CDial GPT
1.0.0
Este projeto fornece um conjunto de dados de conversação em chinês em grande escala e um modelo de pré-treinamento de conversação em chinês (modelo GPT chinês) neste conjunto de dados.
O código deste projeto é modificado do TransferTransfo e usa a versão HuggingFace Pytorch da biblioteca Transformers, que pode ser usada para pré-treinamento e ajuste fino.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" O conjunto de dados LCCC (Conversação Chinesa Limpa em Grande Escala) que fornecemos consiste principalmente em duas partes: LCCC-base (Baidu Netdisk, Google Drive) e LCCC-large (Baidu Netdisk, Google Drive. Projetamos um processo rigoroso de filtragem de dados para). garantir a qualidade dos dados de conversação neste conjunto de dados. Este processo de filtragem de dados inclui uma série de regras manuais e diversos classificadores baseados em algoritmos de aprendizado de máquina. O ruído que filtramos inclui: palavrões, caracteres especiais, expressões faciais, frases gramaticais, diálogos irrelevantes, etc.
As estatísticas deste conjunto de dados são mostradas na tabela abaixo. Entre eles, chamamos o diálogo que contém apenas duas frases de "diálogo de turno único" e chamamos o diálogo que contém mais de duas frases de "diálogo de vários turnos". Use a segmentação de palavras Jieba ao contar o tamanho da lista de palavras.
| Base LCCC (Disco de nuvem Baidu, Google Drive) | conversa de uma volta | Múltiplas rodadas de diálogo |
|---|---|---|
| o diálogo total gira | 3.354.232 | 3.466.274 |
| Total de frases de diálogo | 6.708.464 | 13.365.256 |
| Total de caracteres | 68.559.367 | 163.690.569 |
| Tamanho do vocabulário | 372.063 | 666.931 |
| Número médio de palavras em frases de conversação | 6,79 | 8.32 |
| Número médio de frases por rodada de conversa | 2 | 3,86 |
Observe que o processo de limpeza do conjunto de dados da base LCCC é mais rigoroso do que o do LCCC grande, portanto seu tamanho também é menor.
| LCCC-grande (Disco de nuvem Baidu, Google Drive) | conversa de uma volta | Múltiplas rodadas de diálogo |
|---|---|---|
| o diálogo total gira | 7.273.804 | 4.733.955 |
| Total de frases de diálogo | 14.547.608 | 18.341.167 |
| Total de caracteres | 162.301.556 | 217.776.649 |
| Tamanho do vocabulário | 662.514 | 690.027 |
| Número de palavras de avaliação para frases coloquiais | 7h45 | 8.14 |
| Número médio de frases por rodada de conversa | 2 | 3,87 |
Os dados de conversa originais no conjunto de dados de base LCCC vêm de conversas do Weibo, e os dados de conversa originais no conjunto de dados grande do LCCC são integrados a outros conjuntos de dados de conversa de código aberto baseados nessas conversas do Weibo:
| Conjunto de dados | o diálogo total gira | Exemplo de conversa |
|---|---|---|
| Corpo do Weibo | 79 milhões | P: Comi hot pot sete ou oito vezes em Chengdu, Chongqing. R: Hahahaha! Então minha boca pode apodrecer! |
| Corpus de fofoca PTT | 0,4 milhão | P: Por que os moradores sempre intimidam os alunos do ensino médio. QQ Resposta: Se você acha que se escolher uma boa matéria, você se tornará Bill Gates, então é melhor abandonar a escola. |
| Corpus de legendas | 2,74 milhões | P: As pessoas na ópera de Pequim não são livres. R: Eles colocam as pessoas em jaulas. |
| Corpus Xiaohuangji | 0,45 milhões | P: Você já se apaixonou? A: Você já se apaixonou Ah, não fale nisso, estou triste... |
