FinGLM
1.0.0
Link da pergunta da competição | Página de promoção da pergunta da competição |
? FinGLM : Comprometido com a construção de um grande projeto de modelo financeiro aberto, de bem-estar público e duradouro, usando código aberto para promover "IA + finanças".
[Atualização 23/11/2023] Adicionado conteúdo do curso para os modelos ChatGLM-6B de 1ª, 2ª e 3ª geração, incluindo PPT, vídeos e documentos técnicos.
【Atualização 2023/11/17】Adicionada uma nova solução "Nomeie como quiser"
? Um sistema conversacional interativo inteligente projetado para analisar profundamente os relatórios anuais das empresas listadas. Face aos termos profissionais e às informações implícitas nos textos financeiros, estamos empenhados em utilizar a IA para obter análises financeiras de nível especializado.
No domínio da IA, embora tenham sido feitos progressos no diálogo por texto, os cenários reais de interação financeira ainda constituem um enorme desafio. Várias instituições organizaram em conjunto esta competição para explorar os limites da IA no campo financeiro.
O relatório anual de uma empresa listada apresenta aos investidores a situação operacional, financeira e os planos futuros da empresa. A experiência é a chave para a interpretação, e nosso objetivo é tornar esse processo mais fácil e preciso por meio da tecnologia de IA.
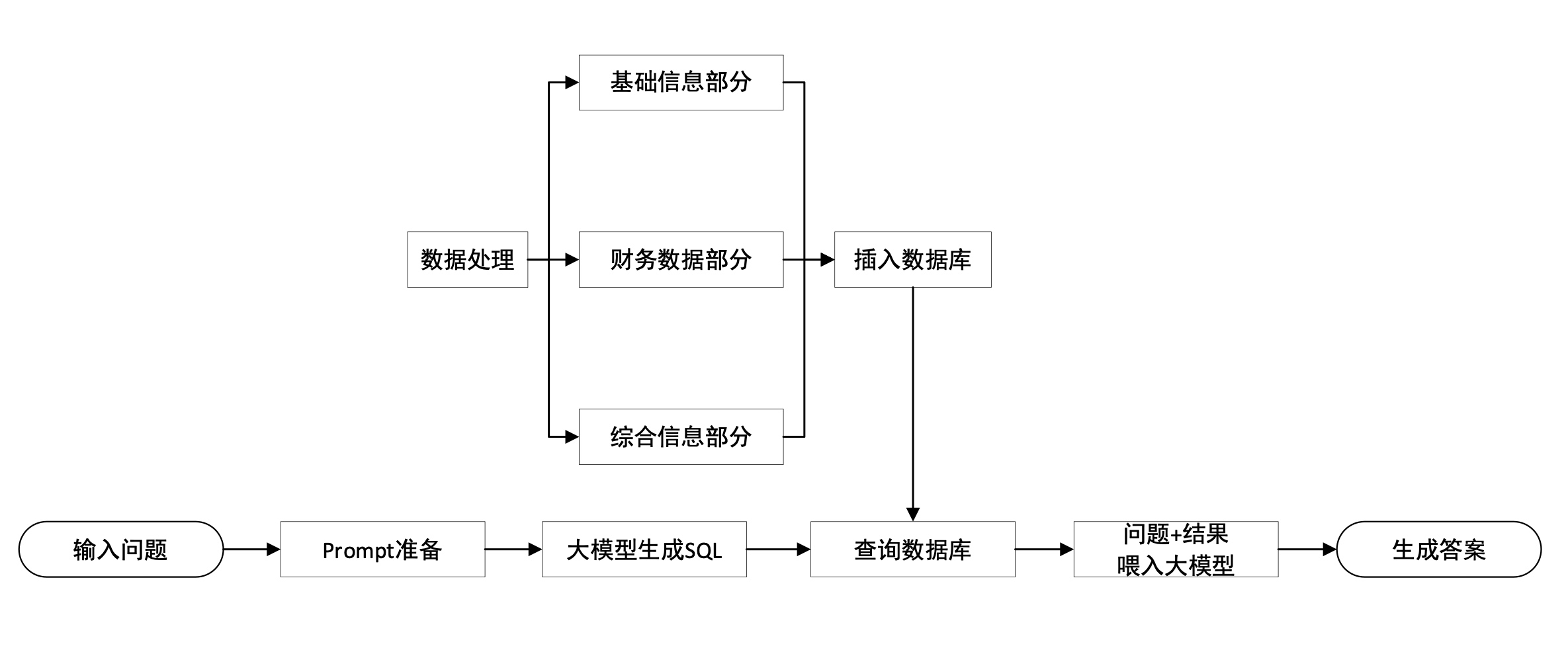
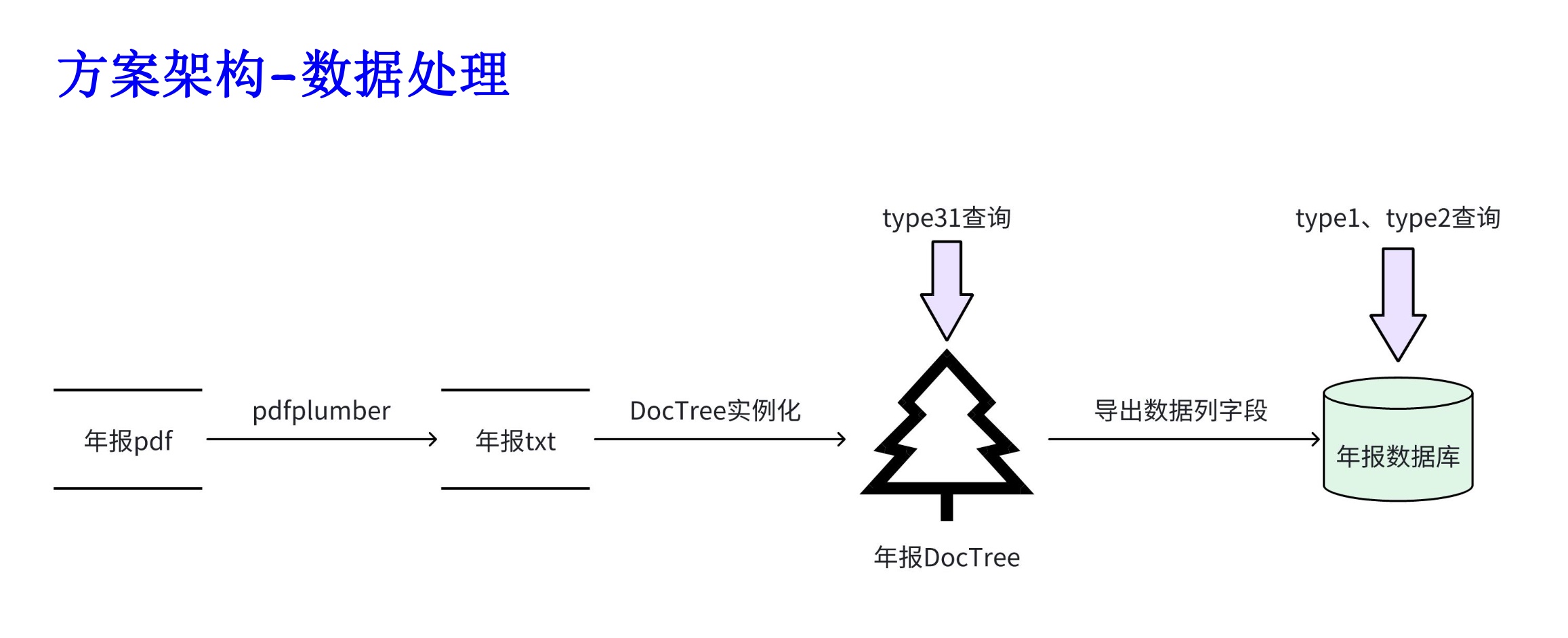
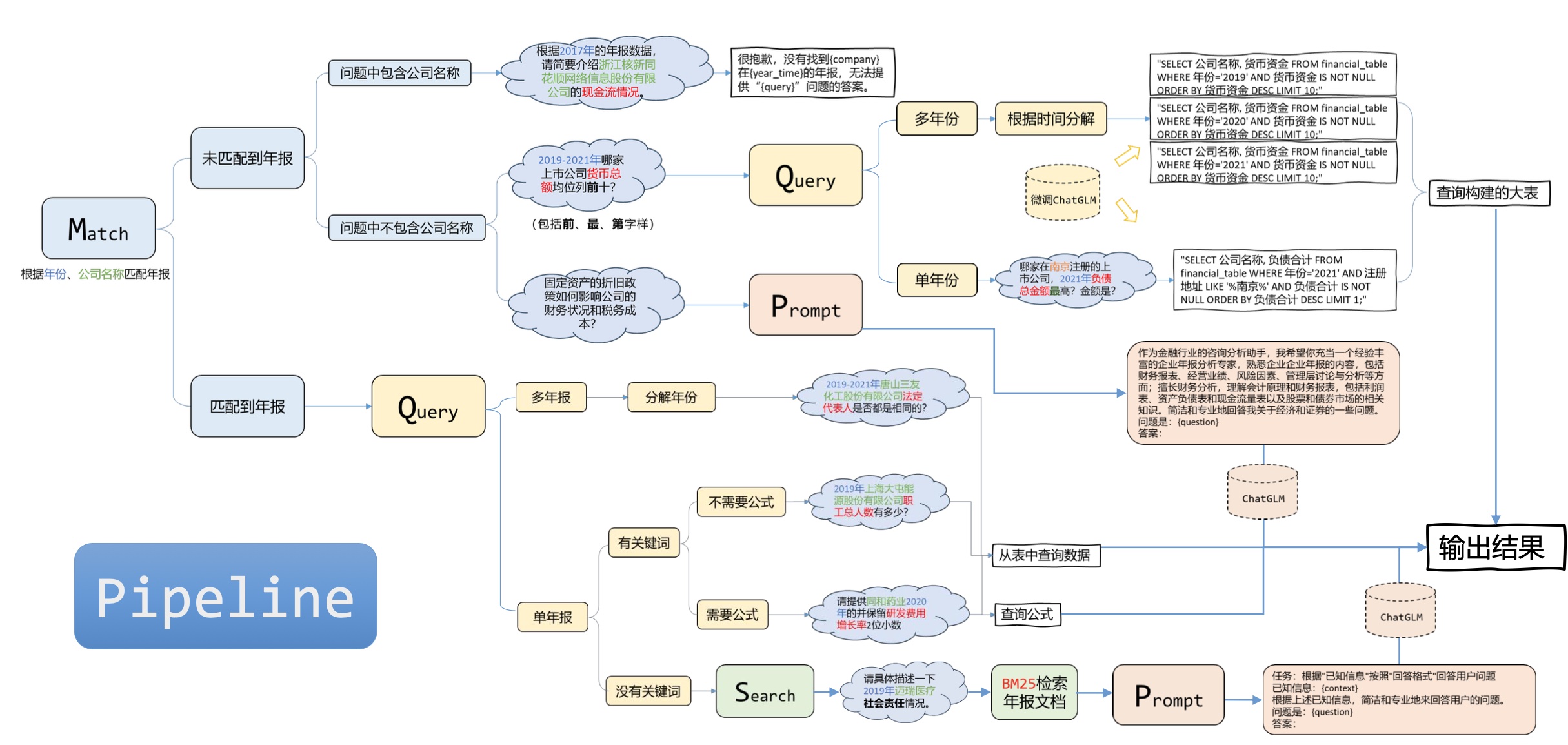
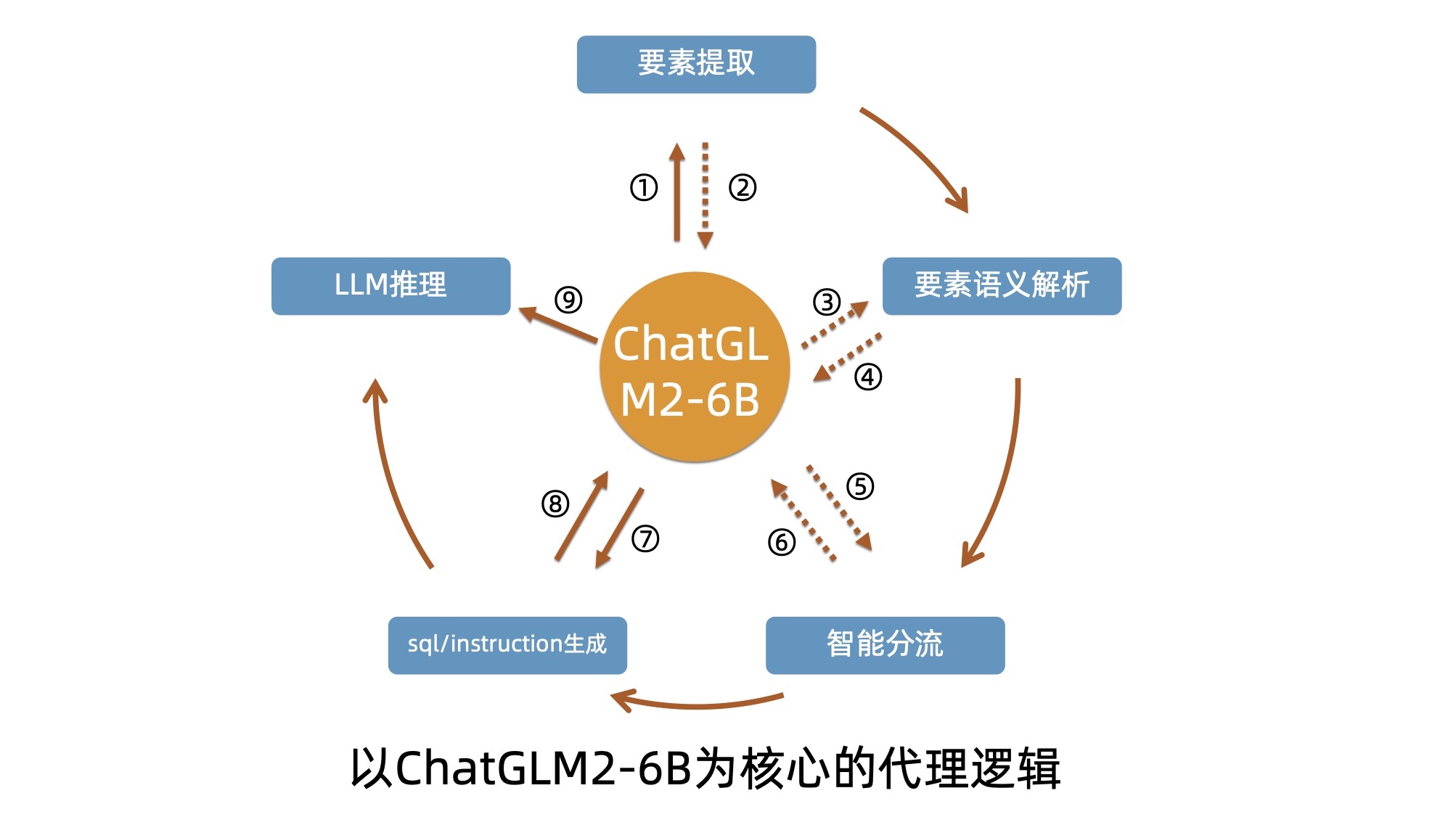
PDF para TXT :
Segmentação de dados :
Processamento de dados :
