FasterTransformer
v5.3 release
Observação: o desenvolvimento do FasterTransformer fez a transição para o TensorRT-LLM. Todos os desenvolvedores são incentivados a aproveitar o TensorRT-LLM para obter as melhorias mais recentes na inferência LLM. O repositório NVIDIA/FasterTransformer permanecerá ativo, mas não terá mais desenvolvimento.
Este repositório fornece um script e uma receita para executar o componente codificador e decodificador baseado em transformador altamente otimizado e é testado e mantido pela NVIDIA.
Na PNL, o codificador e o decodificador são dois componentes importantes, com a camada do transformador se tornando uma arquitetura popular para ambos os componentes. FasterTransformer implementa uma camada de transformador altamente otimizada para o codificador e o decodificador para inferência. Nas GPUs Volta, Turing e Ampere, o poder de computação dos Tensor Cores é usado automaticamente quando a precisão dos dados e os pesos são FP16.
FasterTransformer é construído sobre CUDA, cuBLAS, cuBLASLt e C++. Fornecemos pelo menos uma API dos seguintes frameworks: backend TensorFlow, PyTorch e Triton. Os usuários podem integrar o FasterTransformer diretamente nessas estruturas. Para estruturas de suporte, também fornecemos códigos de exemplo para demonstrar como usar e mostrar o desempenho dessas estruturas.
| Modelos | Estrutura | FP16 | INT8 (depois de Turing) | Esparsidade (após Ampere) | Tensor paralelo | Pipeline paralelo | FP8 (depois de Hopper) |
|---|---|---|---|---|---|---|---|
| BERTO | TensorFlow | Sim | Sim | - | - | - | - |
| BERTO | PyTorch | Sim | Sim | Sim | Sim | Sim | - |
| BERTO | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| BERTO | C++ | Sim | Sim | - | - | - | Sim |
| XLNet | C++ | Sim | - | - | - | - | - |
| Codificador | TensorFlow | Sim | Sim | - | - | - | - |
| Codificador | PyTorch | Sim | Sim | Sim | - | - | - |
| Decodificador | TensorFlow | Sim | - | - | - | - | - |
| Decodificador | PyTorch | Sim | - | - | - | - | - |
| Decodificação | TensorFlow | Sim | - | - | - | - | - |
| Decodificação | PyTorch | Sim | - | - | - | - | - |
| GPT | TensorFlow | Sim | - | - | - | - | - |
| GPT/OPT | PyTorch | Sim | - | - | Sim | Sim | Sim |
| GPT/OPT | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| GPT-MoE | PyTorch | Sim | - | - | Sim | Sim | - |
| FLORESCER | PyTorch | Sim | - | - | Sim | Sim | - |
| FLORESCER | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| GPT-J | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| Longformer | PyTorch | Sim | - | - | - | - | - |
| T5/UL2 | PyTorch | Sim | - | - | Sim | Sim | - |
| T5 | TensorFlow2 | Sim | - | - | - | - | - |
| T5/UL2 | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| T5 | TensorRT | Sim | - | - | Sim | Sim | - |
| T5-MoE | PyTorch | Sim | - | - | Sim | Sim | - |
| Transformador Swin | PyTorch | Sim | Sim | - | - | - | - |
| Transformador Swin | TensorRT | Sim | Sim | - | - | - | - |
| ViT | PyTorch | Sim | Sim | - | - | - | - |
| ViT | TensorRT | Sim | Sim | - | - | - | - |
| GPT-NeoX | PyTorch | Sim | - | - | Sim | Sim | - |
| GPT-NeoX | Back-end do Tritão | Sim | - | - | Sim | Sim | - |
| BART/mBART | PyTorch | Sim | - | - | Sim | Sim | - |
| WeNet | C++ | Sim | - | - | - | - | - |
| DeBERTa | TensorFlow2 | Sim | - | - | Em andamento | Em andamento | - |
| DeBERTa | PyTorch | Sim | - | - | Em andamento | Em andamento | - |
Mais detalhes de modelos específicos são colocados em xxx_guide.md de docs/ , onde xxx significa o nome do modelo. Algumas perguntas comuns e as respectivas respostas são colocadas em docs/QAList.md . Observe que os modelos do Encoder e do BERT são semelhantes e colocamos a explicação em bert_guide.md juntos.
