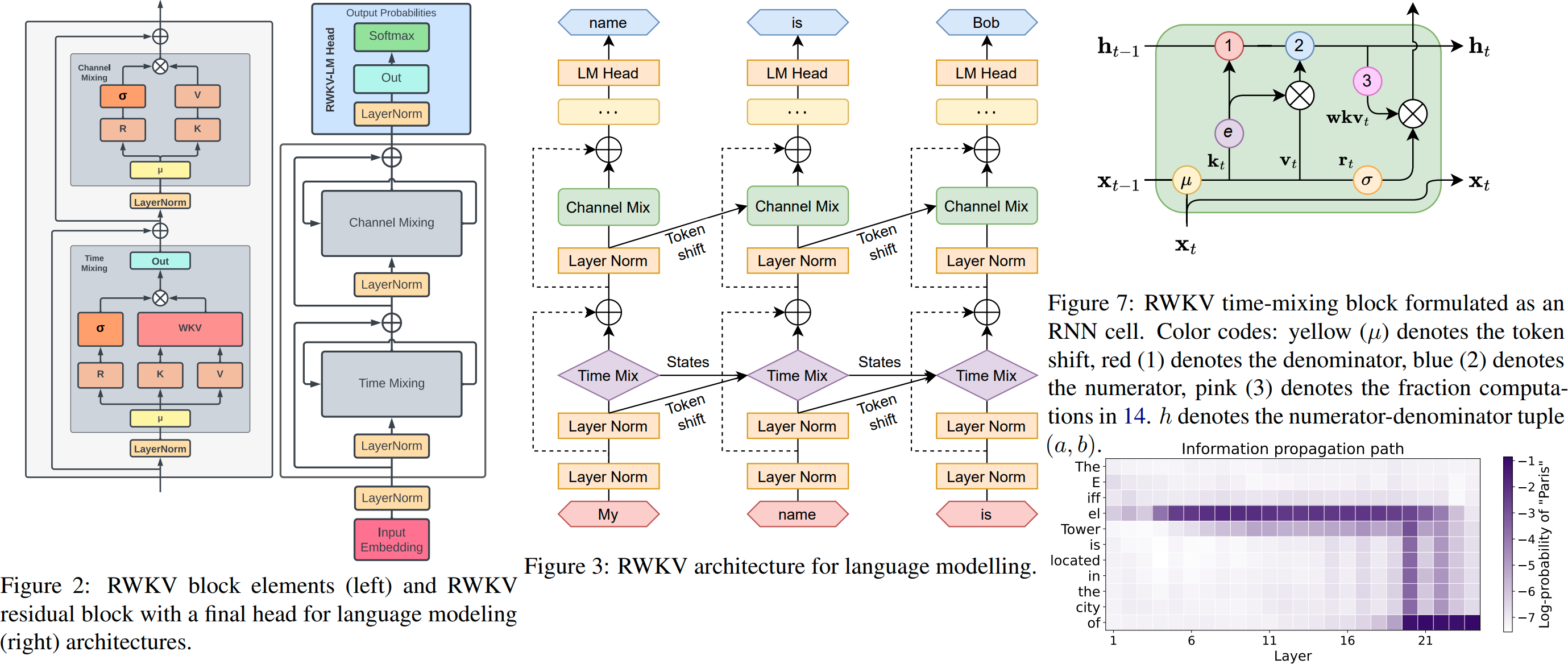
RWKV é um RNN com desempenho LLM em nível de transformador, que também pode ser treinado diretamente como um transformador GPT (paralelizável). E é 100% livre de atenção. Você só precisa do estado oculto na posição t para calcular o estado na posição t+1. Você pode usar o modo "GPT" para calcular rapidamente o estado oculto do modo "RNN".
Portanto, ele combina o melhor do RNN e do transformador - ótimo desempenho, inferência rápida, salva VRAM, treinamento rápido, ctx_len "infinito" e incorporação de frase livre (usando o estado oculto final).