Salvar no banco de dados :
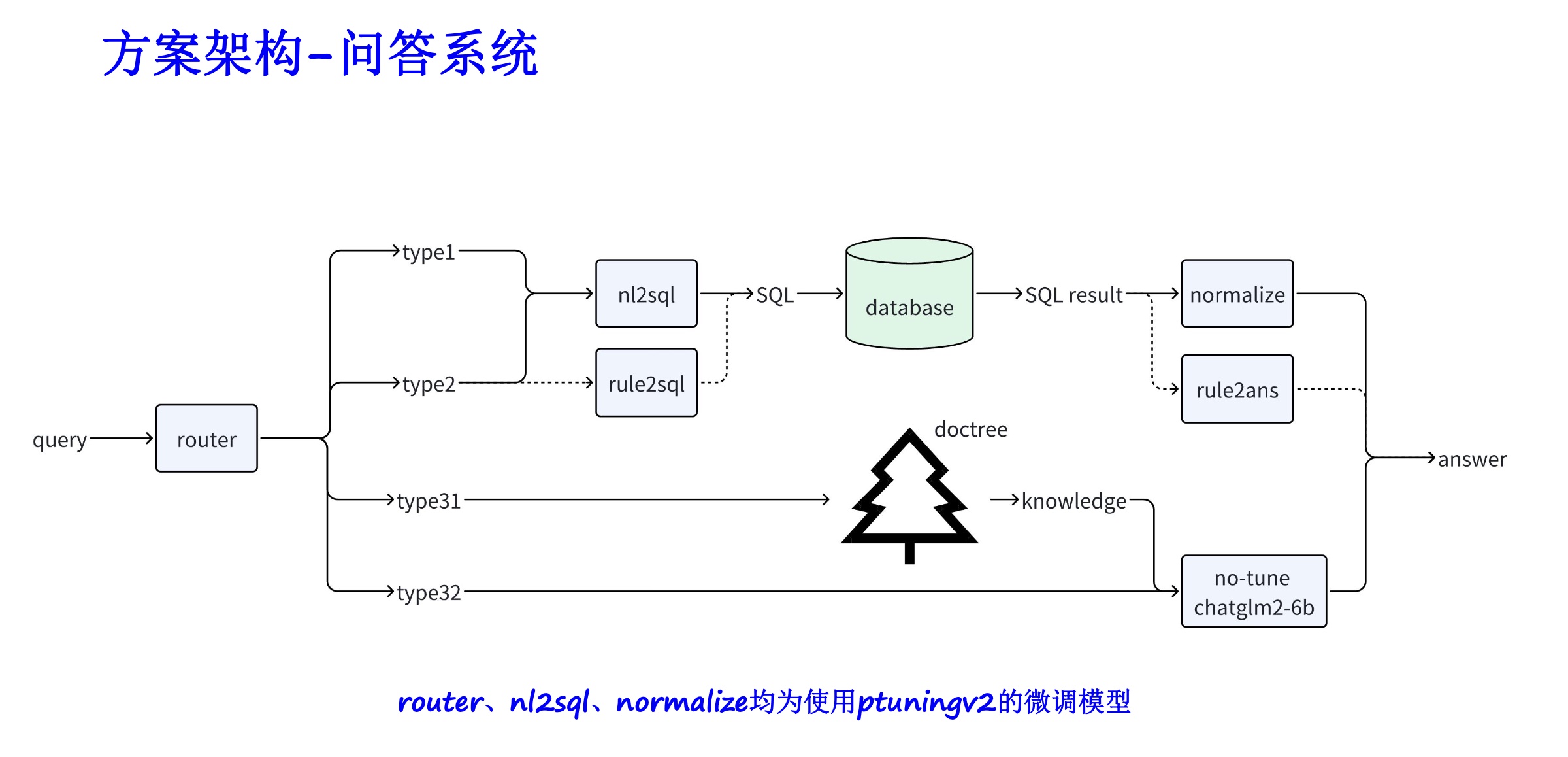
Classificação de dados : como dados SQL, dados ES, etc.
Selecione uma estratégia de ajuste fino : como ptuningv2, lora, etc.
Execute o ajuste fino : com base na estratégia selecionada.
1) Transformação de evento
2) Dados de código aberto
3) Soluções/códigos/modelos de código aberto
4) Comunicação aberta
5) Tutoriais de estudo
6) Conjunto de recursos do projeto
Primeira questão:
pdf2txt.py para analisar arquivos PDF. Segunda questão:
Blog de introdução do projeto:
[PPT] [Vídeo][Código]
Este projeto é uma integração da equipe Anshuoshuo Eye Exploration Enterprise com base em seu próprio projeto e nos projetos de várias outras equipes. Continuaremos a iterar e atualizar esse projeto no futuro.