O código a seguir lista a estrutura de diretórios do FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Observe que muitas pastas contêm muitas subpastas para dividir modelos diferentes. As ferramentas de quantização são movidas para examples , como examples/tensorflow/bert/bert-quantization/ e examples/pytorch/bert/bert-quantization-sparsity/ .
FasterTransformer fornece algumas variáveis de ambiente convenientes para depuração e teste.
FT_LOG_LEVEL : Este ambiente controla o nível de log das mensagens de depuração. Mais detalhes estão em src/fastertransformer/utils/logger.h . Observe que o programa imprimirá muitas mensagens quando o nível for inferior a DEBUG e o programa ficará muito lento.FT_NVTX : Se estiver definido como ON como FT_NVTX=ON ./bin/gpt_example , o programa inserirá a tag nvtx para ajudar a criar o perfil do programa.FT_DEBUG_LEVEL : Se estiver definido como DEBUG , o programa executará cudaDeviceSynchronize() após cada kernel. Caso contrário, o kernel será executado de forma assíncrona por padrão. É útil localizar o ponto de erro durante a depuração. Mas esse sinalizador afeta significativamente o desempenho do programa. Portanto, deve ser usado apenas para depuração. Configurações de hardware:
Para executar o benchmark a seguir, precisamos instalar a ferramenta de computação unix "bc" por
apt-get install bc Os resultados do FP16 do TensorFlow foram obtidos executando benchmarks/bert/tf_benchmark.sh .
Os resultados INT8 do TensorFlow foram obtidos executando benchmarks/bert/tf_int8_benchmark.sh .
Os resultados do FP16 do PyTorch foram obtidos executando benchmarks/bert/pyt_benchmark.sh .
