PatrickStar
v0.4.6

Consulte CHANGE_LOG.md.
Modelos pré-treinados (PTM) estão se tornando o ponto principal tanto da pesquisa de PNL quanto da aplicação na indústria. No entanto, o treinamento de PTMs requer enormes recursos de hardware, tornando-o acessível apenas a uma pequena parcela de pessoas da comunidade de IA. Agora, a PatrickStar disponibilizará o treinamento PTM para todos!
Erro de falta de memória (OOM) é o pesadelo de todo engenheiro que treina PTMs. Freqüentemente, temos que introduzir mais GPUs para armazenar os parâmetros do modelo e evitar tais erros. PatrickStar traz uma solução melhor para esse problema. Com o treinamento heterogêneo (DeepSpeed Zero Stage 3 também o utiliza), PatrickStar poderia usar totalmente a memória da CPU e da GPU para que você pudesse usar menos GPUs para treinar modelos maiores.
A ideia de Patrick é assim. Os dados não-modelo (principalmente ativações) variam durante o treinamento, mas as atuais soluções de treinamento heterogêneas estão dividindo estaticamente os dados do modelo em CPU e GPU. Para melhor utilizar a GPU, PatrickStar propõe um escalonamento dinâmico de memória com a ajuda de um módulo de gerenciamento de memória baseado em blocos. O gerenciamento de memória do PatrickStar suporta o descarregamento de tudo, exceto a parte de computação atual do modelo, para a CPU para economizar GPU. Além disso, o gerenciamento de memória baseado em blocos é eficiente para comunicação coletiva ao escalar para múltiplas GPUs. Veja o artigo e este documento para conhecer a ideia por trás do PatrickStar.
No experimento, Patrickstar v0.4.3 é capaz de treinar um modelo de parâmetros de 18 bilhões (18B) com 8xTesla V100 GPU e 240GB de memória GPU no nó do datacenter WeChat, cuja topologia de rede é assim. PatrickStar é duas vezes maior que DeepSpeed. E o desempenho do PatrickStar também é melhor para modelos do mesmo tamanho. A pstar é PatrickStar v0.4.3. As profundezas indicam o desempenho do DeepSpeed v0.4.3 usando o exemplo oficial do estágio zero3 do DeepSpeed com otimizações de ativação abrindo por padrão.

Também avaliamos o PatrickStar v0.4.3 em um único nó do A100 SuperPod. Ele pode treinar o modelo 68B em 8xA100 com memória de CPU de 1 TB, que é 6x maior que o DeepSpeed v0.5.7. Além da escala do modelo, o PatrickStar é muito mais eficiente que o DeepSpeed. Os scripts de benchmark estão aqui.

Resultados detalhados de benchmark no data center WeChat AI e NVIDIA SuperPod são publicados neste Google Doc.
Dimensione o PatrickStar para várias máquinas (nó) no SuperPod. Conseguimos treinar um GPT3-175B em 32 GPU. Pelo que sabemos, é o primeiro trabalho a executar GPT3 em um cluster de GPU tão pequeno. A Microsoft usou 10.000 V100 para pertencer ao GPT3. Agora você pode ajustá-lo ou até mesmo pré-treinar o seu próprio na GPU 32 A100, incrível!

