GraphGPT: Aprendizado de grafos com transformadores generativos pré-treinados
Este repositório é a implementação oficial de “GraphGPT: Graph Learning with Generative Pre-trained Transformers” em PyTorch.
GraphGPT: Aprendizado de grafos com transformadores generativos pré-treinados
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
Atualizar:
13/10/2024
- v0.4.0 lançada. Verifique
CHANGELOG.md para obter detalhes. - Alcançando SOTA em 3 conjuntos de dados OGB de grande escala:
- PCQM4M-v2 (sem 3D): 0,0802 (SOTA anterior 0,0821)
- ogbl-ppa: 68,76 (SOTA anterior 65,24)
- ogbl-citation2: 91,15 (SOTA anterior 90,72)
18/08/2024
- v0.3.1 lançada. Verifique
CHANGELOG.md para obter detalhes.
09/07/2024
- v0.3.0 lançada.
19/03/2024
- v0.2.0 lançada.
- Implemente
permute_nodes para conjunto de dados em estilo de mapa em nível de gráfico, a fim de aumentar as variações dos caminhos eulerianos e resultar em resultados melhores e robustos. - Adicione
StackedGSTTokenizer para que os tokens semânticos (ou seja, atributos de nó/borda) possam ser empilhados juntos com tokens estruturais e o comprimento da sequência seja bastante reduzido. - refatorar códigos.
23/01/2024
- v0.1.1, corrige bugs do pacote common-io.
01/03/2024
- Liberação inicial de códigos.
Direções Futuras
Lei de escala: qual é o limite de escala dos modelos GraphGPT?
- Como sabemos, o GPT treinado com dados de texto pode escalar centenas de bilhões de parâmetros e continuar melhorando sua capacidade.
- Os dados de texto podem fornecer trilhões de tokens, têm uma complexidade muito alta e possuem muito conhecimento, incluindo conhecimento social e natural.
- Em contraste, os dados gráficos sem atributos de nó/borda contêm apenas informações de estrutura, que são bastante limitadas em comparação com dados de texto. A maioria das informações ocultas (por exemplo, graus, contagem de subestruturas e etc.) por trás da estrutura podem ser calculadas exatamente usando pacotes como networkx. Portanto, as informações da estrutura do gráfico podem não ser capazes de suportar o dimensionamento do tamanho do modelo até bilhões de parâmetros.
- Nossos experimentos preliminares com vários conjuntos de dados gráficos em grande escala mostram que podemos dimensionar o GraphGPT em até mais de 400 milhões de parâmetros com melhoria de desempenho. Mas não podemos melhorar ainda mais os resultados. Pode ser devido aos nossos experimentos insuficientes. Mas é possível que as limitações inerentes aos dados gráficos tenham causado isso.
- Grandes conjuntos de dados gráficos (um gráfico grande ou grandes quantidades de gráficos pequenos) com atributos de nó/borda podem fornecer informações suficientes para treinarmos um grande modelo GraphGPT. Mesmo assim, um conjunto de dados gráficos pode não ser suficiente e podemos precisar coletar vários conjuntos de dados gráficos para treinar um GraphGPT.
- O problema aqui é como definir um tokenizer universal para atributos de borda/nó de vários conjuntos de dados gráficos.
Dados gráficos de alta qualidade: O que são dados gráficos de alta qualidade para treinar um GraphGPT para tarefas gerais?
- Por exemplo, se quisermos treinar um modelo para todos os tipos de tarefas de compreensão e geração de moléculas, que tipo de dados devemos usar?
- A partir de nossa investigação preliminar, adicionamos ZINC (4,6M) e CEPDB (2,3M) ao pré-treinamento, não observando ganhos ao ajustar o PCQM4M-v2 para a tarefa de previsão de lacuna homo-lumo. As possíveis razões podem ser as seguintes:
- #estrutura# Os padrões gráficos por trás do gráfico da molécula são relativamente simples.
- Padrões gráficos como cadeias ou anéis de 5/6 nós são muito comuns.