[PPT] [Vídeo] [Código] 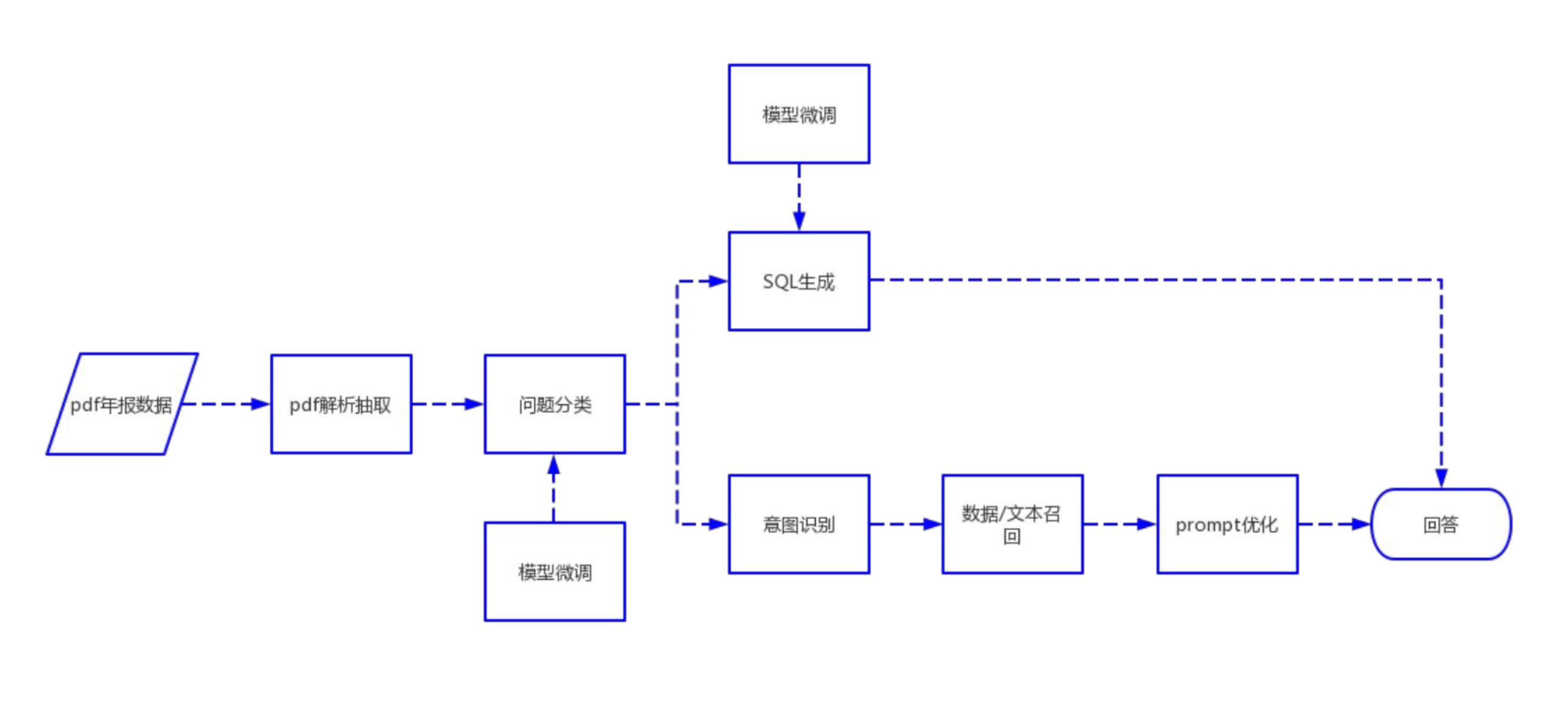
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]

[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo][Código]
Nosso conjunto de dados de código aberto abrange os relatórios anuais de algumas empresas listadas de 2019 a 2021. Este conjunto de dados contém um total de 11.588 arquivos PDF detalhados (lista). Você pode usar o conteúdo desses arquivos PDF para construir o banco de dados ou a biblioteca de vetores necessária. Para evitar o desperdício de recursos computacionais, também convertemos os arquivos correspondentes em arquivos TXT e HTML para uso de todos.
Tamanho: 69 GB Formato do arquivo: arquivo pdf Número de arquivos: 11588
carregar
# 要求安装 git lfs
git clone http://www.modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset.git
carregamento do SDK
# Note:
# 1. 【重要】请将modelscope sdk升级到v1.7.2rc0,执行: pip3 install "modelscope==1.7.2rc0" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 2. 【重要】datasets版本限制为 >=2.8.0, <=2.13.0,可执行: pip3 install datasets==2.13.0
from modelscope.msdatasets import MsDataset
