DiGIT
1.0.0
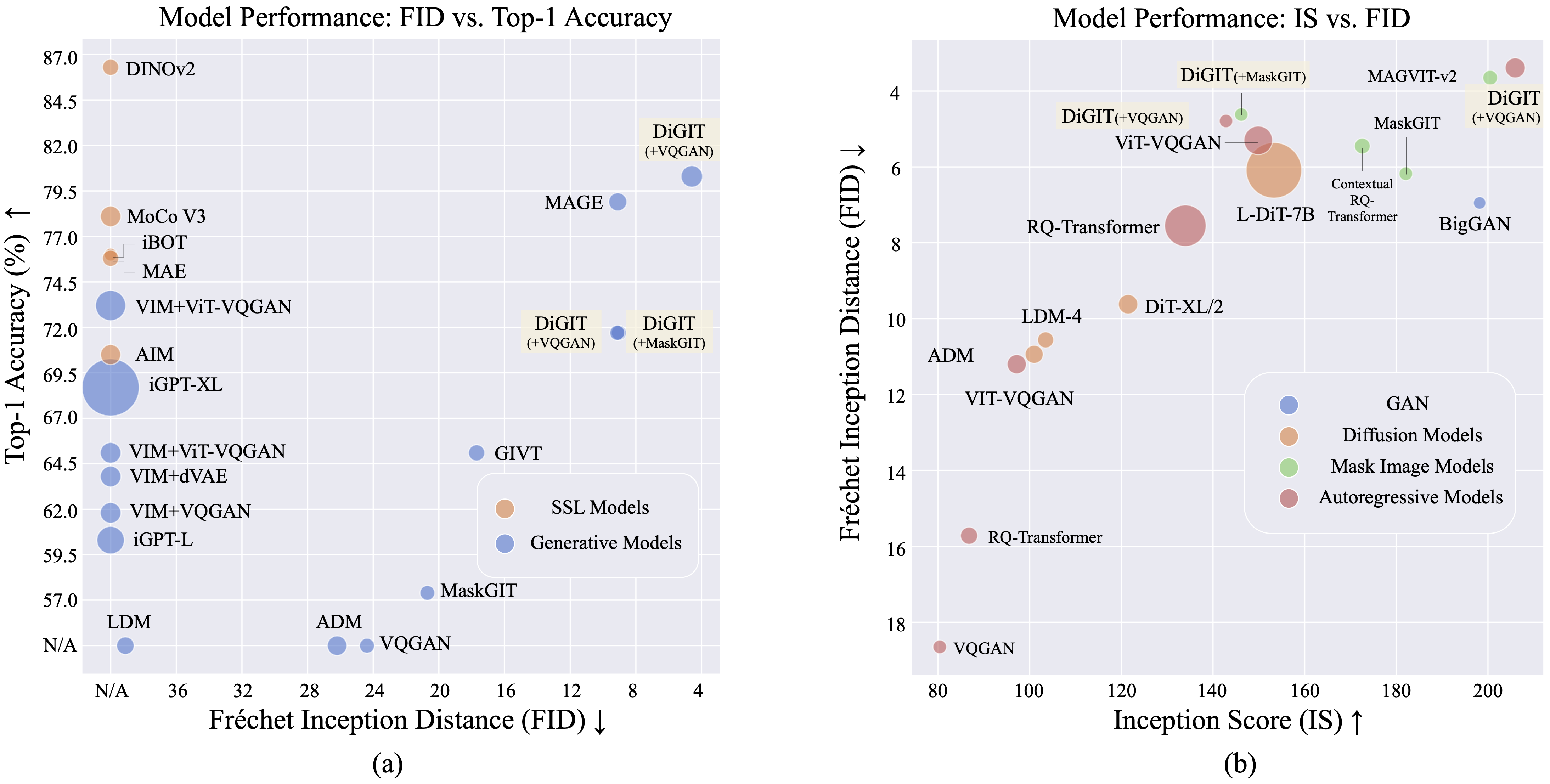
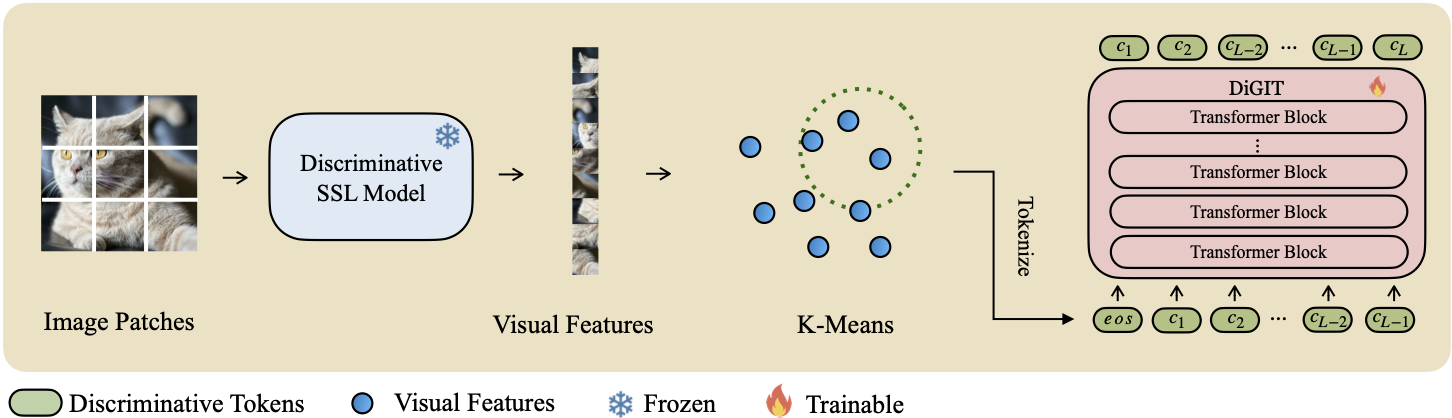
Apresentamos DiGIT , um modelo generativo auto-regressivo que realiza previsão do próximo token em um espaço latente abstrato derivado de modelos de aprendizagem auto-supervisionada (SSL). Ao empregar o agrupamento K-Means nos estados ocultos do modelo DINOv2, criamos efetivamente um novo tokenizer discreto. Este método aumenta significativamente o desempenho de geração de imagens no conjunto de dados ImageNet, alcançando uma pontuação FID de 4,59 para tarefas incondicionais de classe e 3,39 para tarefas condicionais de classe . Além disso, o modelo melhora a compreensão da imagem, alcançando uma precisão de sonda linear de 80,3 .
| Métodos | # fichas | Características | # Parâmetros | Contas principais 1 |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362 milhões | 60,3 |
| iGPT-XL | 64 | 3072 | 6801M | 68,7 |
| VIM+VQGAN | 32 | 1024 | 650 milhões | 61,8 |
| VIM+dVAE | 32 | 1024 | 650 milhões | 63,8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650 milhões | 65,1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697M | 73,2 |
| MIRAR | 16 | 1536 | 0,6B | 70,5 |
| DiGIT (nosso) | 16 | 1024 | 219 milhões | 71,7 |
| DiGIT (nosso) | 16 | 1536 | 732 milhões | 80,3 |
| Tipo | Métodos | # Parâmetro | # Época | FID | É |
|---|---|---|---|---|---|
| GAN | BigGAN | 70 milhões | - | 38,6 | 24h70 |
| Diferença. | LDM | 395 milhões | - | 39,1 | 22,83 |
| Diferença. | ADM | 554 milhões | - | 26.2 | 39,70 |
| MIM | MAGO | 200 milhões | 1600 | 11.1 | 81.17 |
| MIM | MAGO | 463 milhões | 1600 | 9h10 | 105,1 |
| MIM | MáscaraGIT | 227 milhões | 300 | 20,7 | 42.08 |
| MIM | DiGIT (+MaskGIT) | 219 milhões | 200 | 9.04 | 75.04 |
| RA | VQGAN | 214 milhões | 200 | 24h38 | 30,93 |
| RA | DiGIT (+VQGAN) | 219 milhões | 400 | 9.13 | 73,85 |
| RA | DiGIT (+VQGAN) | 732 milhões | 200 | 4,59 | 141,29 |