- Em média, 2 arestas por nó, o que significa que os átomos têm em média 2 ligações.
- #semântica# As regras químicas para a construção de pequenas moléculas orgânicas são simples: o átomo de carbono tem 4 ligações, o átomo de nitrogênio tem 3 ligações, o átomo de oxigênio tem 2 ligações e o átomo de hidrogênio tem 1 ligação, e assim por diante. Simplificando, desde que tenhamos as contagens de ligações dos átomos satisfeitas, podemos gerar qualquer molécula.
- As regras de estrutura e semântica são tão simples que até mesmo um modelo médio pode aprender com o conjunto de dados de tamanho médio. Portanto, adicionar dados extras não ajuda. Pré-treinamos modelos pequenos/médios/base/grandes usando dados de moléculas de 3,7 milhões, e suas perdas são muito próximas, indicando ganhos limitados com o aumento do tamanho dos modelos no estágio de pré-treinamento.
- Em segundo lugar, se quisermos treinar um modelo para qualquer tipo de tarefa de compreensão de estrutura gráfica, que tipo de dados devemos usar?
- Devemos usar dados gráficos verdadeiros de redes sociais, redes de citações e etc, ou apenas usar dados gráficos sintéticos, como gráficos aleatórios de Erdos-Renyi?
- Nossos experimentos preliminares mostram que o uso de gráficos aleatórios para pré-treinar o GraphGPT é útil para o modelo entender as estruturas dos gráficos, mas é instável. Suspeitamos que esteja relacionado às distribuições das estruturas gráficas nos estágios de pré-treinamento e ajuste fino. Por exemplo, se eles tiverem um número semelhante de arestas por nó, um número semelhante de nós, então o paradigma de pré-treinamento e ajuste fino funciona bem.
- #Universalidade# Então, como treinar um modelo GraphGPT para entender qualquer estrutura gráfica universalmente?
- Isso remonta a questões anteriores sobre a lei de escala: quais são os dados gráficos adequados e de alta qualidade para continuar ampliando o GraphGPT para que ele possa executar bem várias tarefas gráficas?
Poucos disparos: o GraphGPT pode obter capacidade de poucos disparos?
- Se possível, como projetar os dados de treinamento para permitir que o GraphGPT os aprenda?
- A partir de nossos experimentos preliminares com o conjunto de dados PCQM4M-v2, nenhuma capacidade de aprendizado é observada! Mas isso não significa que não possa. Pode ser pelos seguintes motivos:
- O modelo não é grande o suficiente. Usamos o modelo básico com parâmetros de aproximadamente 100 milhões.
- Os dados de treinamento não são suficientes. Usamos apenas 3,7 milhões de moléculas, o que fornece apenas tokens limitados para treinamento.
- O formato dos dados de treinamento não é adequado para que o modelo ganhe capacidade de poucos disparos.
Visão geral:

Propomos o GraphGPT, um novo modelo para aprendizagem de grafos por transformadores eulerianos de grafos generativos de pré-treinamento auto-supervisionados (GET). Primeiro apresentamos GET, que consiste em um backbone codificador/decodificador de transformador vanilla e uma transformação que transforma cada gráfico ou subgrafo amostrado em uma sequência de tokens representando o nó, a aresta e os atributos de forma reversível usando o caminho euleriano. Em seguida, pré-treinamos o GET com a tarefa de previsão do próximo token (NTP) ou com a tarefa agendada de previsão de token mascarado (SMTP). Por último, ajustamos o modelo com as tarefas supervisionadas. Este modelo intuitivo, porém eficaz, alcança resultados superiores ou próximos aos métodos de última geração para tarefas em nível de gráfico, borda e nó no conjunto de dados moleculares de grande escala PCQM4Mv2, o conjunto de dados de associação proteína-proteína ogbl-ppa , conjunto de dados da rede de citações ogbl-citation2 e o conjunto de dados ogbn-proteins do Open Graph Benchmark (OGB). Além disso, o pré-treinamento generativo nos permite treinar GraphGPT em até 2B+ parâmetros com desempenho consistentemente crescente, o que está além da capacidade dos GNNs e dos transformadores gráficos anteriores.