# 使用流式方式加载「推荐」
# 无需全量加载到cache,随下随处理
# 其中,通过设置 stream_batch_size 可以使用batch的方式加载
ds = MsDataset.load('chatglm_llm_fintech_raw_dataset', split='train', use_streaming=True, stream_batch_size=1)
for item in ds:
print(item)
# 加载结果示例(单条,pdf:FILE字段值为该pdf文件本地缓存路径,文件名做了SHA转码,可以直接打开)
{'name': ['2020-03-24__北京鼎汉技术集团股份有限公司__300011__鼎汉技术__2019年__年度报告.pdf'], 'pdf:FILE': ['~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/430da7c46fb80d4d095a57b4fb223258ffa1afe8bf53d0484e3f2650f5904b5c']}
# 备注:
1. 自定义缓存路径,可以自行设置cache_dir参数,即 MsDataset.load(..., cache_dir='/to/your/path')
2. 补充数据加载(从9493条增加到11588条),sdk加载注意事项
a) 删除缓存中的csv映射文件(默认路径为): ~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/732dc4f3b18fc52380371636931af4c8
b) 使用MsDataset.load(...) 加载,默认会reuse已下载过的文件,不会重复下载。
Nota: Converta o arquivo no formato pdf para txt para facilitar a reutilização (um arquivo está danificado, então o número total é 1 a menos que pdf, 11587 no total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip -OutFile D:\alltxt.zip
Nota: Converta arquivos no formato pdf para html para facilitar a reutilização (um arquivo está danificado, portanto o número total é menor que pdf, 11.582 no total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip -OutFile D:\allhtml.zip
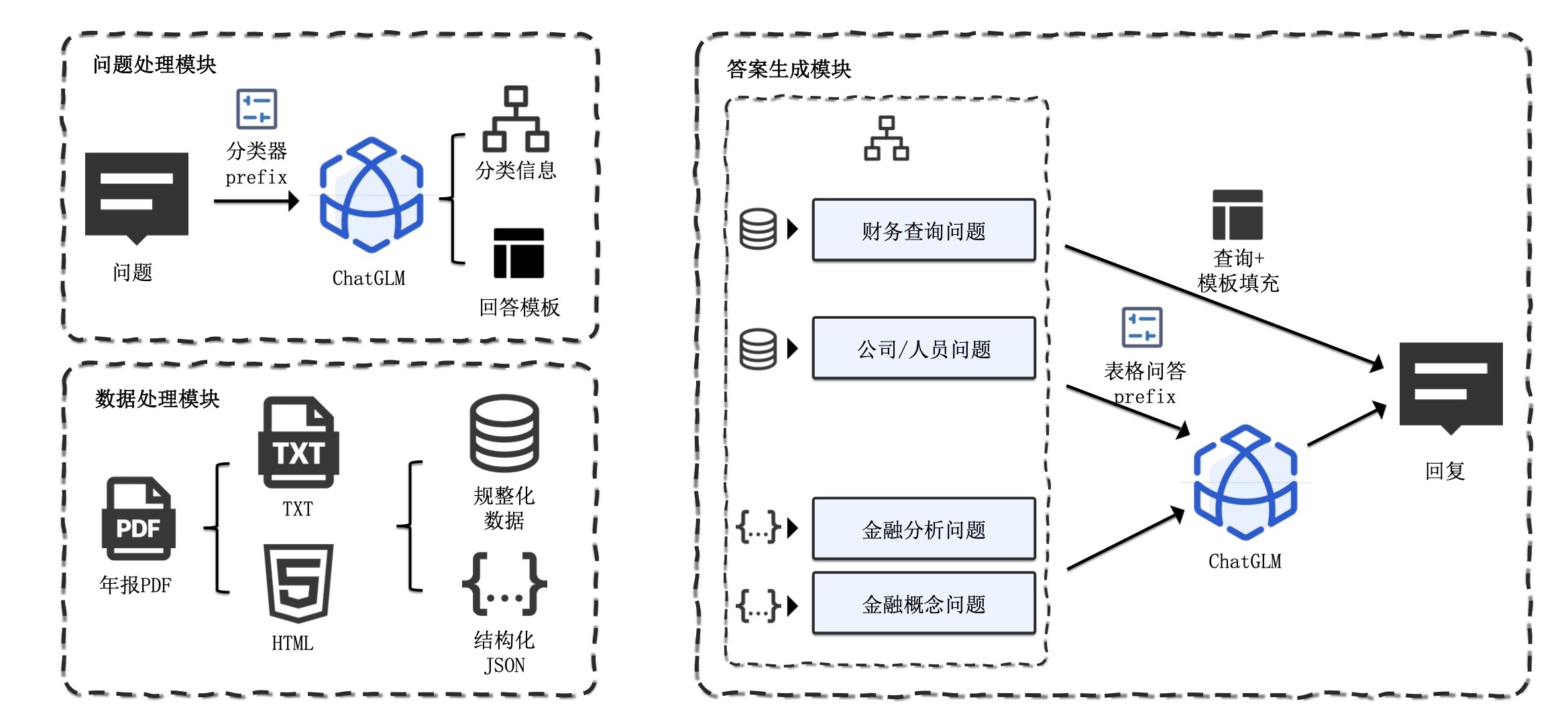