GUI do RWKV Runner https://github.com/josStorer/RWKV-Runner com instalação e API com um clique
Todos os pesos RWKV mais recentes: https://huggingface.co/BlinkDL
Pesos RWKV compatíveis com HF: https://huggingface.co/RWKV
Pacote pip RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (não requer kernel CUDA personalizado para treinar, funciona para qualquer GPU/CPU)
Twitter : https://twitter.com/BlinkDL_AI
Página inicial : https://www.rwkv.com
Projetos legais da comunidade RWKV :
Todos os (300+) projetos RWKV: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV Visão RWKV
https://github.com/feizc/Diffusion-RWKV Difusão RWKV
https://github.com/cgisky1980/ai00_rwkv_server Inferência WebGPU mais rápida (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv back-end para ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Inferência rápida de CPU/cuBLAS/CLBlast: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Infctx trainer
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Assistente digital com RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Inferência rápida de GPU com cuda/amd/vulkan
RWKV v6 em 250 linhas (com tokenizer também): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 em 250 linhas (com tokenizer também): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 em 150 linhas (modelo, inferência, geração de texto): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
Pré-impressão RWKV v4 https://arxiv.org/abs/2305.13048
Introdução ao RWKV v4 e em 100 linhas de numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
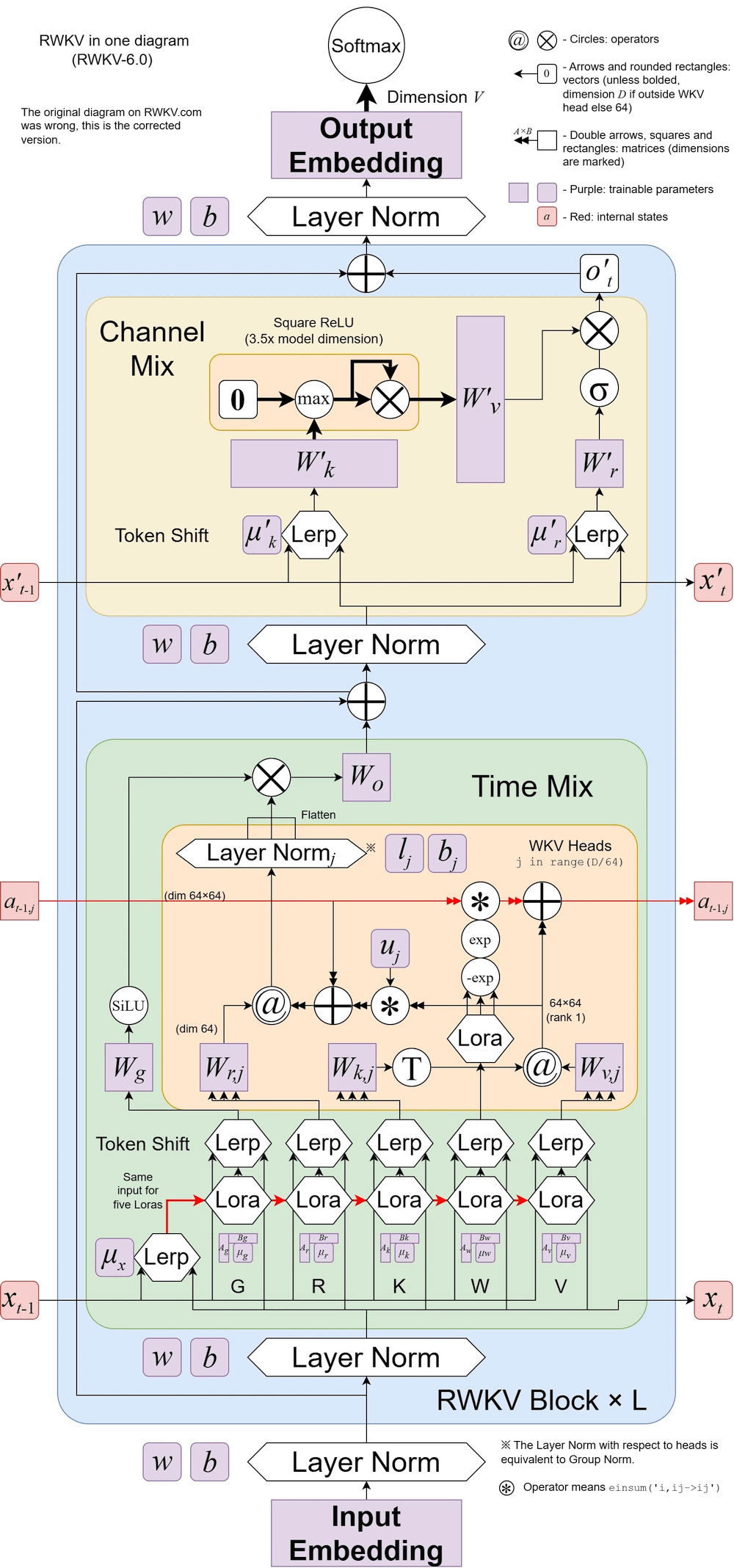
RWKV v6 ilustrado:
Um artigo legal (Spiking Neural Network) usando RWKV: https://github.com/ridgerchu/SpikeGPT
Você está convidado a participar da discórdia RWKV https://discord.gg/bDSBUMeFpc para desenvolvê-la. Temos bastante computação potencial (A100 40Gs) agora (graças ao Stability e ao EleutherAI), então se você tiver ideias interessantes, posso executá-las.