Gráfico para sequências
Depois de converter gráficos eulerizados em sequências, existem várias maneiras diferentes de anexar atributos de nós e arestas às sequências. Chamamos esses métodos de short , long e prolonged .
Dado o gráfico, nós o eulerizamos primeiro e depois o transformamos em uma sequência equivalente. E então, reindexamos os nós ciclicamente.
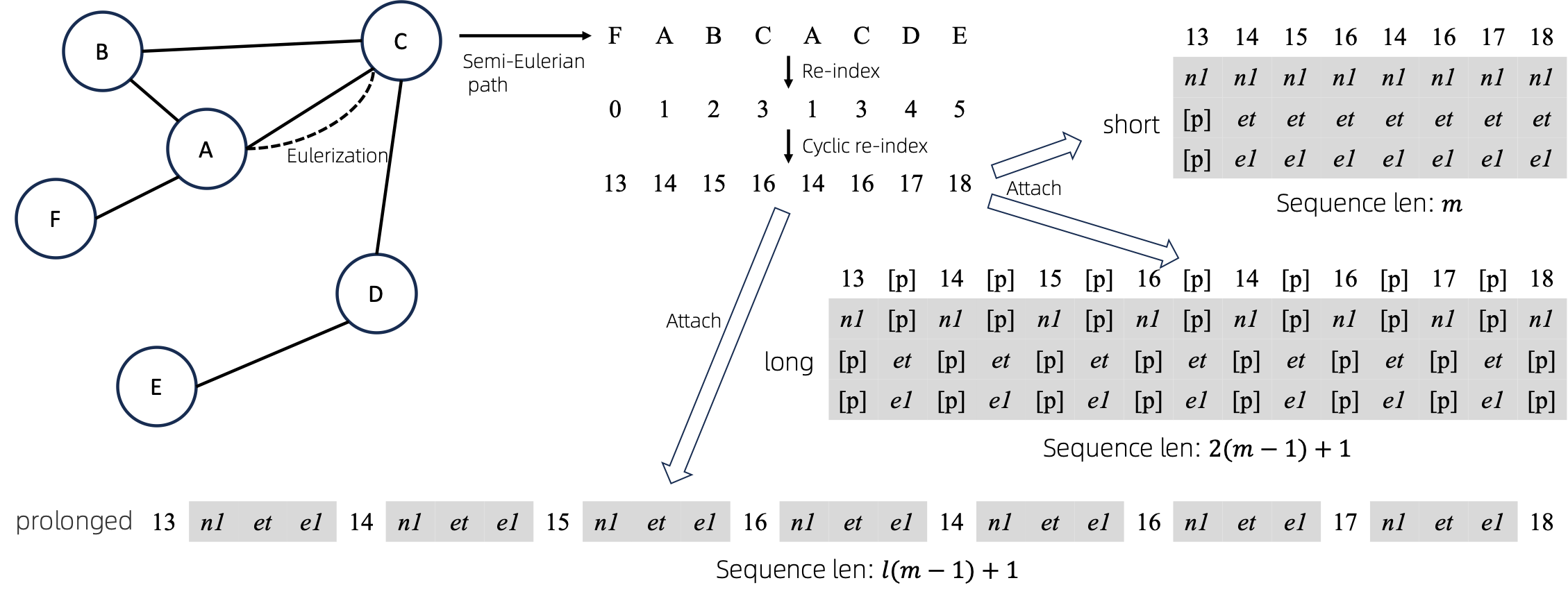
Suponha que o gráfico tenha atributos de um nó e atributos de uma borda e, em seguida, os métodos short , long e prolong são mostrados acima.
Nas figuras acima, n1 , n2 e e1 representam os tokens dos atributos do nó e da borda, e [p] representa o token de preenchimento.