| Tipo | Métodos | # Parâmetro | # Época | FID | É |
|---|---|---|---|---|---|
| GAN | BigGAN | 160 milhões | - | 6,95 | 198,2 |
| Diferença. | ADM | 554 milhões | - | 10,94 | 101,0 |
| Diferença. | LDM-4 | 400 milhões | - | 10.56 | 103,5 |
| Diferença. | DiT-XL/2 | 675 milhões | - | 9,62 | 121,50 |
| Diferença. | L-DiT-7B | 7B | - | 6.09 | 153,32 |
| MIM | CQR-Trans | 371 milhões | 300 | 5,45 | 172,6 |
| MIM+AR | VAR | 310 milhões | 200 | 4,64 | - |
| MIM+AR | VAR | 310 milhões | 200 | 3,60* | 257,5* |
| MIM+AR | VAR | 600 milhões | 250 | 2,95* | 306,1* |
| MIM | MAGVIT-v2 | 307 milhões | 1080 | 3,65 | 200,5 |
| RA | VQVAE-2 | 13,5B | - | 31.11 | 45 |
| RA | RQ-Trans | 480 milhões | - | 15,72 | 86,8 |
| RA | RQ-Trans | 3,8B | - | 7,55 | 134,0 |
| RA | ViTVQGAN | 650 milhões | 360 | 11h20 | 97,2 |
| RA | ViTVQGAN | 1,7B | 360 | 5.3 | 149,9 |
| MIM | MáscaraGIT | 227 milhões | 300 | 6.18 | 182,1 |
| MIM | DiGIT (+MaskGIT) | 219 milhões | 200 | 4,62 | 146,19 |
| RA | VQGAN | 227 milhões | 300 | 18h65 | 80,4 |
| RA | DiGIT (+VQGAN) | 219 milhões | 400 | 4,79 | 142,87 |
| RA | DiGIT (+VQGAN) | 732 milhões | 200 | 3,39 | 205,96 |
*: O VAR é treinado com orientação sem classificador, enquanto todos os outros modelos não.
O arquivo K-Means npy e os pontos de verificação do modelo podem ser baixados em:
| Modelo | Link |
|---|---|
| Pesos de alta frequência? | Abraçando cara |
Para o modelo básico usamos DINOv2-base e DINOv2-large para modelo de tamanho grande. O VQGAN que usamos é o mesmo do MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq via pip install fairseq . Baixe o conjunto de dados ImageNet e coloque-o no diretório do conjunto de dados $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Extraia recursos SSL e salve-os como arquivos .npy. Use o algoritmo K-Means com faiss para calcular os centróides. Você também pode utilizar nossos centróides pré-treinados disponíveis no Huggingface.