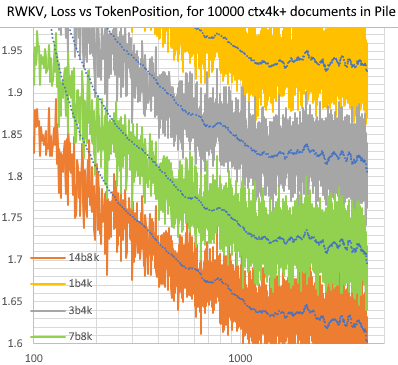
RWKV [perda vs posição de token] para 10.000 documentos ctx4k+ na pilha. RWKV 1B5-4k é praticamente plano após ctx1500, mas 3B-4k e 7B-4k e 14B-4k têm algumas inclinações e estão melhorando. Isso desmascara a antiga visão de que RNNs não podem modelar lentes ctxlens longas. Podemos prever que o RWKV 100B será ótimo, e o RWKV 1T é provavelmente tudo que você precisa :)
Bate-papoRWKV com RWKV 14B ctx8192:

Acredito que o RNN é um candidato melhor para modelos fundamentais, porque: (1) É mais amigável para ASICs (sem cache kv). (2) É mais amigável para RL. (3) Quando escrevemos, nosso cérebro é mais parecido com o RNN. (4) O universo também é como um RNN (por causa da localidade). Os transformadores são modelos não locais.
RWKV-3 1,5B em A40 (tf32) = sempre 0,015 seg/token, testado usando código pytorch simples (sem CUDA), utilização de GPU 45%, VRAM 7823M
GPT2-XL 1.3B em A40 (tf32) = 0,032 seg/token (para ctxlen 1000), testado usando HF, utilização de GPU 45% também (interessante), VRAM 9655M
Velocidade de treinamento: (novo código de treinamento) RWKV-4 14B BF16 ctxlen4096 = 114K tokens/s em 8x8 A100 80G (ZERO2+CP). (código de treinamento antigo) RWKV-4 1.5B BF16 ctxlen1024 = 106 mil tokens/s em 8xA100 40G.
Também estou fazendo experimentos de imagem (por exemplo: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) e o RWKV será capaz de fazer difusão txt2img :) Minha ideia: imagem rgb 256x256 -> latentes 32x32x13bit - > aplicar RWKV para calcular a probabilidade de transição para cada grade 32x32 -> fingir que as grades são independentes e "difusas" usando essas probabilidades.