| Tieba Corpus | 2,32 milhões | P: Na primeira fila, todos os torcedores do Lu estão se levantando, certo? R: O título diz assistências, mas depois de assistir aquela bola é realmente uma ironia viva. |
| Corpo Qingyun | 0,1 milhão | P: Parece que você ama muito o dinheiro. A: Ah, é mesmo? Então você está quase lá |
| Corpus de conversação de Douban | 0,5 milhão | P: Aprenda inglês puro assistindo filmes originais em inglês R: Adoro Friends e já assisti muitas vezes P: Estou quase exausto assistindo o mesmo CD R: Então seu inglês deve estar muito bom agora |
| Corpus de Conversação E-comercial | 0,5 milhão | P: Será um bom negócio? R: Ainda não. P: Estará disponível no futuro. R: Não tenho certeza. |
| Corpus de bate-papo chinês | 0,5 milhão | P: Minhas pernas estão inúteis hoje. Vocês estão comemorando o feriado, então vou mover tijolos. R: É um trabalho árduo, até ganhei muito dinheiro no Natal. Sou uma pessoa sem namorado. É o mesmo para qualquer feriado. |
Também fornecemos uma série de modelos de pré-treinamento chineses (modelos GPT chineses). O processo de pré-treinamento desses modelos é dividido em duas etapas, primeiro o pré-treinamento em dados novos chineses e, em seguida, o pré-treinamento nos dados LCCC. definir.
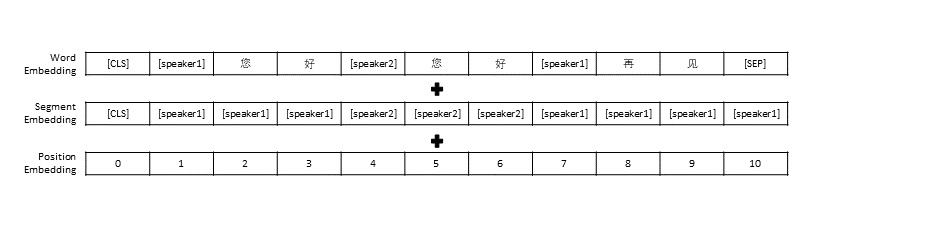
Seguimos as configurações de pré-processamento de dados no TransferTransfo, que reuniu todo o histórico da conversa em uma frase, e então usamos essa frase como entrada do modelo para prever a resposta da conversa. Além da representação vetorial de cada palavra, a entrada do nosso modelo também inclui a representação vetorial do locutor e a representação vetorial de posição.
| Modelo pré-treinado | Número de parâmetros | Dados usados para pré-treinamento | descrever |
|---|---|---|---|
| Romance GPT | 95,5 milhões | Dados do romance chinês | Modelo GPT chinês pré-treinado construído com base em novos dados chineses (os novos dados incluem um total de 1,3 bilhão de palavras) |
| Base CDial-GPT LCCC | 95,5 milhões | Base LCCC | Baseado no romance GPT, use o modelo GPT pré-treinado chinês treinado pela base LCCC |
| Base CDial-GPT2 LCCC | 95,5 milhões | Base LCCC | Baseado no GPT Novel , use o modelo chinês pré-treinado GPT2 treinado com base LCCC |
| CDial-GPT LCCC-grande | 95,5 milhões | LCCC-grande | Baseado no romance GPT, use o modelo GPT pré-treinado chinês treinado por LCCC-large |
Instale diretamente da fonte:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Etapa 1: Prepare o conjunto de dados necessário para o modelo de pré-treinamento e ajuste fino (como conjunto de dados STC ou dados de brinquedo "data/toy_data.json" no diretório do projeto. Observe que se os dados contiverem inglês, eles deverão ser separados por letras, como: olá)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Você pode usar os seguintes links para baixar o conjunto de treinamento e o conjunto de verificação do STC (Baidu Cloud Disk, Google Drive)
Etapa 2: treinar o modelo
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
ou
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
O parâmetro train_path também é fornecido em nosso script de treinamento, que permite aos usuários ler arquivos de texto simples em fatias. Se você estiver usando um sistema com memória limitada, considere usar este parâmetro para ler dados de treinamento. Se você usar train_path você precisa deixar data_path vazio.