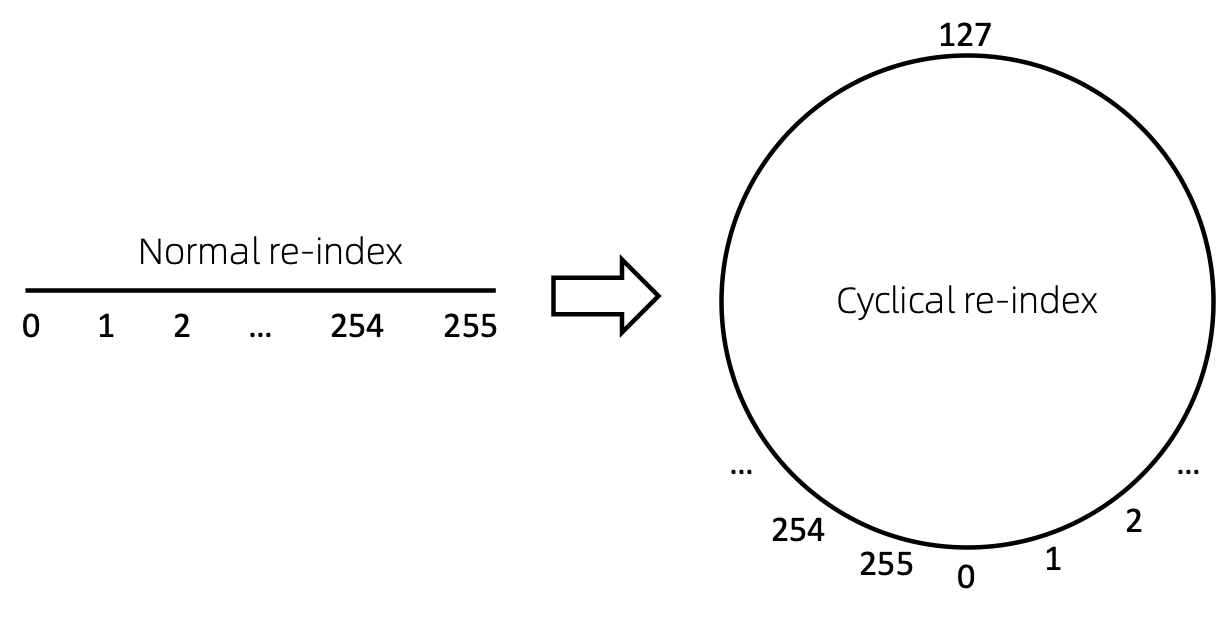
Reindexação de nó cíclico
Uma maneira direta de reindexar a sequência de nós é começar com 0 e adicionar 1 de forma incremental. Dessa forma, os tokens de índices pequenos serão suficientemente treinados, e os índices grandes não. Para superar isso, propomos cyclical re-index , que começa com um número aleatório no intervalo determinado, digamos [0, 255] e incrementa em 1. Depois de atingir o limite, por exemplo, 255 , o próximo índice do nó será 0 .
Resultados
Desatualizado. A ser atualizado em breve.
