L2MAC
1.0.0
Pioneirismo na primeira estrutura prática de computador automático de programa armazenado de uso geral baseado em LLM (arquitetura von Neumann) em um sistema multiagente baseado em LLM, para resolver tarefas complexas por meio da geração de saídas extensas e consistentes, ilimitadas pela restrição de janela de contexto fixa do LLMs .
? Poderia. 7 a 11 de 2024: Apresentaremos o L2MAC na Conferência Internacional sobre Representações de Aprendizagem (ICLR) 2024. Venha nos encontrar no ICLR em Viena, Áustria! Entre em contato comigo pelo telefone sih31 (at) cam.ac.uk para que possamos nos encontrar. Reuniões virtuais também são aceitas!
? Abril. 23 de outubro de 2024: L2MAC é totalmente de código aberto com a versão inicial lançada.
16 de janeiro de 2024: O artigo L2MAC: Large Language Model Automatic Computer for Extensive Code Generation foi aceito para apresentação no ICLR 2024!
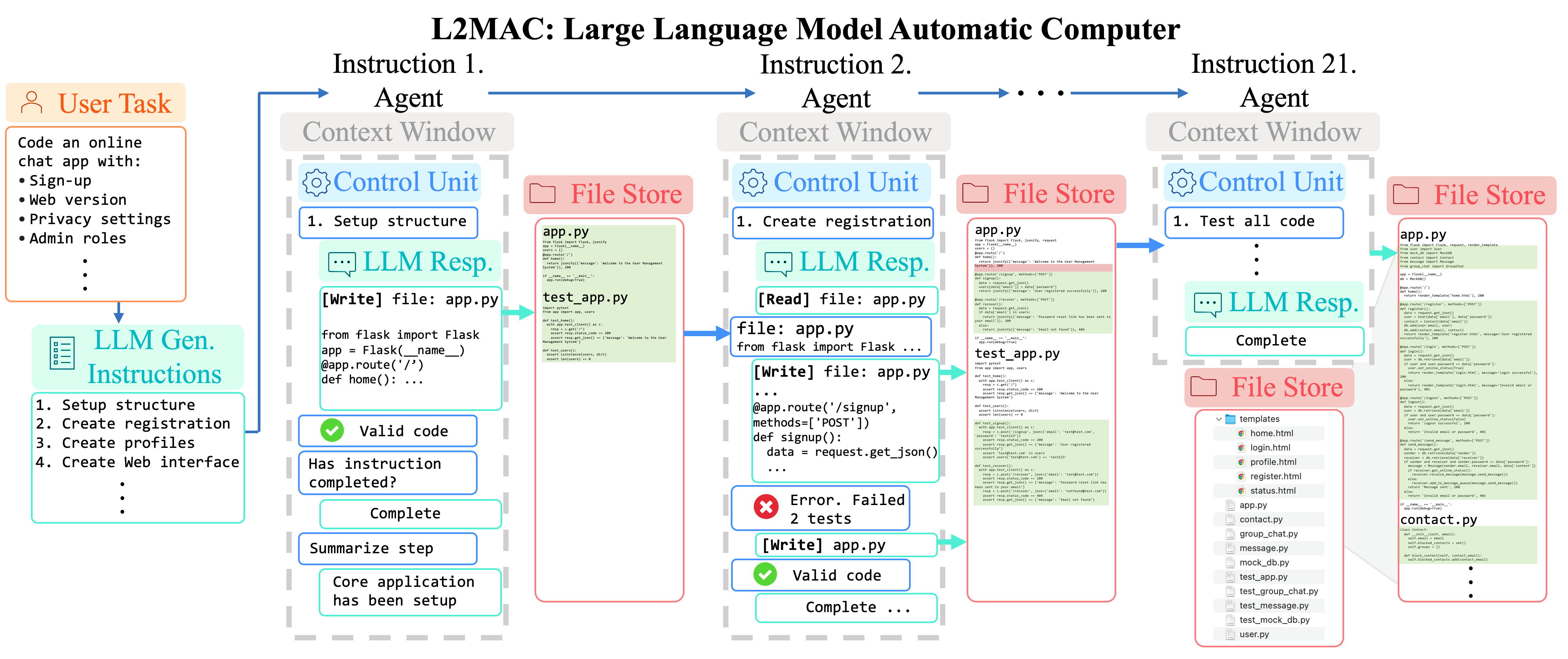
Instanciação LLM-Automatic Computer (L2MAC) para codificar uma base de código grande e complexa para um aplicativo inteiro com base em um único prompt do usuário . Aqui fornecemos ao L2MAC ferramentas adicionais para verificar quaisquer erros de sintaxe no código e executar quaisquer testes de unidade, se existirem.