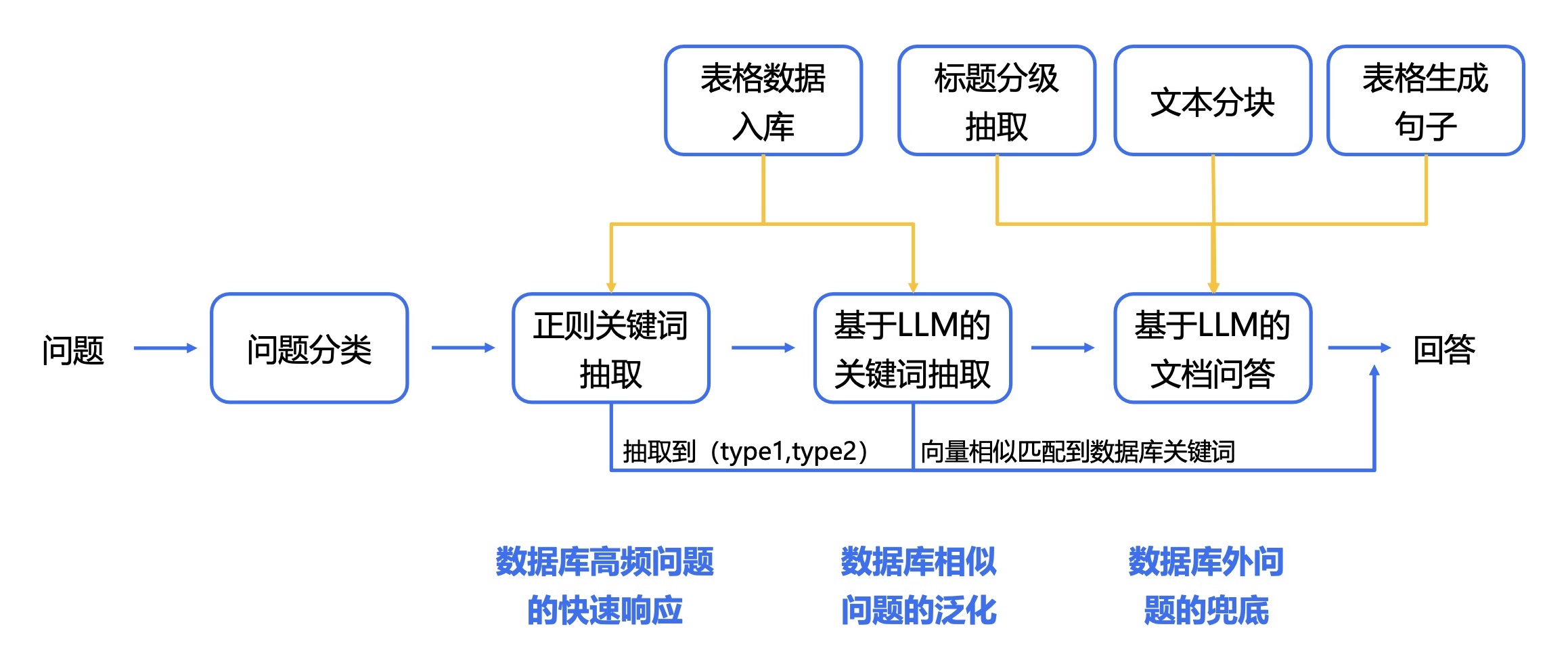
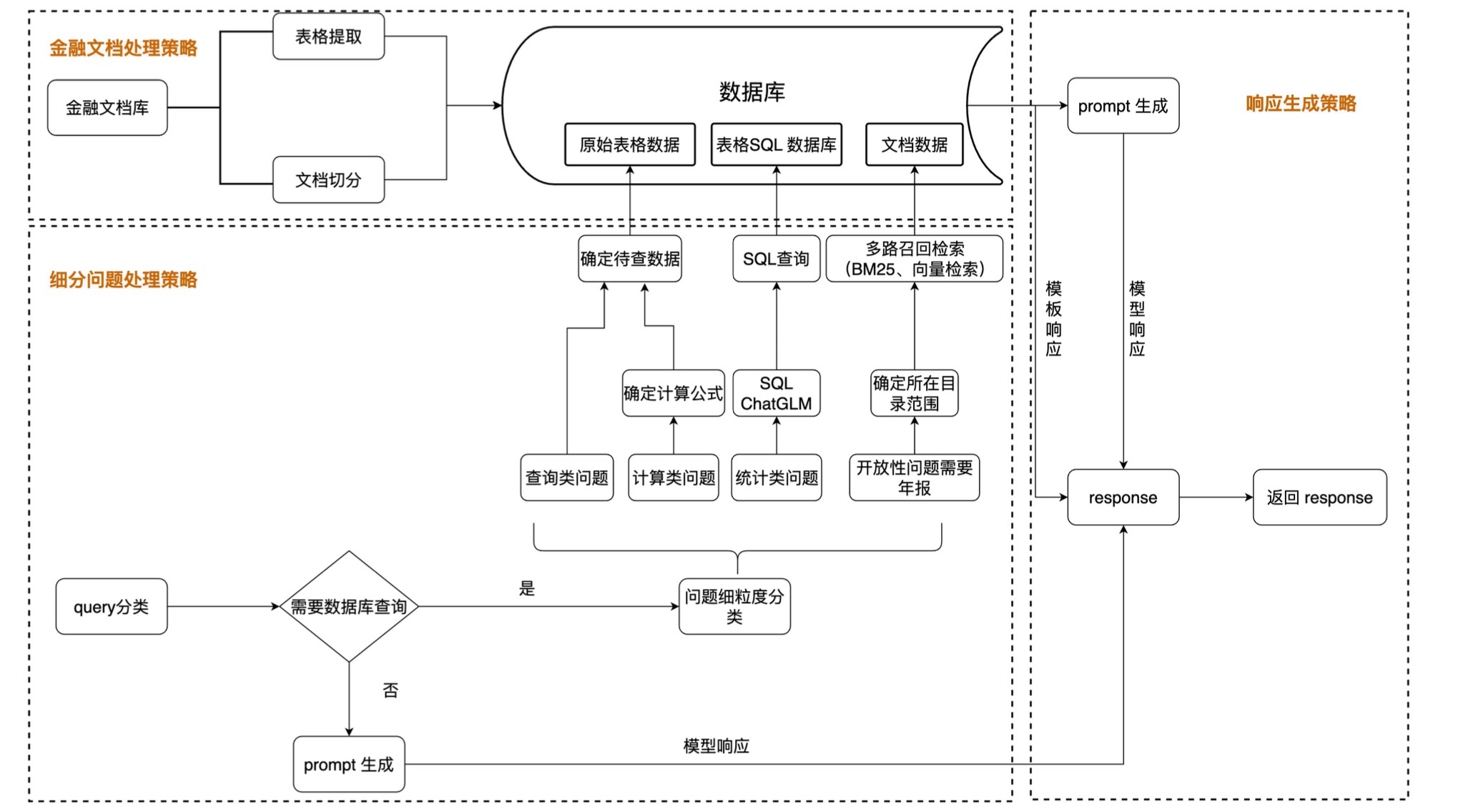
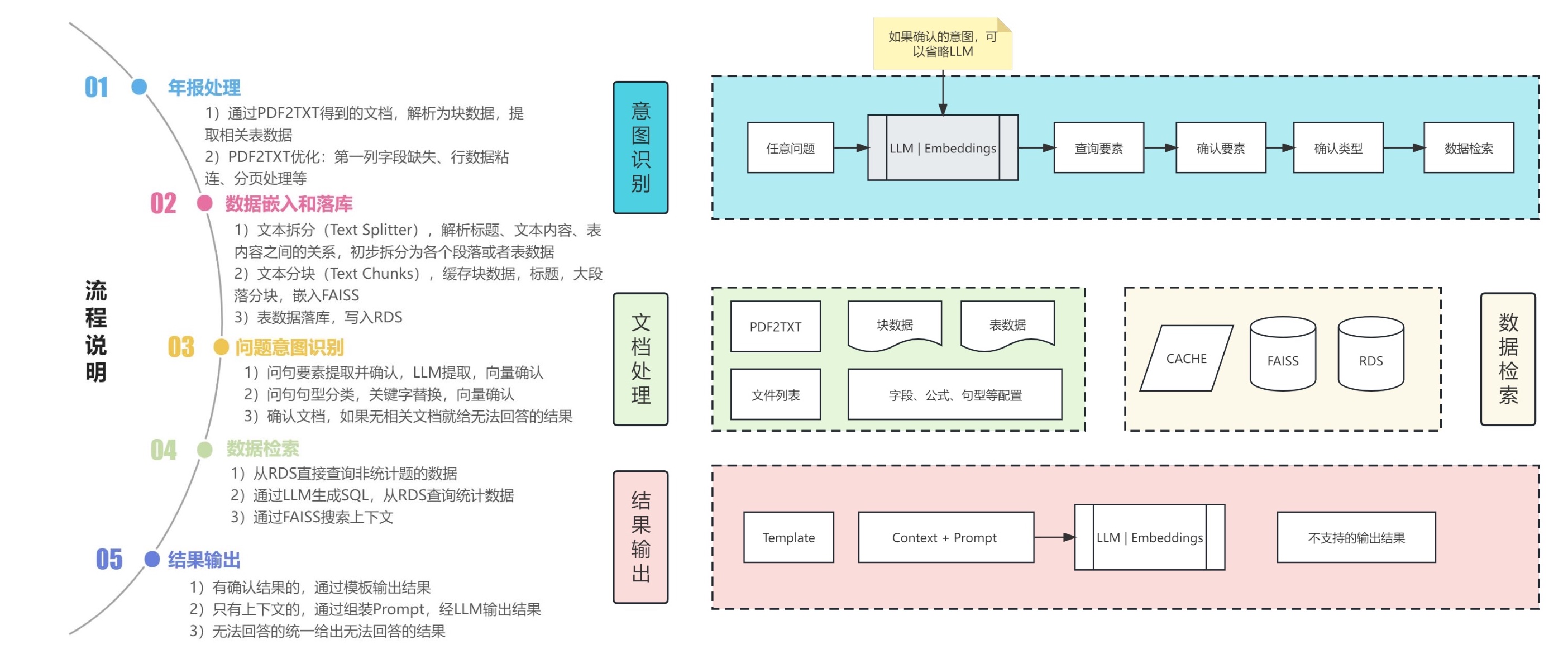
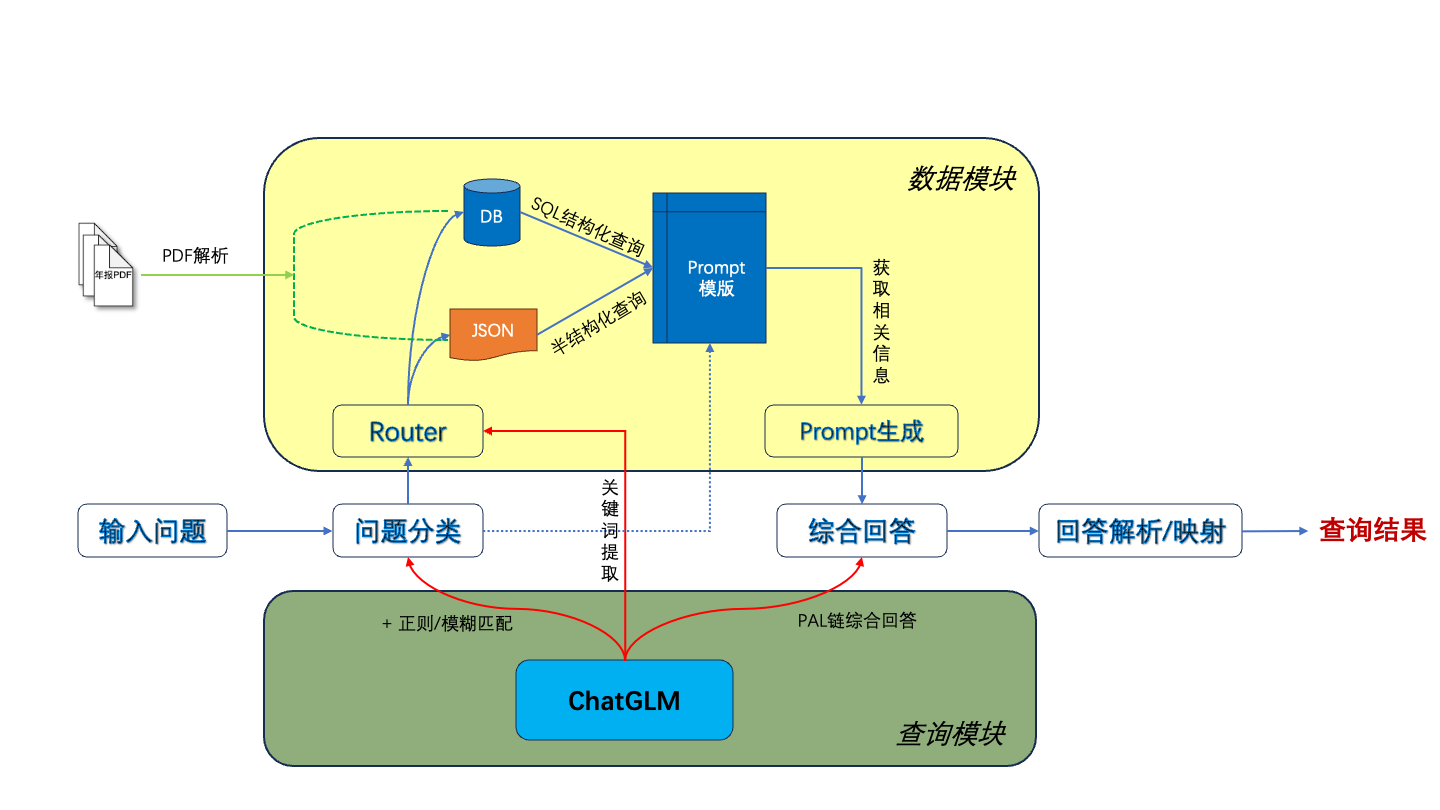
Aqui estão nossas etapas recomendadas:
1. Extração de texto e tabela de PDF: você pode usar kits de ferramentas como pdfplumber e pdfminer para extrair texto e dados de tabela de arquivos PDF.
2. Segmentação de dados: De acordo com o diretório, subdiretório e informações do capítulo do arquivo PDF, o conteúdo é segmentado com precisão.
3. Construir um banco de dados financeiro básico: Projete campos e formatos de bancos de dados financeiros profissionais com base em conhecimento financeiro e conteúdo PDF. Por exemplo, defina o balanço patrimonial, demonstração de fluxo de caixa, demonstração de resultados, etc.
4. Extração de informações: Use os recursos de extração de informações de grandes modelos e tecnologia de PNL para extrair informações correspondentes do campo financeiro. Por exemplo, use o modo JSON para gerar o conteúdo do diretório, com o nome do capítulo como chave e o número da página como valor. Ao mesmo tempo, extraia detalhadamente os dados da tabela e produza-os no formato JSON.