Os resultados INT8 do PyTorch foram obtidos executando benchmarks/bert/pyt_int8_benchmark.sh .
Mais benchmarks são colocados em docs/bert_guide.md .
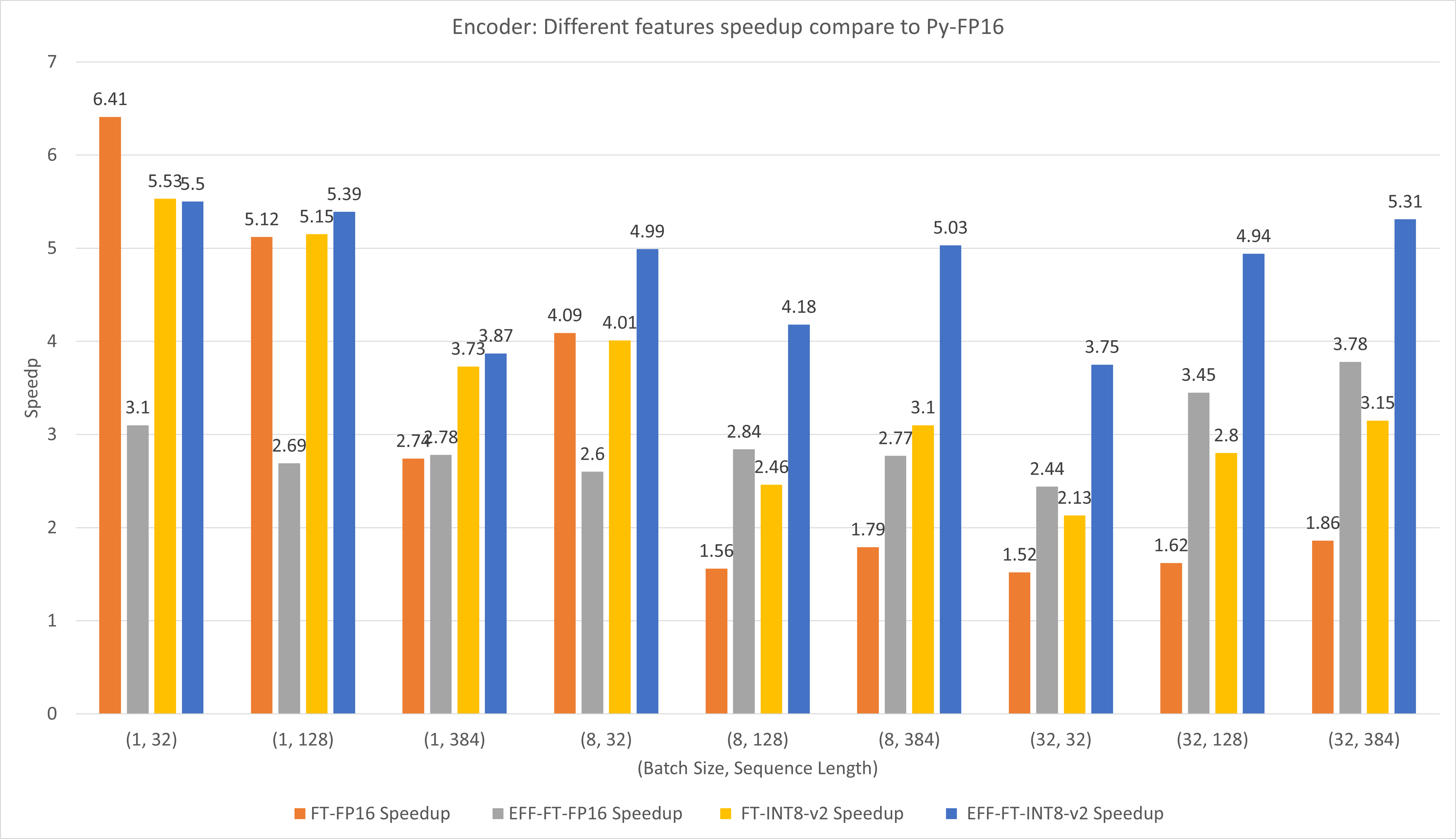
A figura a seguir compara o desempenho de diferentes recursos do FasterTransformer e do FasterTransformer no FP16 no T4.
Para lotes grandes e comprimentos de sequência, tanto o EFF-FT quanto o FT-INT8-v2 proporcionam uma aceleração de 2x. Usar o Effective FasterTransformer e o int8v2 ao mesmo tempo pode trazer uma aceleração de 3,5x em comparação com o FasterTransformer FP16 para gabinetes grandes.
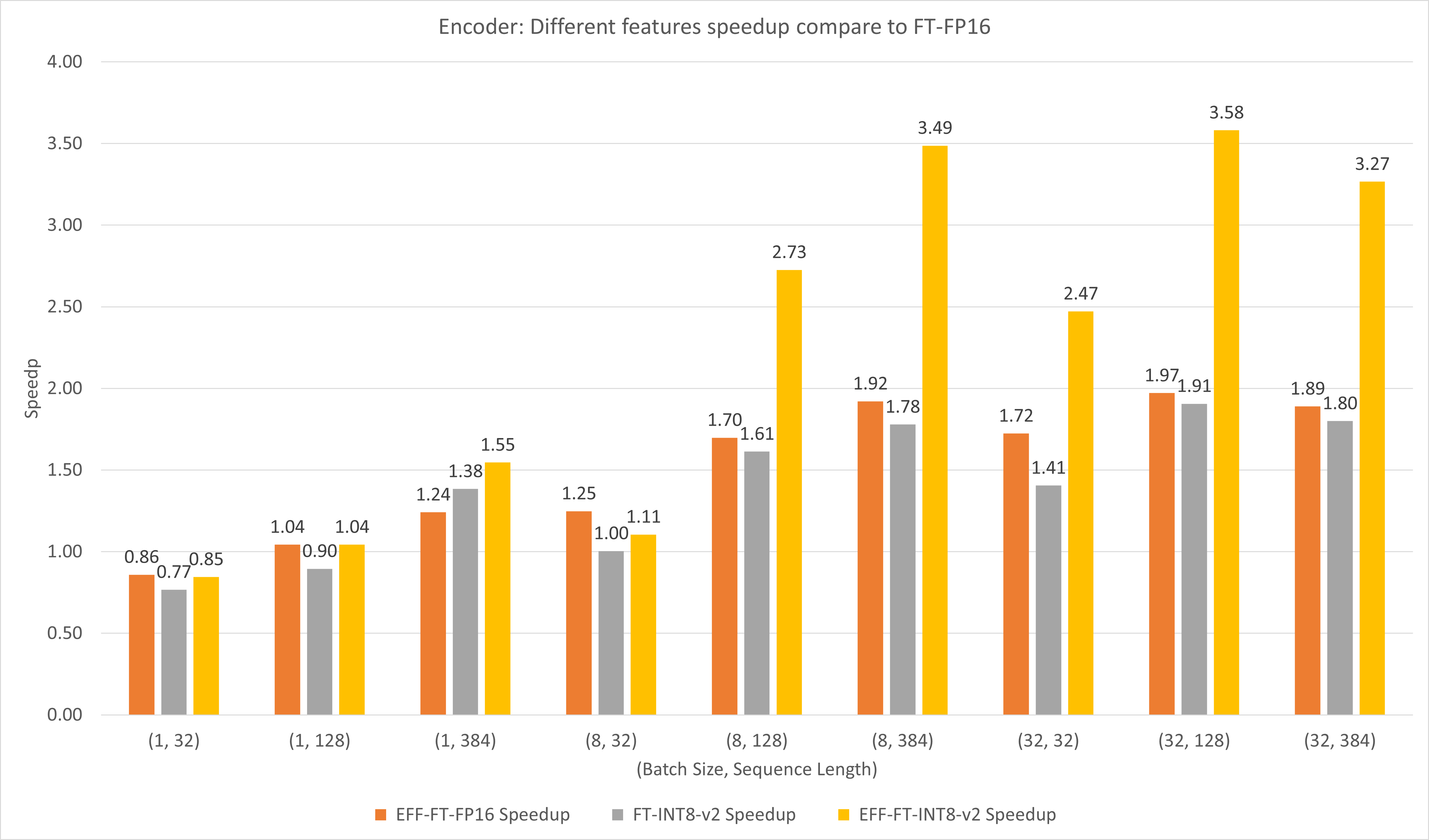
A figura a seguir compara o desempenho de diferentes recursos do FasterTransformer e do TensorFlow XLA no FP16 no T4.
Para tamanhos de lote e comprimento de sequência pequenos, o uso do FasterTransformer pode gerar uma aceleração de 3x.