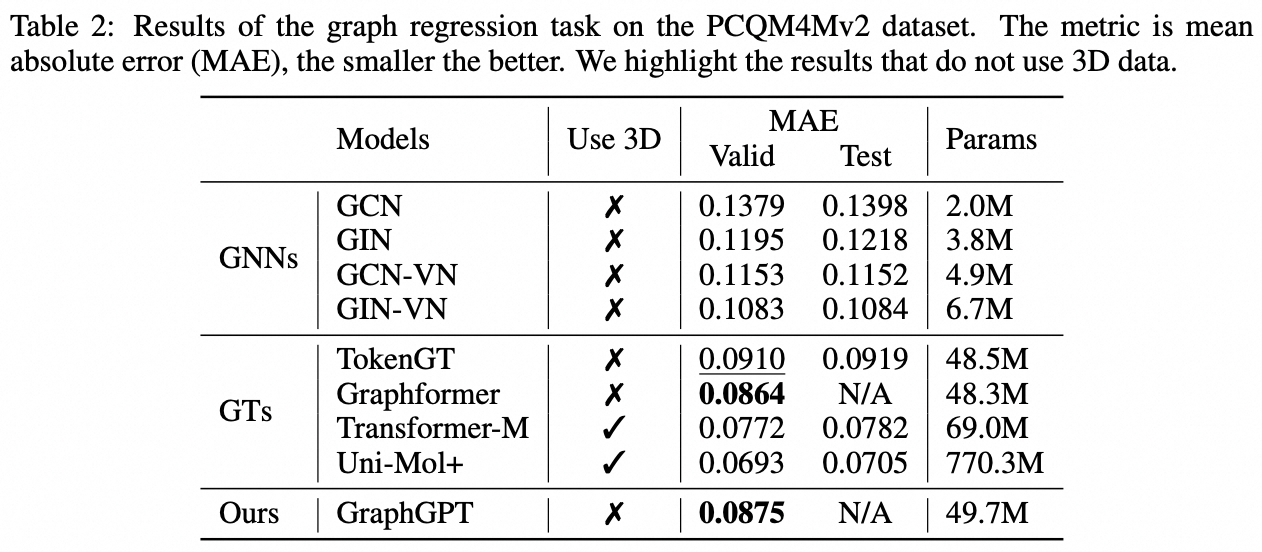
Tarefa em nível de gráfico: conjunto de dados PCQM4M-v2
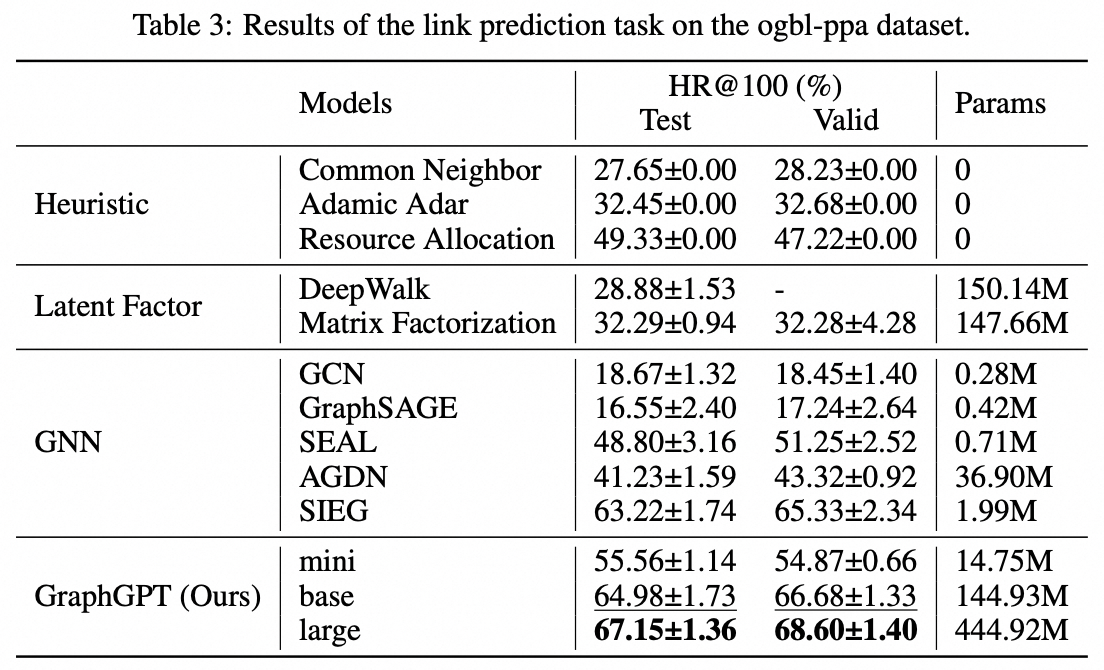
Tarefa de nível de borda: conjunto de dados ogbl-ppa
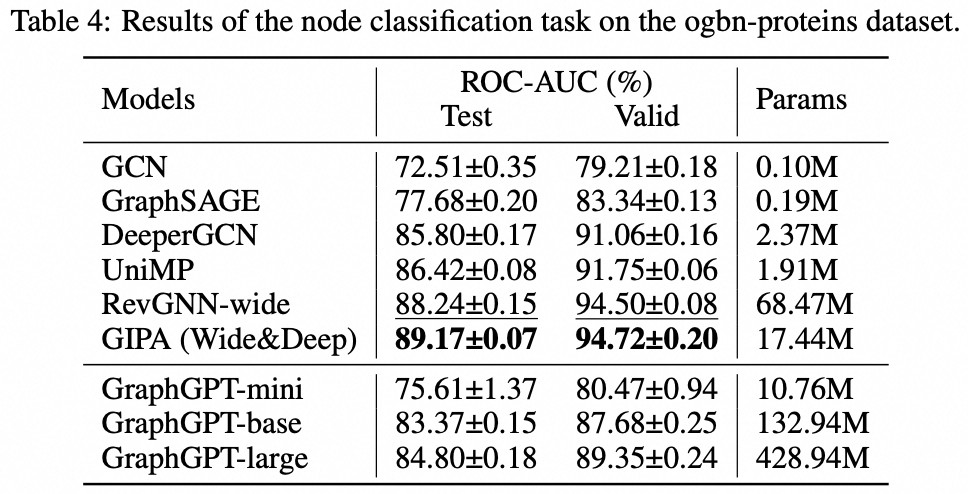
Tarefa em nível de nó: conjunto de dados ogbn-proteins
Instalação
git clone https://github.com/alibaba/graph-gpt.git
- Instale as dependências em requisitos.txt (usando Anaconda, testado com py38, pytorch-1131 e CUDA-11.7, 11.8 e 12.1 em GPU V100 e A100)
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Conjuntos de dados
Os conjuntos de dados são baixados usando o pacote python ogb.
Ao executar scripts em ./examples , o conjunto de dados será baixado automaticamente.
No entanto, o conjunto de dados PCQM4M-v2 é enorme e o download e o pré-processamento podem ser problemáticos. Sugerimos cd ./src/utils/ e python dataset_utils.py para baixar e pré-processar o conjunto de dados separadamente.
Correr
- Pré-treinar: modifique os parâmetros em
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , por exemplo, dataset_name , model_name , batch_size , workerCount e etc, e então execute ./examples/graph_lvl/pcqm4m_v2_pretrain.sh para pré-treinar o modelo com o PCQM4M-v2 conjunto de dados.- Para executar o exemplo de brinquedo, execute
./examples/toy_examples/reddit_pretrain.sh diretamente.
- Ajuste fino: modifique os parâmetros em