5. Construir um banco de dados de perguntas e respostas sobre conhecimento financeiro: Combinado com o banco de dados financeiro construído, aplique grandes modelos para construir um banco de dados básico de perguntas e respostas financeiras. Por exemplo,
{"question":"某公司2021年的财务费用为多少元?", "answer": "某公司2021年的财务费用为XXXX元。"}
prompt:用多种句式修改question及answer的内容。
{"question":"为什么财务费用可以是负的?", "answer": ""}
prompt:请模仿上面的question给出100个类似的问题与对应的答案,用json输出。
6. Construa uma biblioteca de vetores: Com a ajuda de tecnologias como Word2Vec e Text2Vec, vetores semânticos são extraídos de dados de texto originais. Use pgvector, uma extensão baseada em PostgreSQL, para armazenar e indexar esses vetores para construir uma biblioteca de vetores em grande escala que possa ser consultada com eficiência.
7. Aplicação: Combinado com bibliotecas de vetores, modelos grandes, langchain e outras ferramentas para melhorar os efeitos da aplicação.
No SMP 2023 ChatGLM Financial Large Model Challenge, conduzimos a rodada preliminar, semifinal A, semifinal B e semifinal C, respectivamente. Para essas rodadas de competição, anotamos manualmente os dados relevantes, com um total de 10.000 inscrições.