Treinamento suave - sem picos de perdas! (lr & bsz mudam em torno de tokens de 15G) 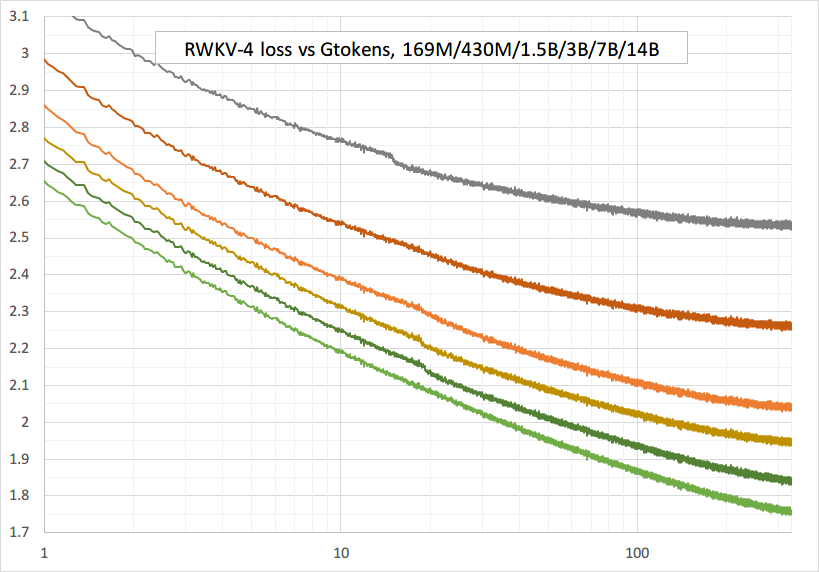
Todos os modelos treinados serão de código aberto. A inferência é muito rápida (apenas multiplicações de matriz-vetor, sem multiplicações de matriz-matriz), mesmo em CPUs, então você pode até executar um LLM em seu telefone.
Como funciona: O RWKV coleta informações para vários canais, que também decaem em velocidades diferentes conforme você passa para o próximo token. É muito simples quando você entende.
RWKV é paralelizável porque o decaimento de tempo de cada canal é independente dos dados (e treinável) . Por exemplo, no RNN normal você pode ajustar o decaimento de tempo de um canal de, digamos, 0,8 a 0,5 (estes são chamados de "gates"), enquanto no RWKV você simplesmente move a informação de um canal W-0,8 para um canal W-0,5. -canal para obter o mesmo efeito. Além disso, você pode ajustar o RWKV em um RNN não paralelizável (então você pode usar saídas de camadas posteriores do token anterior) se desejar desempenho extra.

Aqui estão alguns dos meus TODOs. Vamos trabalhar juntos :)
Integração HuggingFace (verifique huggingface/transformers#17230) e inferência otimizada de CPU e iOS e Android e WASM e WebGL. RWKV é um RNN e muito amigável para dispositivos de ponta. Vamos tornar possível executar um LLM no seu telefone.
Teste-o em tarefas bidirecionais e MLM e tokens de imagem, áudio e vídeo. Acho que o RWKV pode oferecer suporte ao codificador-decodificador desta forma: para cada token do decodificador, use uma mistura aprendida de [estado oculto anterior do decodificador] e [estado oculto final do codificador]. Conseqüentemente, todos os tokens do decodificador terão acesso à saída do codificador.
Agora treinando o RWKV-4a com uma única atenção extra (apenas algumas linhas extras em comparação com o RWKV-4) para melhorar ainda mais algumas tarefas difíceis de tiro zero (como LAMBADA) para modelos menores. Consulte https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
Feedback do usuário:
Até agora, brinquei com o modelo baseado em caracteres em nosso conjunto de dados de pré-treinamento relativamente pequeno (cerca de 10 GB de texto) e os resultados são extremamente bons - pessoas semelhantes a modelos que levam muito, muito mais tempo para treinar.
querido Deus, rwkv é rápido. mudei para outra guia depois de começar a treiná-lo do zero e quando voltei ele estava emitindo palavras plausíveis em inglês e maori, saí para ir tomar um café no microondas e quando voltei estava produzindo frases totalmente gramaticalmente corretas.
Tweet de Sepp Hochreiter (obrigado!): https://twitter.com/HochreiterSepp/status/1524270961314484227
Você também pode me encontrar (BlinkDL) no EleutherAI Discord: https://www.eleuther.ai/get-involved/
IMPORTANTE: Use deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 e cuda 11.7.1 ou 11.7 (observe que torch2 + deepspeed tem bugs estranhos e prejudica o desempenho do modelo)
Use https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (código mais recente, compatível com v4).
Aqui está um ótimo prompt para testar perguntas e respostas de LLMs. Funciona para qualquer modelo: (encontrado minimizando as pessoas do ChatGPT para RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisExecute modelos de pilha RWKV-4: Baixe modelos em https://huggingface.co/BlinkDL. Defina TOKEN_MODE = 'pile' em run.py e execute-o. É rápido mesmo na CPU (o modo padrão).
