mengzi retrieval lm
1.0.0
Na Langboat Technology, nos concentramos em aprimorar modelos pré-treinados para torná-los mais leves e satisfazer as necessidades reais da indústria. Uma abordagem baseada em recuperação (como RETRO, REALM e RAG) é crucial para atingir esse objetivo.
Este repositório é uma implementação experimental do modelo de linguagem com recuperação aprimorada. Atualmente, ele suporta apenas ajuste de recuperação no GPT-Neo.
Bifurcamos Huggingface Transformers e lm-evaluation-harness para adicionar suporte de recuperação. A parte de indexação é implementada como um servidor HTTP para dissociar melhor a recuperação e o treinamento.
A maior parte da implementação do modelo é copiada de RETRO-pytorch e GPT-Neo. Usamos transformers-cli para adicionar um novo modelo chamado Re_gptForCausalLM baseado em GPT-Neo e, em seguida, adicionamos a parte de recuperação a ele.
Carregamos o modelo instalado em EleutherAI/gpt-neo-125M usando a biblioteca de recuperação 200G.
Você pode inicializar um modelo como este:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )E avalie o modelo assim:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Calculamos a similaridade usando a incorporação de sentença_transformers como representação de texto. Você pode inicializar um modelo Sentence-BERT assim:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )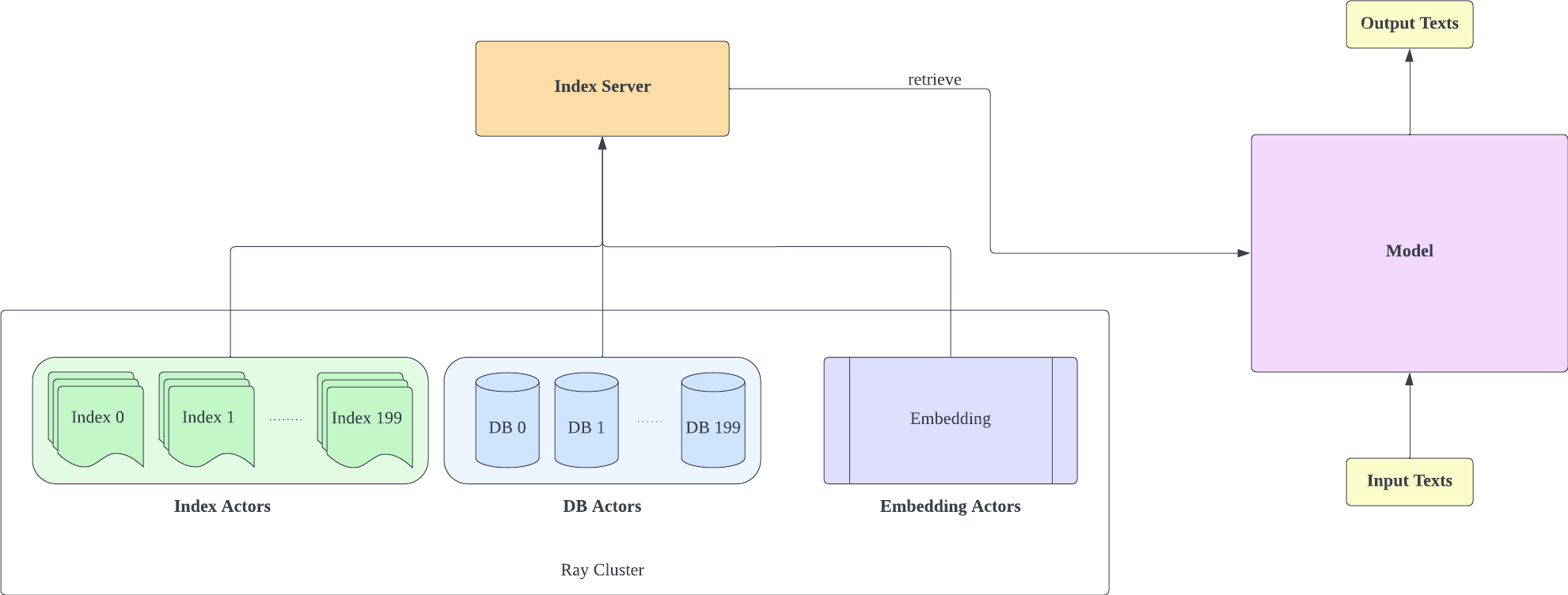
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " Usando IVF1024PQ48 como fábrica de índice faiss, carregamos o índice e o banco de dados no hub do modelo huggingface, que pode ser baixado usando o seguinte comando.
Em download_index_db.py, você pode especificar o número de índices e bancos de dados que deseja baixar.
python -u download_index_db.py --num 200Você pode baixar manualmente o modelo ajustado aqui: https://huggingface.co/Langboat/ReGPT-125M-200G
O servidor de indexação é baseado em FastAPI e Ray. Com o Ray's Actor, as tarefas computacionalmente intensivas são encapsuladas de forma assíncrona, permitindo-nos utilizar eficientemente os recursos de CPU e GPU com apenas uma instância de servidor FastAPI. Você pode inicializar um servidor de indexação assim:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Lembre-se de que a contagem de fragmentos da configuração IVF1024PQ48.json deve corresponder ao número de índices baixados. Você pode visualizar o número do índice baixado atualmente em db_path
- Esta configuração foi testada no A100-40G, portanto, se você tiver uma GPU diferente, recomendamos ajustá-la ao seu hardware.
- Após implantar o servidor de indexação, você precisa modificar o request_server em lm-evaluation-harness/config.json e train/config.json .
- Você pode reduzir o encoder_actor_count em config_IVF1024PQ48.json para reduzir os recursos de memória necessários.
· db_path:local de download do banco de dados do huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" é um exemplo.
Este comando baixará o banco de dados e os dados do índice do huggingface.
Altere a pasta de índice no arquivo de configuração (config IVF1024PQ48) para apontar para o caminho da pasta de índice e envie os instantâneos da pasta do banco de dados como o caminho do banco de dados para o script api.py.
Pare o servidor de indexação com o seguinte comando
ray stop
- Lembre-se de que você precisa manter o servidor de indexação habilitado durante o treinamento, avaliação e inferência
Use train/train.py para implementar o treinamento; train/config.json pode ser modificado para alterar os parâmetros de treinamento.
Você pode inicializar o treinamento assim:
cd train
python -u train.py
- Como o servidor de indexação precisa usar recursos de memória, é melhor implantar o servidor de indexação e modelar o treinamento em GPUs diferentes
Utilize train/inference.py como uma inferência para determinar a perda de um texto e sua perplexidade.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- Os test_data.json e train_data.json na pasta de dados são formatos de arquivo atualmente suportados. Você pode modificar seus dados para este formato.
Use lm-evaluation-harness como método de avaliação
Definimos o seq_len do chicote de avaliação lm como 1025 como a configuração inicial para comparação de modelos porque o seq_len do treinamento do nosso modelo é 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:o caminho do modelo adequado
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Os resultados da avaliação são os seguintes
| modelo | wikitexto palavra_perplexidade |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Langboat/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Langboat/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

