effibot
v0.0.1
Inglês | 中文
Um servidor ChatGPT que armazena e processa dados usando uma estrutura de dados baseada em árvore, proporcionando aos usuários uma experiência de perguntas e respostas semelhante a um mapa mental com o ChatGPT. A estrutura em árvore otimiza muito a transmissão de contexto (tokens) e proporciona uma melhor experiência quando utilizada dentro de uma empresa.

A imagem mostra um cliente Demo; a IU é apenas para referência.
Em cenários de trabalho, a necessidade de fazer a mesma pergunta profundamente é relativamente rara, portanto, na maioria dos casos, a contagem de tokens pode ser controlada dentro de 2.000. Portanto, o limite de tokens do GPT 3.5 (4.096) é suficiente (não há necessidade de considerar GPT4 para precisão).
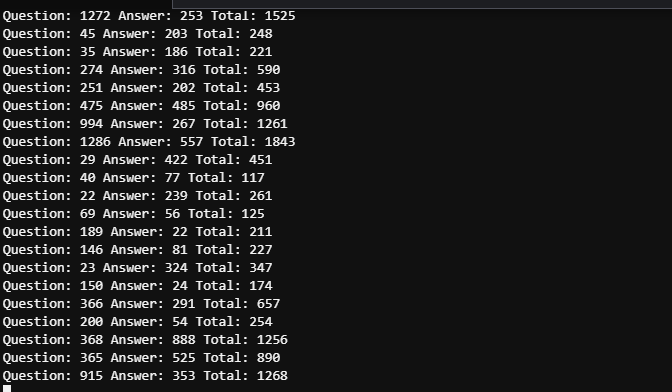
O tempo entre as duas capturas de tela não excede 5 minutos. Devido a múltiplos usuários, registros detalhados precisam ser visualizados para distinguir o consumo de tokens das cinco questões mencionadas, mas o consumo geral de tokens pode ser visto como controlável.
43.206.107.75:4000
O ambiente de demonstração é implantado em um servidor em nuvem. E NÃO defina o token OpenAI, para que ele inicie o modo simulado.
Atualizações serão feitas conforme necessário. Mais atualizações serão fornecidas se o projeto for amplamente utilizado, e as atualizações serão feitas com base no interesse se o projeto tiver menos usuários.
Sinta-se à vontade para desenvolver uma UI Web baseada neste projeto! A UI na demonstração foi escrita por mim, um iniciante em design de UI. PRs são bem-vindos!
Organize a entrada do usuário em uma árvore com várias ramificações e passe apenas o conteúdo da ramificação atual como informações de contexto para o GPT. A quantidade de conteúdo que transmitimos a cada vez é igual à profundidade do nó atual. Otimize a seleção e transmissão de contexto através da árvore multi-ramificação.
Uma árvore binária com n nós tem profundidade logn. A profundidade aqui se refere às informações de contexto que precisamos passar para a API GPT. Se não processarmos o contexto, pode ser considerado como uma árvore unidimensional, que degenera num segmento de linha, naturalmente o caso mais complexo. Ao organizar a sessão em uma estrutura de árvore, podemos criar um mapa mental.
Recomenda-se escolher um local de servidor em um país ou região compatível com OpenAI. Data centers e hosts em nuvem são aceitáveis, e as seguintes nuvens foram testadas:
Se você insistir em testar em um país ou região sem suporte, este projeto oferece suporte total aos proxies, mas o próprio proxy pode afetar a experiência e representar riscos . Consulte o arquivo de configuração Spec.GPT.TransportUrl para obter detalhes de configuração do proxy.
O uso de proxies não é recomendado. Use por sua conta e risco.
git clone https://github.com/finishy1995/effibot.git
cd effibot A configuração padrão é o modo Mock, o que significa que ele não chamará realmente a API GPT, mas retornará a entrada do usuário como resposta. A porta padrão da API REST é 4001 e todas as configurações podem ser modificadas no arquivo http/etc/http-api.yaml .
vi http/etc/http-api.yaml Name : http-api
Host : 0.0.0.0
Port : 4001 # Port of http server, default 4001
Timeout : 30000 # Timeout of http request, default 30000(ms)
Log :
Level : debug
Mode : file # Log mode, default console 日志模式,可选 console(命令行输出) 或 file
Path : ../logs # Log file path, default ../logs
Spec :
GPT :
# Token: "sk-" # Token of OpenAI, will start mock mode if not set. OpenAI 密钥,如果不设置则启用 mock 模式
# TransportUrl: "http://localhost:4002" # Transport url of OpenAI, default "http://localhost:4002 代理地址,如果不设置则不启用代理
Timeout : 20s # Timeout of OpenAI request, default 20s
MaxToken : 1000 # Max token of OpenAI response, default 1000 Depois de modificar o arquivo, se você precisar One-click deployment ou container deployment , execute o seguinte comando
mkdir -p ./effibot_config
cp http/etc/http-api.yaml ./effibot_config Certifique-se de que docker e docker-compose estejam instalados e habilitados corretamente.
docker-compose up -d O cliente de demonstração será executado na porta 4000 e a API REST será executada nas portas 4000 e 4001 .
Se você não tiver docker-compose , poderá usar o seguinte comando:
docker network create effibot
docker run -p 4001:4001 -v ./effibot_config:/app/etc --network effibot --name effibot -d finishy/effibot:latest
docker run -p 4000:4000 --network effibot --name effibot-demo -d finishy/effibot-demo:latestCertifique-se de que o golang 1.18+ esteja instalado e configurado.
cd http
go run http.go # go build http.go && ./httpSair do diretório
cd ..docker build -t effibot:latest -f http/Dockerfile .docker network create effibot # Modify the configuration file as needed, such as adding the OpenAI token and change the log mode to console
docker run -p 4001:4001 -v ./effibot_config:/app/etc --network effibot --name effibot -d effibot:latestdocker build -t effibot-demo:latest -f demo/Dockerfile .docker run -p 4000:4000 --network effibot --name effibot-demo -d effibot-demo:latestO cliente de demonstração é desenvolvido por Vue.js + Vite + TypeScript e requer ambiente Node.js 14+.
cd demo
yarn && yarn devO cliente de demonstração será aberto automaticamente em http://localhost:5173.