./examples/graph_lvl/pcqm4m_v2_supervised.sh , por exemplo, dataset_name , model_name , batch_size , workerCount , pretrain_cpt e etc, e então execute ./examples/graph_lvl/pcqm4m_v2_supervised.sh para ajustar com tarefas downstream .- Para executar o exemplo de brinquedo, execute
./examples/toy_examples/reddit_supervised.sh diretamente.
Norma de Código
Pré-comprometer
- Verifique o site oficial para obter detalhes
-
.pre-commit-config.yaml : crie o arquivo com o seguinte conteúdo para python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : instale o pré-commit em seus ganchos git.- pre-commit agora será executado em cada commit.
- Cada vez que você clona um projeto usando pré-commit, executar
pre-commit install deve ser sempre a primeira coisa a fazer.
-
pre-commit run --all-files : executa todos os ganchos de pré-commit em um repositório -
pre-commit autoupdate : atualize seus ganchos para a versão mais recente automaticamente -
git commit -n : verificações de pré-commit podem ser desabilitadas para um commit específico com o comando
Citação
Se você achar este trabalho útil, por favor, cite os seguintes artigos:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Contato
Qifang Zhao ([email protected])
Agradecemos sinceramente suas sugestões sobre nosso trabalho!
Licença
Lançado sob a licença MIT (ver LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