Etapa 3: gerar texto
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: Você pode usar o seguinte link para baixar o conjunto de testes STC (Baidu Cloud Disk, Google Drive)
Parâmetros do script de treinamento
| parâmetro | tipo | valor padrão | descrever |
|---|---|---|---|
| modelo_ponto de verificação | str | "" | Caminho ou URL dos arquivos de modelo (diretório do modelo de pré-treinamento e arquivos de configuração/vocab) |
| pré-treinado | bool | Falso | Se for falso, treine o modelo do zero |
| caminho_dados | str | "" | Caminho do conjunto de dados |
| conjunto de dados_cache | str | padrão = "dataset_cache" | Caminho ou URL do cache do conjunto de dados |
| caminho_do_trem | str | "" | Caminho do conjunto de treinamento para conjunto de dados distribuído |
| caminho_válido | str | "" | Caminho do conjunto de validação para conjunto de dados distribuído |
| arquivo_de_log | str | "" | Logs de saída para um arquivo neste caminho |
| num_trabalhadores | interno | 1 | Número de subprocessos para carregamento de dados |
| n_épocas | interno | 70 | Número de épocas de treinamento |
| train_batch_size | interno | 8 | Tamanho do lote para treinamento |
| tamanho_de_lote_válido | interno | 8 | Tamanho do lote para validação |
| max_history | interno | 15 | Número de trocas anteriores para manter no histórico |
| agendador | str | "noam" | Método de otimizador |
| n_emd | interno | 768 | Número de n_emd no arquivo de configuração (para noam) |
| eval_before_start | bool | Falso | Se for verdade, inicie a avaliação antes do treino |
| passos_de_aquecimento | interno | 5.000 | Etapas de aquecimento |
| etapas_válidas | interno | 0 | Execute a validação a cada X etapas, se não for 0 |
| gradiente_acumulação_passos | interno | 64 | Acumule gradientes em várias etapas |
| norma_max | flutuador | 1,0 | Norma de gradiente de recorte |
| dispositivo | str | "cuda" se torch.cuda.is_available() senão "cpu" | Dispositivo (cuda ou CPU) |
| fp16 | str | "" | Defina como O0, O1, O2 ou O3 para treinamento fp16 (consulte a documentação do apex) |
| classificação_local | interno | -1 | Classificação local para treinamento distribuído (-1: não distribuído) |
Avaliamos o modelo de pré-treinamento de diálogo ajustado usando o conjunto de dados STC (conjunto de treinamento/conjunto de validação (Baidu Netdisk, Google Drive), conjunto de teste (Baidu Netdisk, Google Drive)). Todas as respostas foram amostradas por amostragem de núcleo (p=0,9, temperatura=0,7).
| Modelo | Tamanho do modelo | PPL | AZUL-2 | AZUL-4 | Dist-1 | Dist-2 | Correspondência gananciosa | Média de incorporação |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73 milhões | 34h20 | 3,93 | 0,90 | 8,5 | 11.91 | 65,84 | 83,38 |
| Transformador | 113 milhões | 22h10 | 6,72 | 3.14 | 8.8 | 13,97 | 66.06 | 83,55 |
| Bate-papo GPT2 | 88 milhões | - | 2.28 | 0,54 | 10.3 | 16h25 | 61,54 | 78,94 |
| Romance GPT | 95,5 milhões | 21h27 | 5,96 | 2,71 | 8,0 | 11,72 | 66,12 | 83,34 |
| Base GPT LCCC | 95,5 milhões | 18h38 | 6,48 | 3.08 | 8.3 | 12,68 | 66,21 | 83,54 |
| Base GPT2 LCCC | 95,5 milhões | 22,76 | 5,69 | 2,50 | 7.7 | 10,87 | 66,24 | 83,46 |
| GPT LCCC-grande | 95,5 milhões | 18h23 | 6,63 | 3.20 | 8.3 | 12,71 | 66,25 | 83,63 |
Amostramos 200 respostas para cada modelo e convidamos 3 anotadores na plataforma de terceirização para avaliar manualmente essas respostas. As dimensões de avaliação foram fluência conversacional, relevância contextual e diversidade de respostas. O intervalo de pontuação para cada dimensão é 2/1/0. Consulte nosso artigo para obter mais detalhes.