Colab para pilha RWKV-4 1,5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Execute modelos de pilha RWKV-4 em seu navegador (e versão onnx): consulte esta edição nº 7
Demonstração da Web RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (nota: apenas amostragem gananciosa por enquanto)
Para o antigo RWKV-2: veja o lançamento aqui para um modelo de parâmetros de 27M no enwik8 com 0,72 BPC (dev). Execute run.py em https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. Você pode até executá-lo em seu navegador: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (isso está usando tf.js WASM modo de thread único).
pip instalar deepspeed==0.7.0 // pip instalar pytorch-lightning==1.9.5 // tocha 1.13.1+cu117
NOTA: adicione redução de peso (0,1 ou 0,01) e abandono (0,1 ou 0,01) ao treinar com uma pequena quantidade de dados. tente x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) etc.
Treinando RWKV-4 do zero: execute train.py, que por padrão usa o conjunto de dados enwik8 (descompacte https://data.deepai.org/enwik8.zip).
Você treinará a versão "GPT" porque é paralelizável e mais rápida de treinar. O RWKV-4 pode extrapolar, portanto, o treinamento com ctxLen 1024 pode funcionar para ctxLen de 2500+. Você pode ajustar o modelo com ctxLens mais longos e ele pode se adaptar rapidamente a ctxLens mais longos.
Modelos de pilha RWKV-4 de ajuste fino: use 'prepare-data.py' em https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 para tokenizar .txt no trem. dados npy. Em seguida, use https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py para treiná-lo.
Leia o código de inferência em src/model.py e tente usar o estado oculto final(.xx .aa .bb) como uma incorporação de frase fiel para outras tarefas. Provavelmente você deveria começar com .xx e .aa/.bb (.aa dividido por .bb).
Colab para ajuste fino de modelos de pilha RWKV-4: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Corpus grande: use https://github.com/Abel2076/json2binidx_tool para converter .jsonl em .bin e .idx
O exemplo de formato jsonl (uma linha para cada documento):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
gerado por código como este:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Treinamento ctxlen infinito (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Considere RWKV 14B. O estado possui 200 vetores, ou seja, 5 vetores para cada bloco: fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx).
Não faça pool médio porque diferentes vetores (xx aa bb pp xx) no estado têm significados e intervalos muito diferentes. Você provavelmente pode remover pp.
Sugiro primeiro coletar as estatísticas média + stdev de cada canal de cada vetor e normalizar todas elas (nota: a normalização deve ser independente de dados e coletada de vários textos). Em seguida, treine um classificador linear.
RWKV-5 é multi-head e aqui mostra um cabeçote. Há também um LayerNorm para cada cabeçote (daí, na verdade, GroupNorm).
Mixagem Dinâmica e Decay Dinâmico. Exemplo (faça isso para TimeMix e ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Use o modo paralelizado para gerar rapidamente o estado e, em seguida, use um RNN completo ajustado (as camadas do token n podem usar saídas de todas as camadas do token n-1) para geração sequencial.
Agora, a redução do tempo é de 0,999 ^ T (0,999 pode ser aprendido). Mude para algo como (0,999 ^ T + 0,1), onde 0,1 também pode ser aprendido. A parte 0,1 será mantida para sempre. Ou, A^T + B^T + C = decaimento rápido + decaimento lento + constante. Pode até usar fórmulas diferentes (por exemplo, K^2 em vez de e^K para um componente de decaimento ou sem normalização).
Use decaimento de valor complexo (ou seja, rotação em vez de decaimento) em alguns canais.
Injetar alguma codificação posicional treinável e extrapolável?
Além da rotação 2d, podemos tentar outros grupos de Lie, como a rotação 3d (SO(3)). RWKV não abeliano haha.
RWKV pode ser ótimo em dispositivos analógicos (pesquise multiplicação de vetores de matriz analógica e multiplicação de vetores de matriz fotônica). O modo RNN é muito amigável ao hardware (processamento na memória). Também pode ser um SNN (https://github.com/ridgerchu/SpikeGPT). Eu me pergunto se ele pode ser otimizado para computação quântica.
Estado oculto inicial treinável (xx aa bb pp xx).
LR em camadas (ou mesmo em linhas/colunas, em elementos) e teste o otimizador Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Talvez possamos melhorar a memorização simplesmente repetindo o contexto (acho que 2 vezes é o suficiente). Exemplo: Referência -> Referência (novamente) -> Pergunta -> Resposta
A ideia é garantir que cada token no vocabulário entenda seu comprimento e bytes UTF-8 brutos.
