xcodec
1.0.0
Codec Semântico e Acústico Unificado para Modelo de Linguagem de Áudio.
Título : Codec é importante: explorando a deficiência semântica do codec para modelo de linguagem de áudio
Autores : Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo*, Wei Xue*
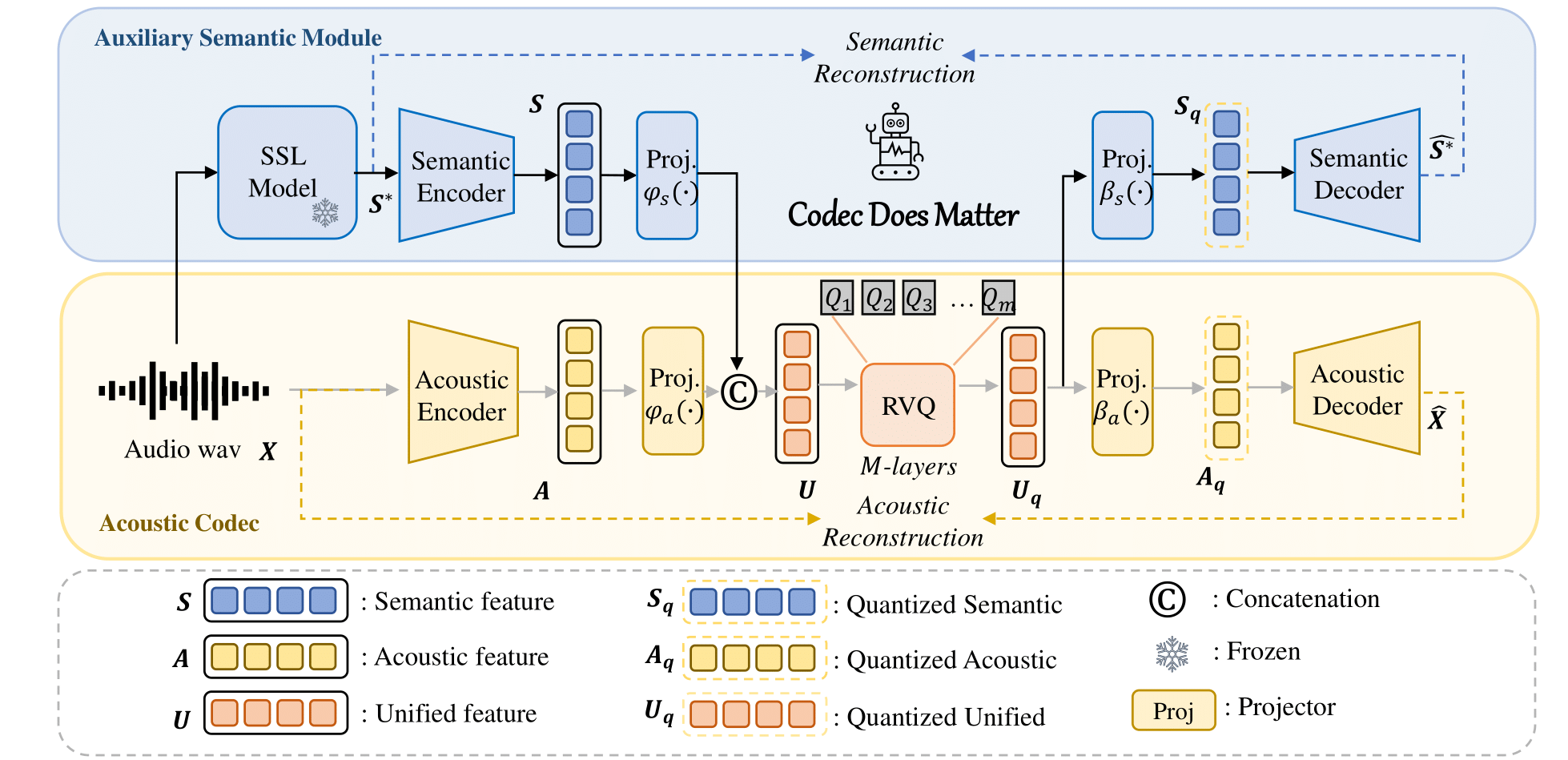
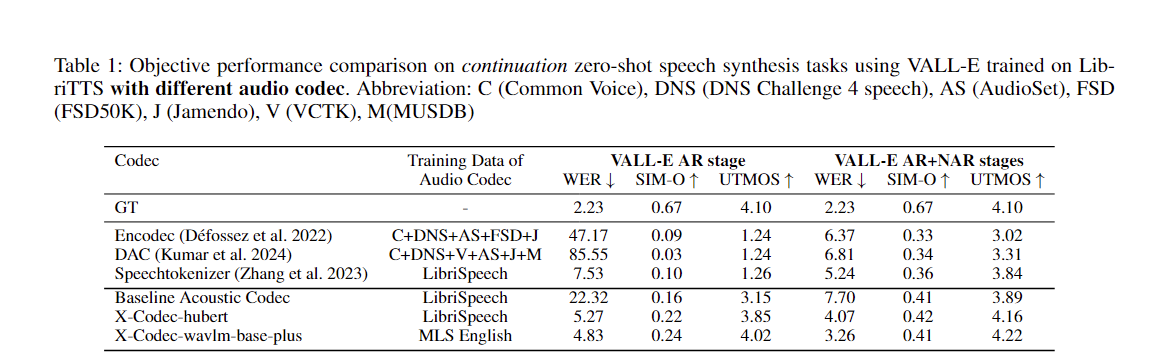
Você pode aplicar facilmente nossa abordagem para aprimorar qualquer codec acústico existente:
Por exemplo
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) Para mais detalhes, consulte nosso código.
? links para o hub do modelo Huggingface.
| Nome do modelo | Abraçando o rosto | Configuração | Modelo Semântico | Domínio | Dados de treinamento |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ? Base Hubert | Discurso | Librispeech |
| xcodec_wavlm_mls (não mencionado no artigo) | ? | ? | ? Wavlm-base-plus | Discurso | MLS Inglês |
| xcodec_wavlm_more_data (não mencionado no artigo) | ? | ? | ? Wavlm-base-plus | Discurso | MLS Inglês + Dados internos |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-geral-áudio | Áudio geral | 200 mil horas de dados internos |
| xcodec_hubert_general_audio_more_data (não mencionado no artigo) | ? | ? | ?Hubert-base-geral-áudio | Áudio geral | Dados mais equilibrados |
Para executar a inferência, primeiro baixe o modelo e configure do huging face.
python inference.pyPrepare o training_file e o validação_file em config. O arquivo deve listar os caminhos para seus arquivos de áudio:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...Então:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyGostaria de agradecer especialmente aos autores do Uniaudio e DAC, já que nossa base de código é emprestada principalmente do Uniaudio e DAC.
Se você achar este repositório útil, considere citar no seguinte formato:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