| Modelo | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformador | 42,4% | 23,6% | 34,0% | 0,4429 |
| Bate-papo GPT2 | 24,3% | 19,1% | 56,6% | 0,3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-grande | 48,6% | 24,5% | 27,0% | 0,4203 |
Amostramos aleatoriamente 1.000 respostas de conversas e contamos as respostas ruins entre estas respostas:
| Contém declarações repetidas | Contém palavrões | Outras respostas ruins |
|---|---|---|
| vinte e três | 9 | 2 |
Ajustamos os parâmetros do modelo GPT LCCC grande no conjunto de dados STC e usamos esse modelo ajustado para gerar o seguinte exemplo de conversa:
| Publicar | Resposta |
|---|---|
| Na verdade, estamos em Pequim, não em Harbin. | O clima em Harbin parece ser melhor do que em Pequim. Chove levemente aqui e há ventos fortes durante o dia. |
| A competição de publicidade no campus da operadora foi muito divertida! Hahaha. | Achei que fosse o anúncio de Jack Ma. |
| Vestido de noiva da série Delsa S posa candy color, rosa, azul, vermelho e roxo, lúdico e fresco, você gostou? | A última é tão linda, tão linda! |
Também usamos o modelo ajustado acima para obter os seguintes resultados de interação:
| Roel | Resposta |
|---|---|
| Usuário | Não me ame sem sucesso |
| Robô | O amor infrutífero é tão doloroso. |
| Usuário | Mas está tudo bem se você amou |
| Robô | Às vezes, o amor é um jogo. |
| Usuário | Eu sempre perco |
| Robô | Eu te amo tanto quanto eu te amo. |
| Usuário | Você pode puxá-lo? |
| Robô | Você pode puxá-lo. |
| Usuário | Não me imite |
| Robô | O que estou dizendo é que você não pode fazer isso. |
| Usuário | Você me força a fazer isso, certo? |
| Robô | Não, estou forçando você a falar, certo? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
O conjunto de dados LCCC e o modelo de diálogo pré-treinado fornecidos por este projeto são apenas para fins de pesquisa científica. As conversas no conjunto de dados LCCC são coletadas de diferentes fontes. Embora tenhamos desenvolvido um processo rigoroso de limpeza de dados, não garantimos que todo o conteúdo impróprio tenha sido filtrado. Todo o conteúdo e opiniões contidas nestes dados são independentes dos autores deste projeto. O modelo e o código fornecidos neste projeto são apenas um componente do sistema de diálogo completo. Os scripts de decodificação que fornecemos são apenas para fins de pesquisa científica. Todo o conteúdo do diálogo gerado usando os modelos e scripts neste projeto não tem nada a ver com o autor. este projeto.
Se você achar nosso projeto útil, cite nosso artigo:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
Este projeto fornece um conjunto de dados de conversação em chinês limpo em grande escala e um modelo GPT chinês pré-treinado neste conjunto de dados.
Nosso código usado para o pré-treinamento é adaptado do modelo TransferTransfo baseado na biblioteca Transformers. Os códigos usados para o pré-treinamento e o ajuste fino são fornecidos neste repositório.
Apresentamos um corpus de conversação chinesa limpa em grande escala (LCCC) contendo: LCCC-base (Baidu Netdisk, Google Drive) e LCCC-large (Baidu Netdisk, Google Drive). Um rigoroso pipeline de limpeza de dados é projetado para garantir a qualidade do. Este pipeline envolve um conjunto de regras e vários filtros baseados em classificadores, como palavras ofensivas ou sensíveis, símbolos especiais, emojis, frases gramaticalmente incorretas e conversas incoerentes. filtrado.