bash preprocess/run.shEtapa 1
Treine um modelo GPT com um tokenizador discriminativo. Você pode encontrar os scripts de treinamento em scripts/train_stage1_ar.sh e os hiperparâmetros estão em config/stage1/dino_base.yaml . Para configuração de geração condicional de classe, consulte scripts/train_stage1_classcond.sh .
Etapa 2
Treine um decodificador de pixel (modelo AR ou modelo NAR) condicionado aos tokens discriminativos. Você pode encontrar os scripts de treinamento autoregressivo em scripts/train_stage2_ar.sh e os scripts de treinamento NAR em scripts/train_stage2_nar.sh .
Uma pasta chamada outputs/EXP_NAME/checkpoints será criada para salvar os pontos de verificação. Os arquivos de log do TensorBoard são salvos em outputs/EXP_NAME/tb . Os logs serão registrados em outputs/EXP_NAME/train.log .
Você pode monitorar o processo de treinamento usando tensorboard --logdir=outputs/EXP_NAME/tb .
Primeira amostragem de tokens discriminativos com scripts/infer_stage1_ar.sh . Para o tamanho do modelo básico, recomendamos definir topk=200 e, para um tamanho de modelo grande, usar topk=400.
Em seguida, execute scripts/infer_stage2_ar.sh para amostrar tokens VQ com base nos tokens discriminativos amostrados anteriormente.
Os tokens gerados e as imagens sintetizadas serão armazenadas em um diretório denominado outputs/EXP_NAME/results .
Prepare o conjunto de validação ImageNet para avaliação FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Instale a ferramenta de avaliação executando pip install torch-fidelity .
Execute o seguinte comando para avaliar o FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shEste projeto está licenciado sob a licença MIT - consulte o arquivo LICENSE para obter detalhes.
Se você achar nosso projeto útil, espero que possa marcar nosso repositório com estrela e citar nosso trabalho da seguinte maneira.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