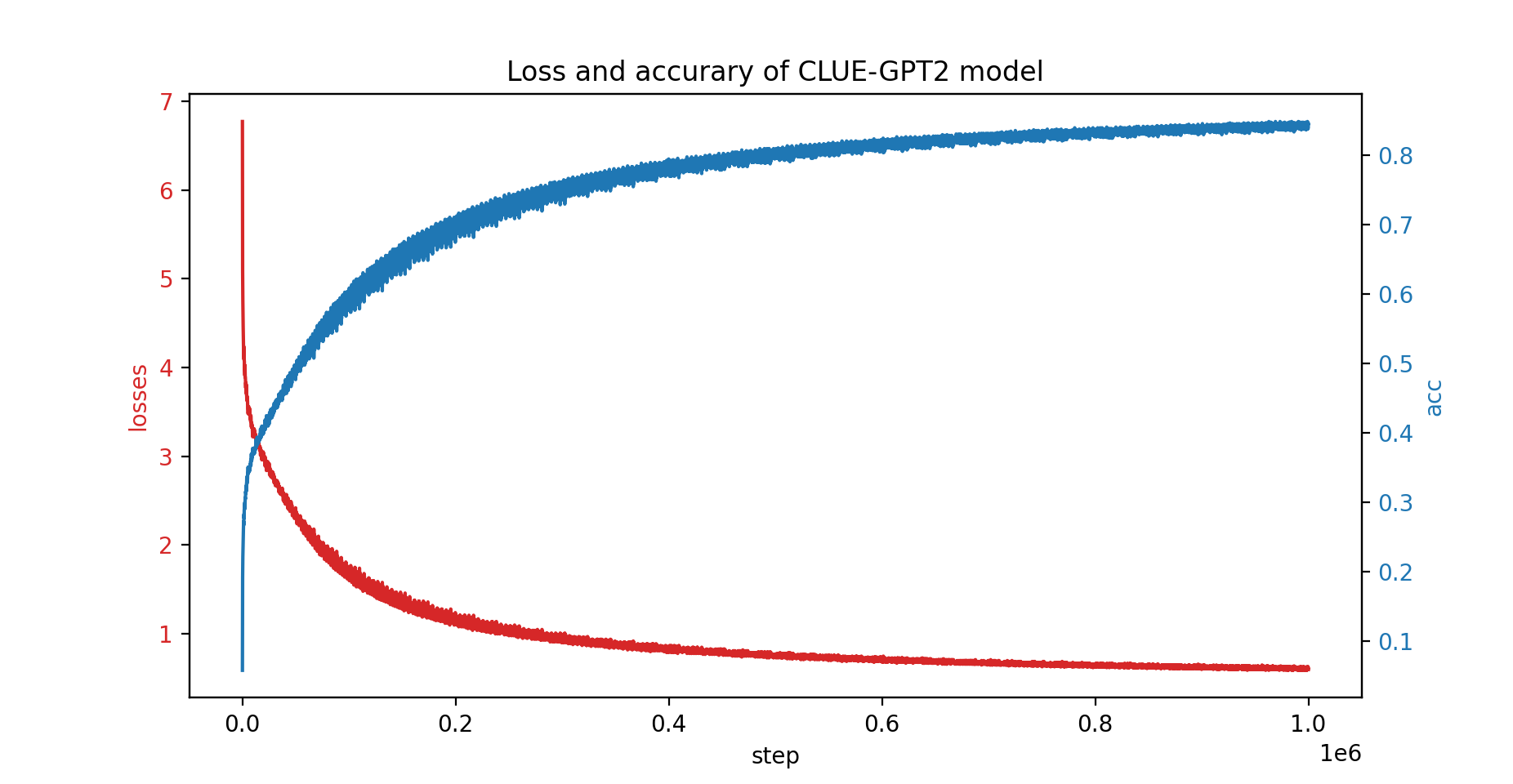
Também treinamos o modelo CLUE-GPT2 com PatrickStar, a curva de perda e precisão é mostrada abaixo:
pip install .Observe que PatrickStar requer gcc versão 7 ou superior. Você também pode usar imagens NVIDIA NGC, a seguinte imagem é testada:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar é baseado em PyTorch, facilitando a migração de um projeto pytorch. Aqui está um exemplo de PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Usamos o mesmo formato config do JSON de configuração do DeepSpeed, que inclui principalmente parâmetros de otimizador, escalonador de perda e algumas configurações específicas do PatrickStar.
Para uma explicação detalhada do exemplo acima, verifique o guia aqui
Para mais exemplos, verifique aqui.
Um script de benchmark de início rápido está aqui. É executado com dados gerados aleatoriamente; portanto, você não precisa preparar os dados reais. Também demonstrou todas as técnicas de otimização do patrickstar. Para obter mais truques de otimização executando o benchmark, consulte Opções de otimização.
Licença BSD de 3 cláusulas
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
Desenvolvido pela equipe WeChat AI, Tencent NLP Oteam.