Para lotes grandes e comprimentos de sequência, o uso do Effective FasterTransformer com quantização INT8-v2 pode gerar uma aceleração de 5x.
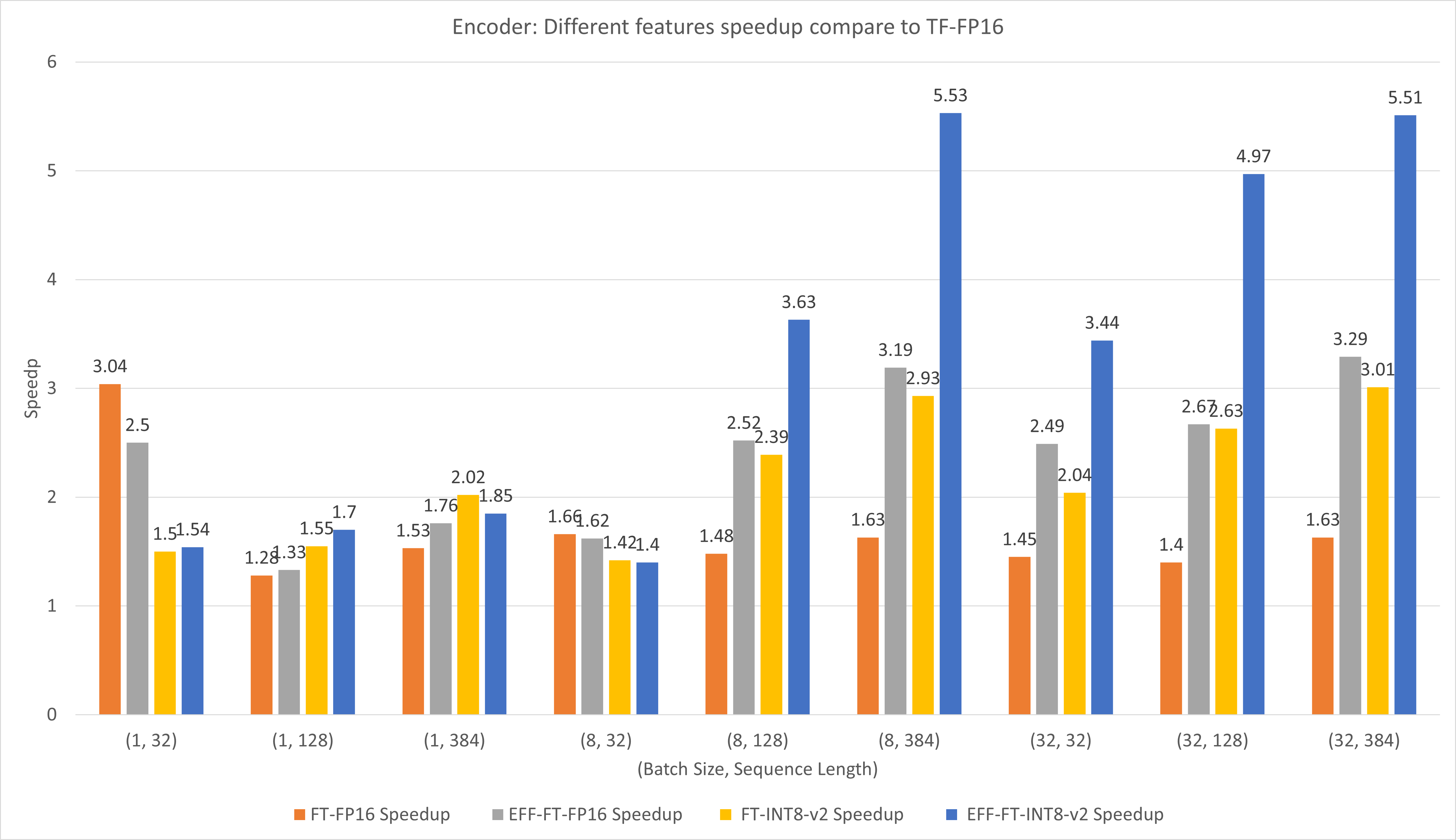
A figura a seguir compara o desempenho de diferentes recursos do FasterTransformer e PyTorch TorchScript no FP16 no T4.
Para tamanhos de lote e comprimento de sequência pequenos, o uso do FasterTransformer CustomExt pode gerar uma aceleração de 4x a 6x.
Para lotes grandes e comprimentos de sequência, o uso do Effective FasterTransformer com quantização INT8-v2 pode gerar uma aceleração de 5x.
Os resultados do TensorFlow foram obtidos executando benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh e benchmarks/decoding/tf_decoding_sampling_benchmark.sh
Os resultados do PyTorch foram obtidos executando benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh .
Nos experimentos de decodificação, atualizamos os seguintes parâmetros:
Mais benchmarks são colocados em docs/decoder_guide.md .
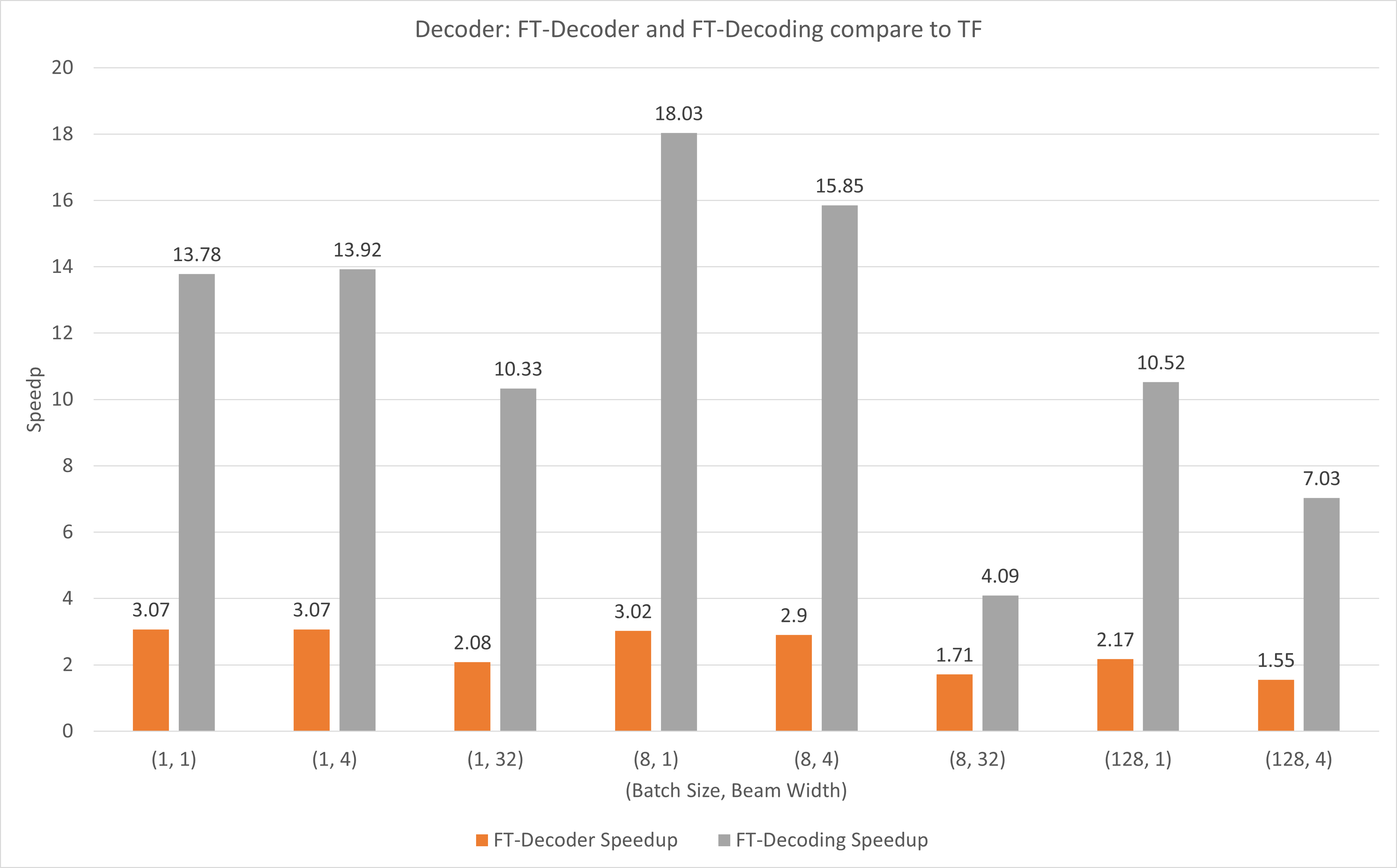
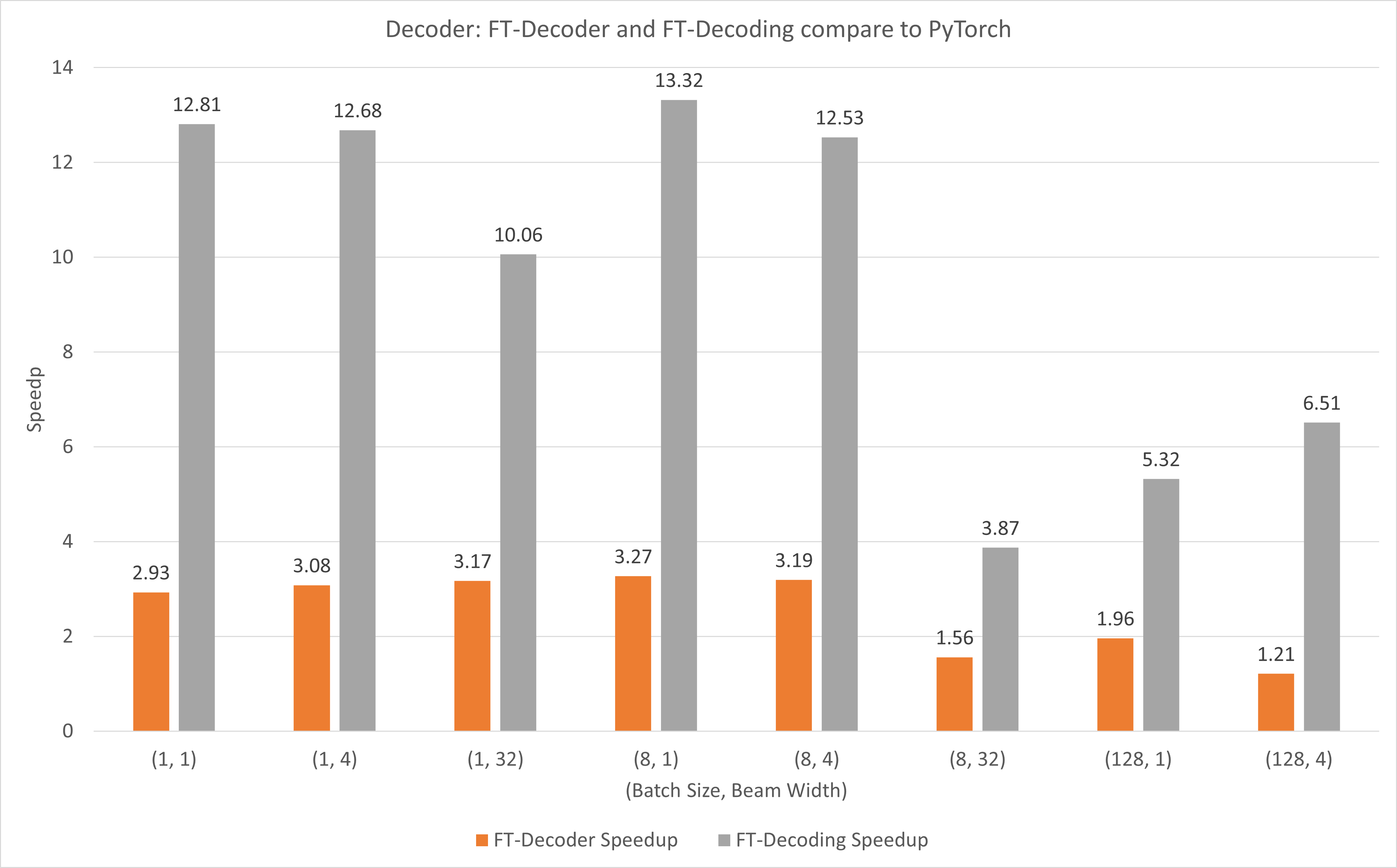
A figura a seguir mostra a aceleração da operação do FT-Decoder e da operação FT-Decoding em comparação com o TensorFlow no FP16 com T4. Aqui, usamos o rendimento da tradução de um conjunto de testes para evitar que o total de tokens de cada método possa ser diferente. Comparado ao TensorFlow, o FT-Decoder oferece aceleração de 1,5x ~ 3x; enquanto a decodificação FT fornece aceleração de 4x ~ 18x.
A figura a seguir mostra a aceleração da operação FT-Decoder e FT-Decoding em comparação com PyTorch em FP16 com T4. Aqui, usamos o rendimento da tradução de um conjunto de testes para evitar que o total de tokens de cada