A estatística do nosso corpus é apresentada a seguir. Os diálogos com apenas dois enunciados são considerados como "turno único", e os diálogos com mais de três enunciados são considerados como "multiturno". Jieba é usado para transformar cada expressão em palavras.
| Base LCCC (Baidu Netdisk, Google Drive) | Volta única | Multivoltas |
|---|---|---|
| Sessões | 3.354.382 | 3.466.607 |
| Declarações | 6.708.554 | 13.365.268 |
| Personagens | 68.559.727 | 163.690.614 |
| Vocabulário | 372.063 | 666.931 |
| Média de palavras por enunciado | 6,79 | 8.32 |
| Média de declarações por sessão | 2 | 3,86 |
Observe que a base do LCCC é limpa usando regras mais rígidas em comparação com o LCCC grande.
| LCCC-grande (Baidu Netdisk, Google Drive) | Volta única | Multivoltas |
|---|---|---|
| Sessões | 7.273.804 | 4.733.955 |
| Declarações | 14.547.608 | 18.341.167 |
| Personagens | 162.301.556 | 217.776.649 |
| Vocabulário | 662.514 | 690.027 |
| Média de palavras por enunciado | 7h45 | 8.14 |
| Média de declarações por sessão | 2 | 3,87 |
Os diálogos brutos para a base LCCC se originam de um Weibo Corpus que rastreamos do Weibo, e os diálogos brutos para o LCCC-grande são construídos combinando vários conjuntos de dados de conversação além do Weibo Corpus:
| Conjunto de dados | Sessões | Amostra |
|---|---|---|
| Corpo do Weibo | 79 milhões | P: Comi hot pot sete ou oito vezes em Chengdu, Chongqing. R: Hahahaha! Então minha boca pode apodrecer! |
| Corpus de fofoca PTT | 0,4 milhão | P: Por que os moradores sempre intimidam os alunos do ensino médio. QQ Resposta: Se você acha que se escolher uma boa matéria, você se tornará Bill Gates, então é melhor abandonar a escola. |
| Corpus de legendas | 2,74 milhões | P: As pessoas na ópera de Pequim não são livres. R: Eles colocam as pessoas em jaulas. |
| Corpus Xiaohuangji | 0,45 milhões | P: Você já se apaixonou? A: Você já se apaixonou Ah, não fale nisso, estou triste... |
| Tieba Corpus | 2,32 milhões | P: Na primeira fila, todos os torcedores do Lu estão se levantando, certo? R: O título diz assistências, mas depois de assistir aquela bola é realmente uma ironia viva. |
| Corpo Qingyun | 0,1 milhão | P: Parece que você ama muito o dinheiro. A: Ah, é mesmo? Então você está quase lá |
| Corpus de conversação de Douban | 0,5 milhão | P: Aprenda inglês puro assistindo filmes originais em inglês R: Adoro Friends e já assisti muitas vezes P: Estou quase exausto assistindo o mesmo CD R: Então seu inglês deve estar muito bom agora |
| Corpus de Conversação E-comercial | 0,5 milhão | P: Será um bom negócio? R: Ainda não. P: Estará disponível no futuro. R: Não tenho certeza. |
| Corpus de bate-papo chinês | 0,5 milhão | P: Minhas pernas estão inúteis hoje. Vocês estão comemorando o feriado, então vou mover tijolos. R: É um trabalho árduo, até ganhei muito dinheiro no Natal. Sou uma pessoa sem namorado. É o mesmo para qualquer feriado. |
Também apresentamos uma série de modelos GPT chineses que são primeiro pré-treinados em um novo conjunto de dados chinês e depois pós-treinados em nosso conjunto de dados LCCC.