Certifique-se de que o Python 3.7+ esteja instalado em seu sistema. Você pode verificar isso usando:
python --version. Você pode usar o conda assim:conda create -n l2mac python=3.9 && conda activate l2mac
pip install --upgrade l2mac
# or `pip install --upgrade git+https://github.com/samholt/l2mac`
# or `git clone https://github.com/samholt/l2mac && cd l2mac && pip install --upgrade -e .`Para obter orientação de instalação detalhada, consulte a instalação
Você pode iniciar a configuração do L2MAC executando o seguinte comando ou criar manualmente o arquivo ~/.L2MAC/config.yaml :
# Check https://samholt.github.io/L2MAC/guide/get_started/configuration.html for more details
l2mac --init-config # it will create ~/.l2mac/config.yaml, just modify it to your needs Você pode configurar ~/.l2mac/config.yaml de acordo com o exemplo e documento:
llm :
api_type : " openai " # or azure etc. Check ApiType for more options
model : " gpt-4-turbo-preview " # or "gpt-4-turbo"
base_url : " https://api.openai.com/v1 " # or forward url / other llm url
api_key : " YOUR_API_KEY "Após a instalação, você pode usar L2MAC CLI
l2mac " Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid. " # this will create a codebase repo in ./workspaceou use-o como uma biblioteca