Exemplo de dados:
{ "ID" : 1 ,
"question" : "2019年中国工商银行财务费用是多少元?" ,
"answer" : "2019年中国工商银行财务费用是12345678.9元。" }
{ "ID" : 2 ,
"question" : "工商银行2019年营业外支出和营业外收入分别是多少元?" ,
"answer" : "工商银行2019年营业外支出为12345678.9元,营业外收入为2345678.9元。" }
{ "ID" : 3 ,
"question" : "中国工商银行2021年净利润增长率是多少?保留2位小数。" ,
"answer" : "中国工商银行2020年净利润为12345678.90元,2021年净利润为22345678.90元,根据公式,净利润增长率=(净利润-上年净利润)/上年净利润,得出结果中国工商银行2021年净利润增长率81.00%。" }Ao mesmo tempo, também escrevemos código de revisão para a competição. Contamos com:
Exemplo de avaliação:
{ "question" : "2019年中国工商银行财务费用是多少元?" ,
"prompt" : { "财务费用" : "12345678.9元" , "key_word" : "财务费用、2019" , "prom_answer" : "12345678.9元" },
"answer" : [
"2019年中国工商银行财务费用是12345678.9元。" ,
"2019年工商银行财务费用是12345678.9元。" ,
"中国工商银行2019年的财务费用是12345678.9元。" ]
}Exemplo de cálculo de avaliação:
Resposta 1: As despesas financeiras do ICBC em 2019 foram de 123.456.78,9 yuans.
frases mais semelhantes:
As despesas financeiras do ICBC em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,9915)
As despesas financeiras do Banco Industrial e Comercial da China em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,9820)
As despesas financeiras do Banco Industrial e Comercial da China em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,9720)
Avaliação: 0,25+0,25+0,9915*0,5=0,9958 pontos.
Explicação da pontuação: prom_answer está correto, contém todas as palavras-chave e tem a maior similaridade de 0,9915.
Resposta 2: As despesas financeiras do ICBC em 2019 são de 335.768,91 yuans.
Avaliação: 0 pontos.
Explicação da pontuação: Erros Prom_answer não são pontuados.
Resposta três: 12345678,9 yuans.
frases mais semelhantes:
As despesas financeiras do ICBC em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,6488)
As despesas financeiras do Banco Industrial e Comercial da China em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,6409)
As despesas financeiras do Banco Industrial e Comercial da China em 2019 foram de 1.234.5678,9 yuans. (Pontuação: 0,6191)
Avaliação: 0,25+0+0,6488*0,5=0,5744 pontos.
Explicação da pontuação: prom_answer está correto, não contém todas as palavras-chave e tem a maior similaridade de 0,6488.
{ "id" : 0 , "question" : "2021年其他流动资产第12高的是哪家上市公司?" , "answer" : "2021年其他流动资产第12高的公司是苏美达股份有限公司。" }
{ "id" : 1 , "question" : "注册地址在重庆的上市公司中,2021年营业收入大于5亿的有多少家?" , "answer" : "2021年注册在重庆,营业收入大于5亿的公司一共有4家。" }
{ "id" : 2 , "question" : "广东华特气体股份有限公司2021年的职工总人数为?" , "answer" : "2021年广东华特气体股份有限公司职工总人数是1044人。" }
{ "id" : 3 , "question" : "在保留两位小数的情况下,请计算出金钼股份2019年的流动负债比率" , "answer" : "2019金钼股份流动负债比率是61.10%。其中流动负债是1068418275.97元;总负债是1748627619.69元;" }
{ "id" : 4 , "question" : "2019年负债总金额最高的上市公司为?" , "answer" : "2019年负债合计最高的是上海汽车集团股份有限公司。" }
{ "id" : 5 , "question" : "2019年总资产最高的前五家上市公司是哪些家?" , "answer" : "2019年资产总计最高前五家是上海汽车集团股份有限公司、中远海运控股股份有限公司、国投电力控股股份有限公司、华域汽车系统股份有限公司、广州汽车集团股份有限公司。" }
{ "id" : 6 , "question" : "2020年营业收入最高的3家并且曾经在宁波注册的上市公司是?金额是?" , "answer" : "注册在宁波,2020年营业收入最高的3家是宁波均胜电子股份有限公司营业收入47889837616.15元;宁波建工股份有限公司营业收入19796854240.57元;宁波继峰汽车零部件股份有限公司营业收入15732749552.37元。" }
{ "id" : 7 , "question" : "注册地址在苏州的上市公司中,2020年利润总额大于5亿的有多少家?" , "answer" : "2020年注册在苏州,利润总额大于5亿的公司一共有2家。" }
{ "id" : 8 , "question" : "浙江运达风电股份有限公司在2019年的时候应收款项融资是多少元?" , "answer" : "2019年浙江运达风电股份有限公司应收款项融资是51086824.07元。" }
{ "id" : 9 , "question" : "神驰机电股份有限公司2020年的注册地址为?" , "answer" : "2020年神驰机电股份有限公司注册地址是重庆市北碚区童家溪镇同兴北路200号。" }
{ "id" : 10 , "question" : "2019年山东惠发食品股份有限公司营业外支出和营业外收入分别是多少元?" , "answer" : "2019年山东惠发食品股份有限公司营业外收入是1018122.97元;营业外支出是2513885.46元。" }
{ "id" : 11 , "question" : "福建广生堂药业股份有限公司2020年年报中提及的财务费用增长率具体是什么?" , "answer" : "2020福建广生堂药业股份有限公司财务费用增长率是34.33%。其中,财务费用是7766850.48元;上年财务费用是5781839.51元。" }
{ "id" : 12 , "question" : "华灿光电股份有限公司2021年的法定代表人与上年相比相同吗?" , "answer" : "不相同,华灿光电股份有限公司2020年法定代表人是俞信华,2021年法定代表人是郭瑾。" }
{ "id" : 13 , "question" : "请具体描述一下2020年仲景食品控股股东是否发生变更。" , "answer" : "2020年,仲景食品控股股东没有发生变更。" }
{ "id" : 14 , "question" : "什么是其他债权投资?" , "answer" : "其他债权投资是指企业或机构投资者通过购买债券、贷款、定期存款等金融产品获得的固定收益。这些金融产品通常由政府、公司或其他机构发行,具有一定的信用等级和风险。 n n其他债权投资是企业或机构投资组合中的一部分,通常用于稳定收益和分散风险。与股票投资相比,其他债权投资的风险较低,但收益也相对较低。 n n其他债权投资的管理和投资策略与其他资产类别类似,包括分散投资、风险控制、收益最大化等。然而,由于其他债权投资的种类繁多,其投资和管理也存在一定的特殊性。" }[PPT] [Vídeo][Documentação Técnica]
[PPT] [Vídeo][Documentação Técnica]
[PPT] [Vídeo][Documentação Técnica]
A seguir estão as equipes e indivíduos que contribuíram para este projeto:
O projeto de código aberto FinGLM é totalmente para fins de bem-estar público e todos os desenvolvedores são bem-vindos para se inscrever. É claro que conduziremos uma revisão rigorosa. Se estiver interessado, por favor preencha o formulário.
Os recursos relacionados a este projeto são apenas para pesquisa e comunicação, e geralmente não são recomendados para uso comercial. Se utilizados para fins comerciais, assuma os riscos legais por ele causados.
Quando se trata do uso comercial de modelos, certifique-se de seguir os protocolos dos modelos relevantes, como ChatGLM-6B.