Semelhante ao TransferTransfo, concatenamos todos os históricos de diálogo em uma frase de contexto e usamos essa frase para prever a resposta. A entrada do nosso modelo consiste na incorporação de palavras, incorporação de locutor e incorporação posicional de cada palavra.
| Modelos | Tamanho do parâmetro | Conjunto de dados pré-treinamento | Descrição |
|---|---|---|---|
| Romance GPT | 95,5 milhões | Romance Chinês | Um modelo GPT pré-treinado no conjunto de dados do romance chinês (1,3 bilhão de palavras, observe que não fornecemos detalhes deste modelo) |
| Base CDial-GPT LCCC | 95,5 milhões | Base LCCC | Um modelo GPT pós-treinado no conjunto de dados baseado em LCCC do GPT Novel |
| Base CDial-GPT2 LCCC | 95,5 milhões | Base LCCC | Um modelo GPT2 pós-treinado no conjunto de dados baseado em LCCC do GPT Novel |
| CDial-GPT LCCC-grande | 95,5 milhões | LCCC-grande | Um modelo GPT pós-treinado em um grande conjunto de dados LCCC do GPT Novel |
Instale a partir dos códigos-fonte:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Etapa 1: Prepare os dados para ajuste fino (por exemplo, conjunto de dados STC ou "data/toy_data.json" em nosso repositório) e o modelo pré-testado:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Você pode baixar o trem e a divisão válida do STC nos seguintes links: (Baidu Netdisk, Google Drive)
Etapa 2: treinar o modelo
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
ou
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Nota: Também fornecemos o argumento train_path no script de treinamento para ler o conjunto de dados em texto simples, que será dividido e tratado de forma distribuída. Você pode considerar usar este argumento se o conjunto de dados for muito grande para a memória do seu sistema (também,). lembre-se de deixar o argumento data_path vazio se estiver usando train_path ).
Etapa 3: modo de inferência
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: Você pode baixar a divisão de teste do STC nos seguintes links: (Baidu Netdisk, Google Drive)
Argumentos de treinamento
| Argumentos | Tipo | Valor padrão | Descrição |
|---|---|---|---|
| modelo_ponto de verificação | str | "" | Caminho ou URL dos arquivos de modelo (diretório do modelo de pré-treinamento e arquivos de configuração/vocab) |
| pré-treinado | bool | Falso | Se for falso, treine o modelo do zero |
| caminho_dados | str | "" | Caminho do conjunto de dados |
| conjunto de dados_cache | str | padrão = "dataset_cache" | Caminho ou URL do cache do conjunto de dados |
| caminho_do_trem | str | "" | Caminho do conjunto de treinamento para conjunto de dados distribuído |
| caminho_válido | str | "" | Caminho do conjunto de validação para conjunto de dados distribuído |
| arquivo_de_log | str | "" | Logs de saída para um arquivo neste caminho |
| num_trabalhadores | interno | 1 | Número de subprocessos para carregamento de dados |
| n_épocas | interno | 70 | Número de épocas de treinamento |
| train_batch_size | interno | 8 | Tamanho do lote para treinamento |
| tamanho_de_lote_válido | interno | 8 | Tamanho do lote para validação |
| max_history | interno | 15 | Número de trocas anteriores para manter no histórico |
| agendador | str | "noam" | Método de otimizador |
| n_emd | interno | 768 | Número de n_emd no arquivo de configuração (para noam) |
| eval_before_start | bool | Falso | Se for verdade, inicie a avaliação antes do treino |
| etapas_de_aquecimento | interno | 5.000 | Etapas de aquecimento |
| etapas_válidas | interno | 0 | Execute a validação a cada X etapas, se não for 0 |
| gradiente_acumulação_passos | interno | 64 | Acumule gradientes em várias etapas |
| norma_max | flutuador | 1,0 | Norma de gradiente de recorte |
| dispositivo | str | "cuda" se torch.cuda.is_available() senão "cpu" | Dispositivo (cuda ou CPU) |
| fp16 | str | "" | Defina como O0, O1, O2 ou O3 para treinamento fp16 (consulte a documentação do apex) |
| classificação_local | interno | -1 | Classificação local para treinamento distribuído (-1: não distribuído) |
A avaliação é realizada em resultados gerados por modelos ajustados em
Conjunto de dados STC (divisão de treinamento/válido (Baidu Netdisk, Google Drive), divisão de teste (Baidu Netdisk, Google Drive)). Todas as respostas são geradas usando o esquema de amostragem de núcleo com um limite de 0,9 e temperatura de 0,7.