from l2mac import generate_codebase
codebase : dict = generate_codebase ( "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." )
print ( codebase ) # it will print the codebase (repo) complete with all the files as a dictionary, and produce a local codebase folder in ./workspace? Junte-se ao nosso canal Discord! Esperamos ver você lá! ?
Se você tiver alguma dúvida ou feedback sobre este projeto, não hesite em nos contatar. Agradecemos muito suas sugestões!
Responderemos a todas as perguntas dentro de 2 a 3 dias úteis.
Para se manter atualizado com as últimas pesquisas e desenvolvimentos, siga @samaianholt no Twitter.
Para citar L2MAC em publicações, use a seguinte entrada BibTeX.
@inproceedings {
holt2024lmac,
title = { L2{MAC}: Large Language Model Automatic Computer for Unbounded Code Generation } ,
author = { Samuel Holt and Max Ruiz Luyten and Mihaela van der Schaar } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=EhrzQwsV4K }
}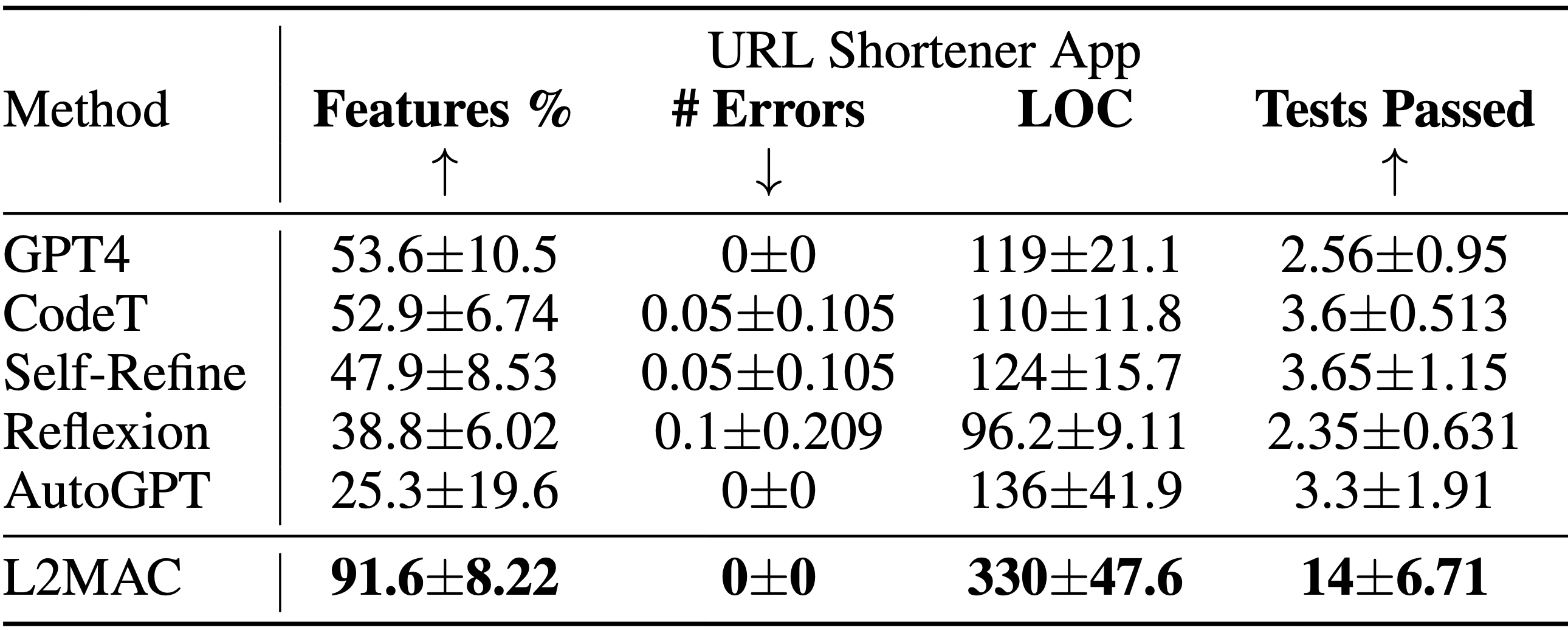