método possa ser diferente. Comparado ao PyTorch, o FT-Decoder oferece aceleração de 1,2x ~ 3x; enquanto a decodificação FT fornece aceleração de 3,8x ~ 13x.
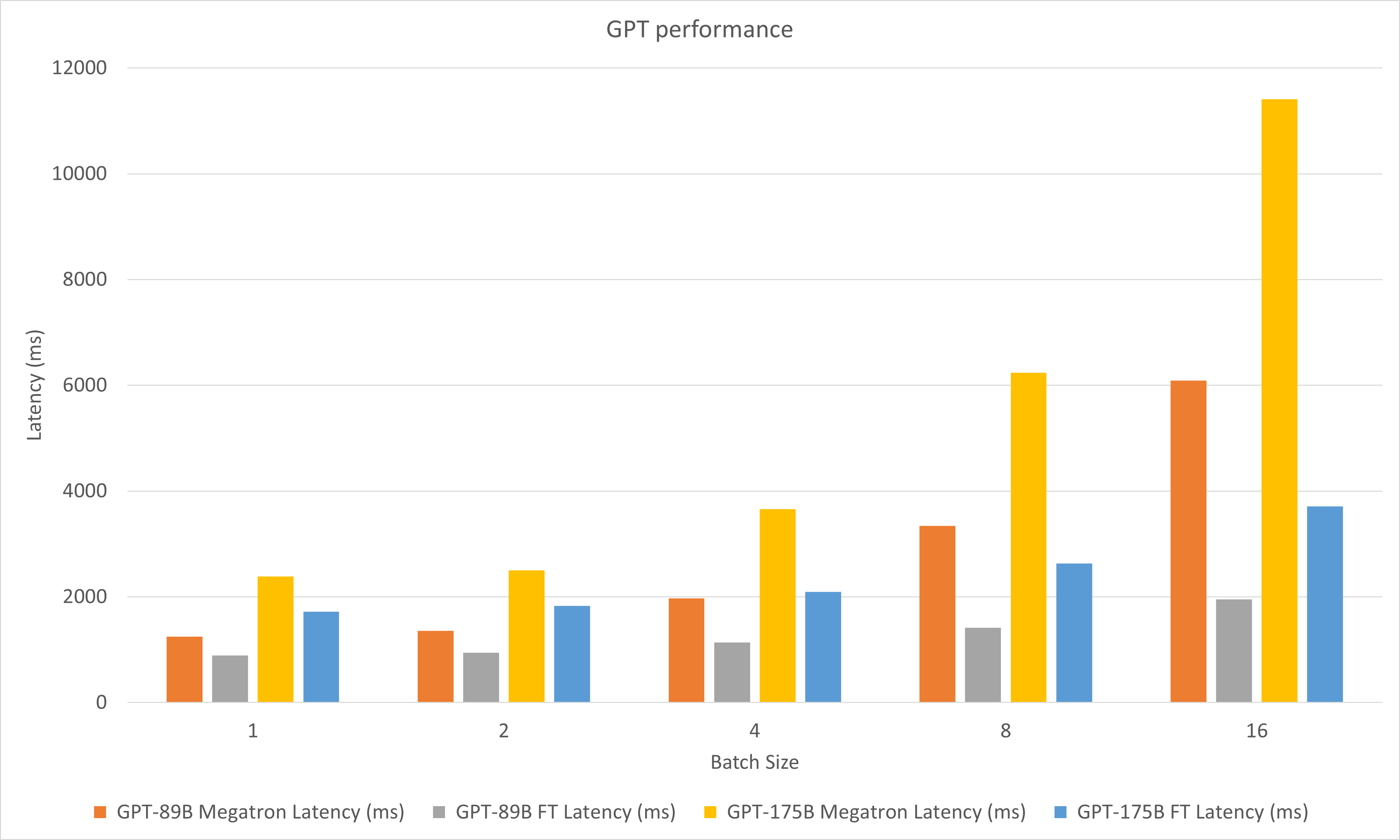
A figura a seguir compara o desempenho do Megatron e do FasterTransformer no FP16 no A100.
Nos experimentos de decodificação, atualizamos os seguintes parâmetros:
Maio de 2023
Janeiro de 2023
dezembro de 2022
Novembro de 2022
Outubro de 2022
Setembro de 2022
agosto de 2022
Julho de 2022
Junho de 2022
Maio de 2022
Abril de 2022
Março de 2022
stop_ids e ban_bad_ids em GPT-J.start_id e end_id dinâmicos em GPT-J, GPT, T5 e Decodificação.Fevereiro de 2022
Dezembro de 2021
Novembro de 2021
Agosto de 2021
layer_para para pipeline_para .size_per_head 96, 160, 192, 224, 256 para modelo GPT.Junho de 2021
Abril de 2021
Dezembro de 2020
Novembro de 2020
Setembro de 2020
agosto de 2020
Junho de 2020
Maio de 2020
translate_sample.py .Abril de 2020
decoding_opennmt.h para decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h , bert_transformer_op.cu.cc em bert_transformer_op.ccdecoder.h , decoder.cu.cc em decoder.ccdecoding_beamsearch.h , decoding_beamsearch.cu.cc em decoding_beamsearch.ccbleu_score.py em utils . Observe que a pontuação BLEU requer python3.Março de 2020
translate_sample.py para demonstrar como traduzir uma frase restaurando o modelo pré-treinado do OpenNMT-tf.Fevereiro de 2020
Julho de 2019
import torch primeiro. Se isso foi feito, é devido à ABI C++ incompatível. Pode ser necessário verificar se o PyTorch usado durante a compilação e a execução são os mesmos, ou você precisa verificar como o seu PyTorch é compilado, ou a versão do seu GCC, etc.