Seja a = max(len(token)) para todos os tokens no vocabulário. Defina AA: float[a][d_emb]
Seja b = max(len_in_utf8_bytes(token)) para todos os tokens no vocabulário. Defina BB: float[b][256][d_emb]
Para cada token X no vocabulário, sejam [x0, x1, ..., xn] seus bytes UTF-8 brutos. Adicionaremos alguns valores extras ao seu EMB(X) incorporado:
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (nota: AA BB são pesos que podem ser aprendidos)
Tenho uma ideia para melhorar a tokenização. Podemos codificar alguns canais para terem significados. Exemplo:
Canal 0 = "espaço"
Canal 1 = "colocar a primeira letra em maiúscula"
Canal 2 = "colocar todas as letras em maiúscula"
Portanto:
Incorporação de "abc": [0, 0, 0, x0, x1, x2 , ..]
Incorporação de "abc": [1, 0, 0, x0, x1, x2, ..]
Incorporação de "Abc": [1, 1, 0, x0, x1, x2, ..]
Incorporação de "ABC": [0, 0, 1, x0, x1, x2, ...]
......
então eles compartilharão a maior parte da incorporação. E podemos calcular rapidamente a probabilidade de saída de todas as variações de “abc”.
Nota: o método acima assume que p(" xyz") / p("xyz") é o mesmo para qualquer "xyz", o que pode estar errado.
Melhor: defina emb_space emb_capitalize_first emb_capitalize_all como uma função de emb.
Talvez o melhor: deixe 'abc' 'abc' etc. compartilhar os últimos 90% de seus embeddings.
Neste momento, todos os nossos tokenizadores gastam muitos itens para representar todas as variações de 'abc' 'abc' 'Abc' etc. Além disso, o modelo não pode descobrir se eles são realmente semelhantes se algumas dessas variações forem raras no conjunto de dados. O método aqui pode melhorar isso. Pretendo testar isso em uma nova versão do RWKV.
Exemplo (perguntas e respostas de rodada única):
Gere o estado final de todos os documentos wiki.
Para qualquer usuário Q, encontre o melhor documento wiki e use seu estado final como estado inicial.
Treine um modelo para gerar diretamente o estado inicial ideal para qualquer usuário Q.
No entanto, isso pode ser um pouco mais complicado para perguntas e respostas em várias rodadas :)
RWKV é inspirado no AFT da Apple (https://arxiv.org/abs/2105.14103).
Além disso, está usando vários dos meus truques, como:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (aplicável a todos os transformadores) que ajuda na qualidade da incorporação e estabiliza o Post-LN (que é o que estou usando).
Token-shift: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (aplicável a todos os transformadores), especialmente útil para modelos em nível de caractere.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (aplicável a todos os transformadores). Nota: é útil, mas desativei-o no modelo Pile para mantê-lo 100% RNN.
Porta R extra no FFN (aplicável a todos os transformadores). Também estou usando o reluSquared do Primer.
Melhor inicialização: inicio a maioria das matrizes para ZERO (consulte RWKV_Init em https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Você pode transferir alguns parâmetros de um modelo pequeno para um modelo grande (nota: eu também os classifico e suavizo), para uma convergência melhor e mais rápida (consulte https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
Meu kernel CUDA: https://github.com/BlinkDL/RWKV-CUDA para acelerar o treinamento.

Os fatores abcd trabalham juntos para construir uma curva de decaimento no tempo: [X, 1, W, W^2, W^3, ...].
Escreva as fórmulas para "token na posição 2" e "token na posição 3" e você terá a ideia:
kv / k é o mecanismo de memória. O token com k alto pode ser lembrado por um longo período, se W estiver próximo de 1 no canal.
O portão R é importante para o desempenho. k = força da informação deste token (a ser passada para tokens futuros). r = se deve aplicar as informações a este token.
Use diferentes fatores TimeMix treináveis para R/K/V nas camadas SA e FF. Exemplo:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Use preLN em vez de postLN (convergência mais estável e mais rápida):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Os blocos de construção do modo RWKV-3 GPT são semelhantes aos de um pré-LN GPT normal.