Instanciação LLM-Automatic Computer (L2MAC) para codificar uma base de código grande e complexa para um aplicativo inteiro com base em um único prompt do usuário . Resultados da tarefa de design do sistema de geração de base de código mostrando a porcentagem de recursos funcionais especificados que estão totalmente implementados ( Features% ), o número de erros sintáticos no código gerado ( #Errors ), o número de linhas de código ( LOC ) e o número de passando nos testes ( Testes aprovados ). L2MAC implementa totalmente a maior porcentagem de requisitos de recursos de tarefas especificados pelo usuário em todas as tarefas, gerando código totalmente funcional que possui erros sintáticos mínimos e um alto número de testes de unidade autogerados aprovados, portanto, é o estado da arte para o geração de grandes bases de código de saída e igualmente competitivo para a geração de grandes tarefas de saída. Os resultados são calculados em média sobre 10 sementes aleatórias.
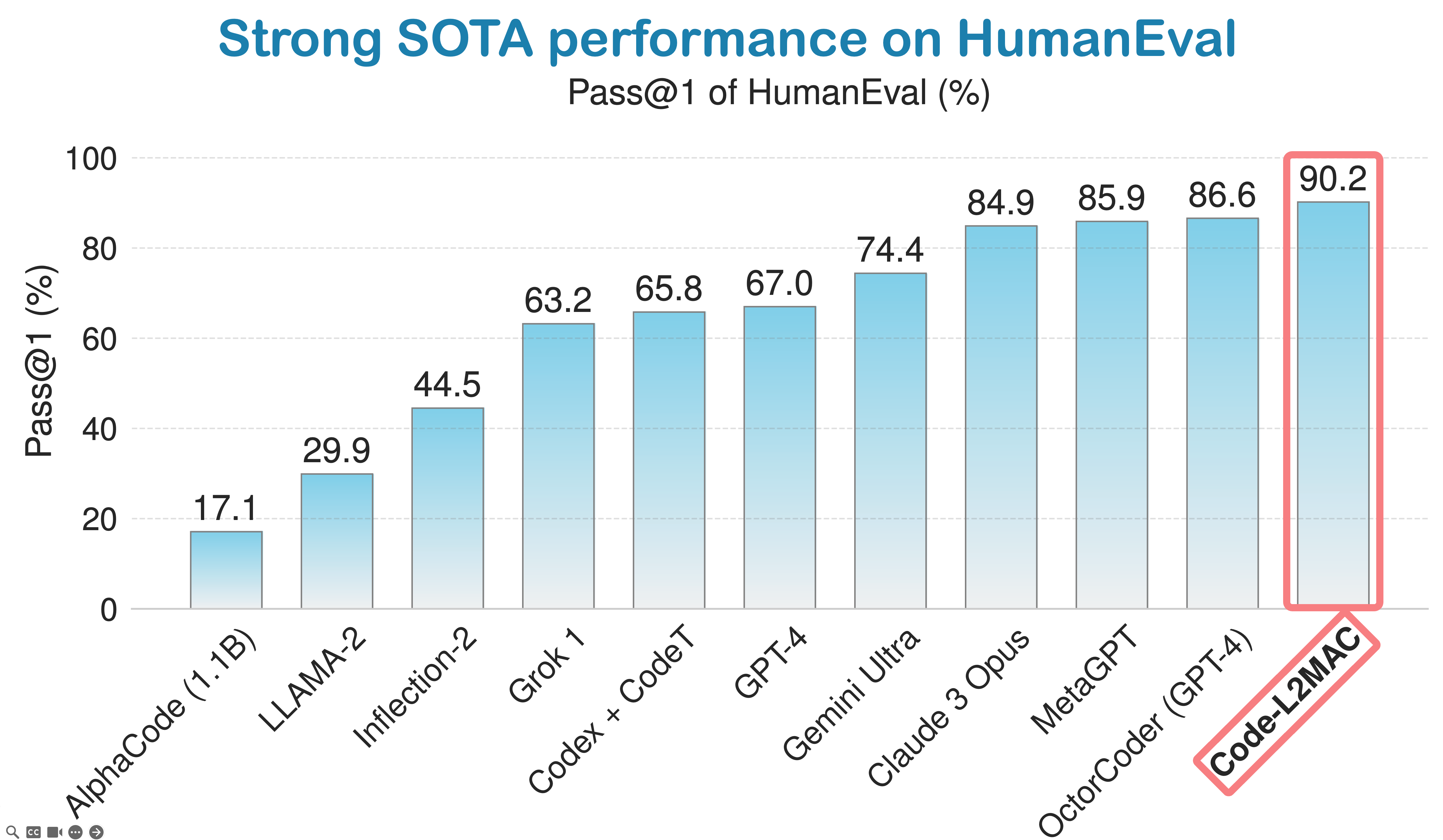
LLM-Automatic Computer (L2MAC) alcança forte desempenho no benchmark de codificação HumanEval e está atualmente classificado como o terceiro melhor agente de codificação de IA do mundo na tabela de classificação padrão da indústria de codificação global da HumanEval.
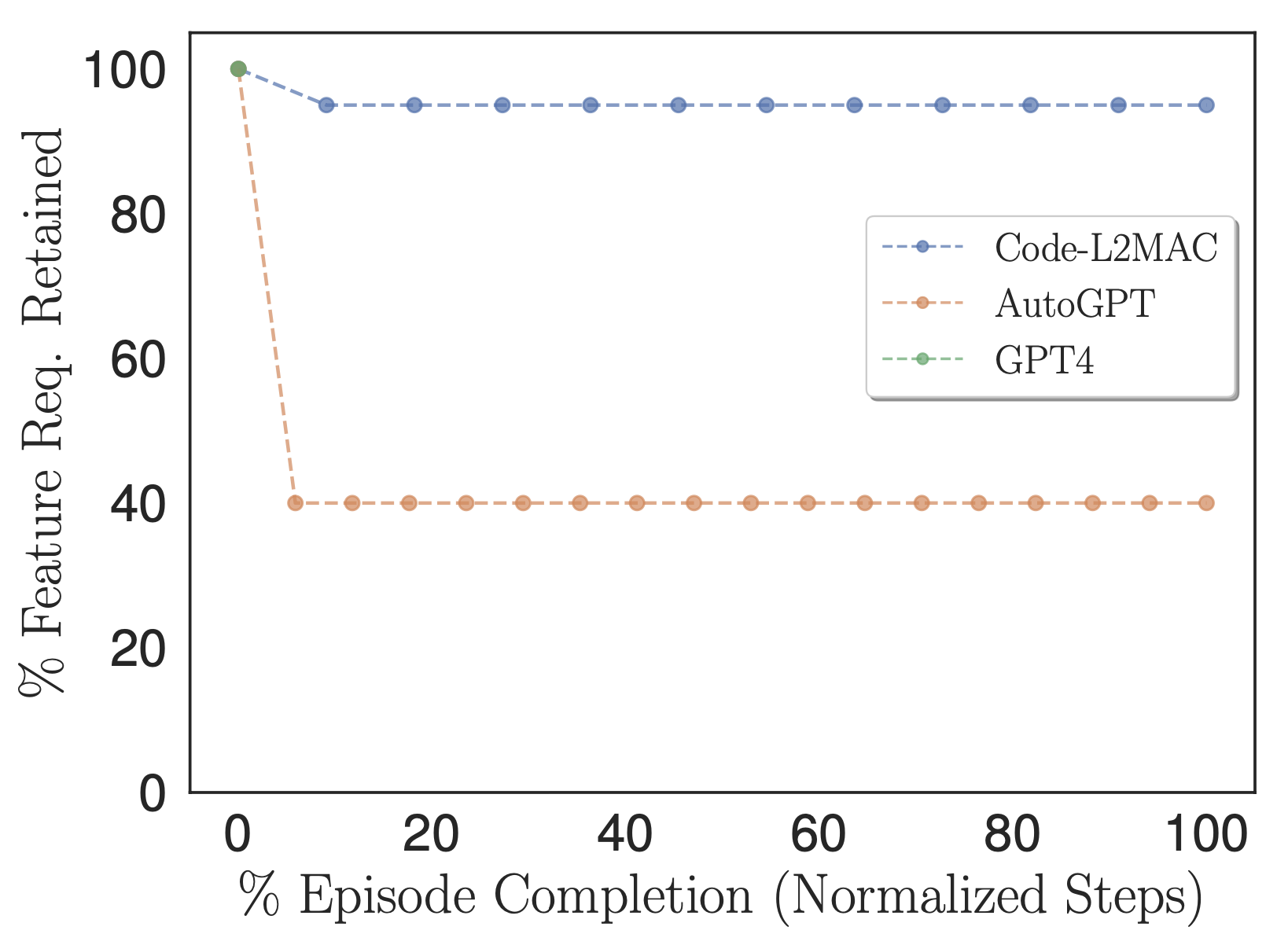
Porcentagem de requisitos de recursos especificados pelo usuário que são retidos nas instruções da tarefa de métodos e usados no contexto.
Para explorar se os métodos avaliados durante a operação contêm as informações dentro de seu contexto para concluir a tarefa diretamente, adaptamos nossa métrica % de recursos para contar o número de requisitos de recursos de tarefa especificados pelo usuário que são retidos nas instruções de tarefa dos métodos, ou seja, aqueles instruções que eventualmente são alimentadas em sua janela de contexto durante sua operação, conforme mostrado na figura acima. Empiricamente, observamos que o L2MAC é capaz de reter um grande número de requisitos de recursos de tarefas especificados pelo usuário em seu programa de prompt e executar tarefas de longa duração orientadas por instruções. Observamos que o AutoGPT também traduz inicialmente os requisitos de recursos de tarefas especificados pelo usuário em instruções de tarefas; no entanto, faz isso com maior compactação – condensando a informação em uma mera descrição de seis frases. Este processo resulta na perda de informações cruciais da tarefa, necessárias para concluir corretamente a tarefa geral, de modo que se alinhe com a tarefa detalhada especificada pelo usuário.