| Modelos | Tamanho do modelo | PPL | AZUL-2 | AZUL-4 | Dist-1 | Dist-2 | Correspondência gananciosa | Média de incorporação |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73 milhões | 34h20 | 3,93 | 0,90 | 8,5 | 11.91 | 65,84 | 83,38 |
| Transformador | 113 milhões | 22h10 | 6,72 | 3.14 | 8.8 | 13,97 | 66.06 | 83,55 |
| Bate-papo GPT2 | 88 milhões | - | 2.28 | 0,54 | 10.3 | 16h25 | 61,54 | 78,94 |
| Romance GPT | 95,5 milhões | 21h27 | 5,96 | 2,71 | 8,0 | 11,72 | 66,12 | 83,34 |
| Base GPT LCCC | 95,5 milhões | 18h38 | 6,48 | 3.08 | 8.3 | 12,68 | 66,21 | 83,54 |
| Base GPT2 LCCC | 95,5 milhões | 22,76 | 5,69 | 2,50 | 7.7 | 10,87 | 66,24 | 83,46 |
| GPT LCCC-grande | 95,5 milhões | 18h23 | 6,63 | 3.20 | 8.3 | 12,71 | 66,25 | 83,63 |
Também empregamos três anotadores de crowdsourcing para avaliar 200 amostras de cada modelo sobre fluência, relevância e diversidade com base em um esquema de pontuação 2/1/0. Consulte nosso artigo para obter mais detalhes.
| Modelos | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformador | 42,4% | 23,6% | 34,0% | 0,4429 |
| Bate-papo GPT2 | 24,3% | 19,1% | 56,6% | 0,3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-grande | 48,6% | 24,5% | 27,0% | 0,4203 |
Selecionamos aleatoriamente 1000 amostras geradas e fazemos uma estatística de geração tóxica:
| Repetição | Palavra suja | Outros casos graves |
|---|---|---|
| vinte e três | 9 | 2 |
Exemplos gerados em uma única volta do conjunto de dados STC (ajustados no STC):
| Publicar | Resposta |
|---|---|
| Na verdade, estamos em Pequim, não em Harbin. | O clima em Harbin parece ser melhor do que em Pequim. Chove levemente aqui e há ventos fortes durante o dia. |
| A competição de publicidade no campus da operadora foi muito divertida! Hahaha. | Achei que fosse o anúncio de Jack Ma. |
| Vestido de noiva da série Delsa S posa candy color, rosa, azul, vermelho e roxo, lúdico e fresco, você gostou? | A última é tão linda, tão linda! |
Exemplos gerados em múltiplas voltas usando o script interativo:
| Roel | Resposta |
|---|---|
| Usuário | Não me ame sem sucesso |
| Robô | O amor infrutífero é tão doloroso. |
| Usuário | Mas está tudo bem se você amou |
| Robô | Às vezes, o amor é um jogo. |
| Usuário | Eu sempre perco |
| Robô | Eu te amo tanto quanto eu te amo. |
| Usuário | Você pode puxá-lo? |
| Robô | Você pode puxá-lo. |
| Usuário | Não me imite |
| Robô | O que estou dizendo é que você não pode fazer isso. |
| Usuário | Você me força a fazer isso, certo? |
| Robô | Não, estou forçando você a falar, certo? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
O conjunto de dados LCCC e os modelos pré-treinados visam facilitar a pesquisa para geração de conversas. O conjunto de dados LCCC fornecido neste repositório é originário de diversas fontes. foi completamente filtrado. Todo o conteúdo contido neste conjunto de dados não representa a opinião dos autores. Este repositório contém apenas parte do mecanismo de modelagem necessário para realmente produzir um modelo de diálogo. Não somos responsáveis por qualquer conteúdo gerado usando nosso modelo.
Por favor, cite nosso artigo se você usar os conjuntos de dados ou modelos em sua pesquisa:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