A única diferença é um LN extra após a incorporação. Observe que você pode absorver esse LN na incorporação após terminar o treinamento.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsÉ importante inicializar o emb com valores minúsculos, como nn.init.uniform_(a=-1e-4, b=1e-4), para utilizar meu truque https://github.com/BlinkDL/SmallInitEmb.
Para o 1.5B RWKV-3, eu uso o otimizador Adam (sem wd, sem dropout) em 8 * A100 40G.
batchSz = 32 * 896, ctxLen = 896. Estou usando tf32, então batchSz é um pouco pequeno.
Para os primeiros 15B de tokens, LR é fixado em 3e-4 e beta=(0,9, 0,99).
Então eu defino beta=(0,9, 0,999) e faço um decaimento exponencial de LR, atingindo 1e-5 em 332B de tokens.
O RWKV-3 não tem nenhuma atenção no sentido usual, mas de qualquer forma chamaremos esse bloco de ATT.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionAs matrizes self.key, self.receptance e self.output são todas inicializadas em zero.
Os vetores time_mix, time_decay, time_first são transferidos de um modelo treinado menor (nota: eu também os classifico e suavizo).
O bloco FFN possui três truques em comparação com o GPT normal:
Meu truque time_mix.
O sqReLU do artigo Primer.
Uma porta de recepção extra (semelhante à porta de recepção no bloco ATT).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvAs matrizes de valor próprio e de auto-recepção são todas inicializadas em zero.

Seja F[t] o estado do sistema em t.
Seja x[t] a nova entrada externa em t.
No GPT, prever F[t+1] requer considerar F[0], F[1], .. F[t]. Portanto, é necessário O (T ^ 2) para gerar uma sequência de comprimento T.
A fórmula simplificada para GPT:
É muito capaz em teoria, mas isso não significa que podemos utilizar totalmente sua capacidade com otimizadores usuais . Suspeito que o cenário de perdas seja muito difícil para os nossos métodos atuais.
Compare com a fórmula simplificada para RWKV (o modo paralelo é semelhante ao AFT da Apple):
Os R, K, V são matrizes treináveis e W é um vetor treinável (fator de decaimento de tempo para cada canal).
No GPT, a contribuição de F[i] para F[t+1] é ponderada por .
No RWKV-2, a contribuição de F[i] para F[t+1] é ponderada por .
Aí vem a conclusão: podemos reescrever isso em uma RNN (fórmula recursiva). Observação:
Portanto, é simples verificar:
onde A[t] e B[t] são o numerador e o denominador da etapa anterior, respectivamente.
Acredito que RWKV tem bom desempenho porque W é como aplicar repetidamente uma matriz diagonal. Observe (P^{-1} DP)^n = P^{-1} D^n P, portanto é semelhante a aplicar repetidamente uma matriz diagonalizável geral.
Além disso, é possível transformá-lo em uma EDO contínua (um pouco semelhante aos Modelos de Espaço de Estados). Escreverei sobre isso mais tarde.
Tenho uma ideia para [texto -> imagem RGB 32x32] usando um LM (transformador, RWKV, etc.). Vou testar em breve.
Em primeiro lugar, perda de LM (em vez de perda de L2), para que a imagem não fique desfocada.
Em segundo lugar, a quantização de cores. Por exemplo, permitindo apenas 8 níveis para R/G/B. Então o tamanho do vocabulário da imagem é 8x8x8 = 512 (para cada pixel), em vez de 2 ^ 24. Portanto, uma imagem RGB 32x32 = uma sequência len1024 de vocab512 (tokens de imagem), que é uma entrada típica para LMs usuais. (Mais tarde, podemos usar modelos de difusão para aumentar a resolução e gerar imagens RGB888. Poderemos usar um LM para isso também.)
Em terceiro lugar, incorporações posicionais 2D que são fáceis de entender pelo modelo. Por exemplo, adicione coordenadas X e Y únicas aos primeiros 64 (=32+32) canais. Digamos que se o pixel estiver em x=8, y=20, então adicionaremos 1 ao canal 8 e ao canal 52 (=32+20). Além disso, provavelmente podemos adicionar as coordenadas flutuantes X e Y (normalizadas para a faixa 0 ~ 1) a outros 2 canais. E outras posições periódicas. a codificação também pode ajudar (testará).
Finalmente, RandRound quando