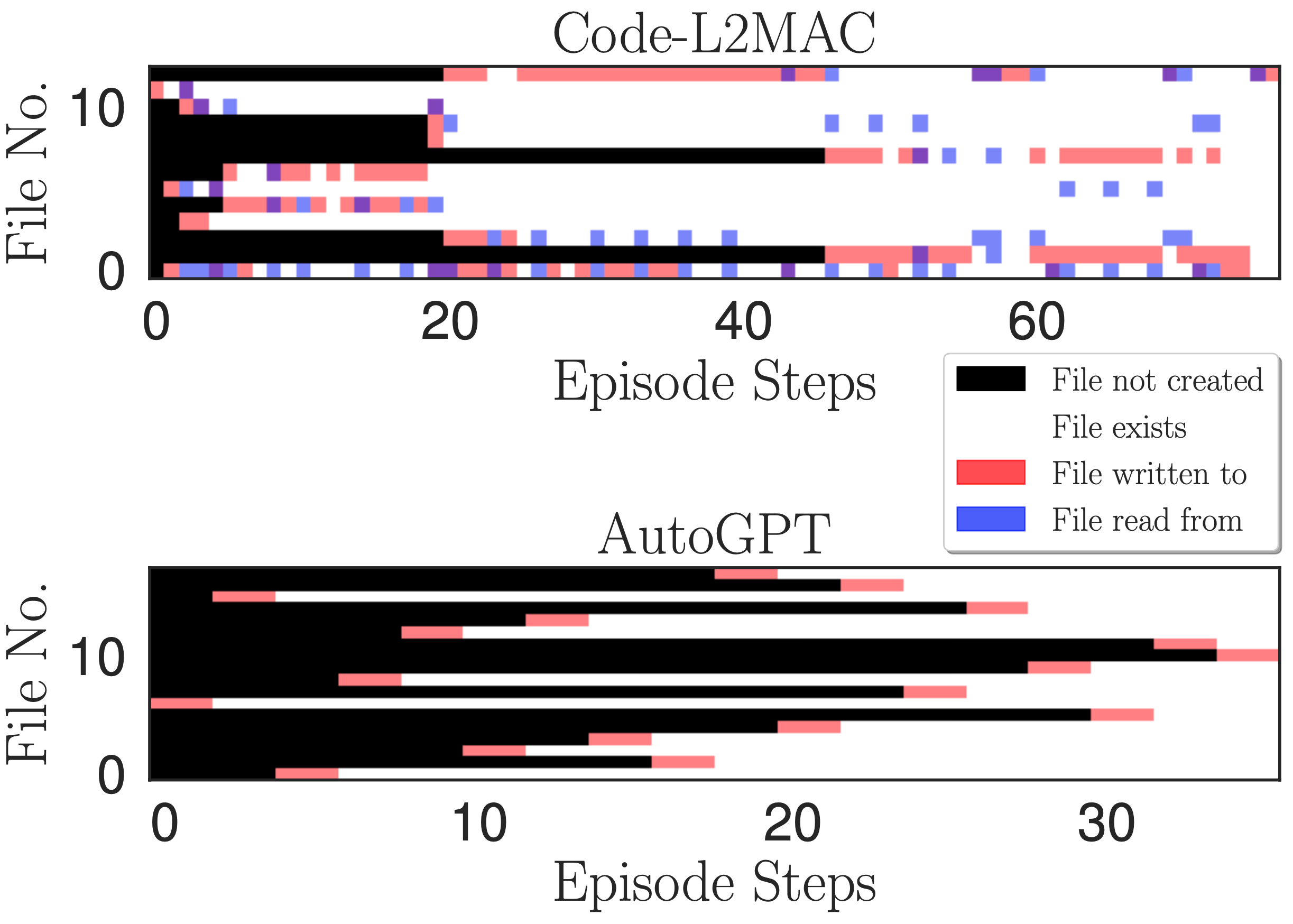
Mapa de calor de acesso a arquivos. Indicando leitura, gravação e quando os arquivos são criados em cada etapa da operação de gravação durante um episódio para a tarefa do aplicativo de bate-papo online.
Desejamos entender, durante a operação de execução de uma instrução de tarefa, se o L2MAC pode compreender os arquivos de código gerados existentes dentro da base de código - que poderiam ter sido criados há muitas instruções atrás, e através de sua compreensão, criar novos arquivos que se inter-relacionam com o arquivos existentes e, o mais importante, atualizar os arquivos de código existentes à medida que novos recursos são implementados. Para obter informações, traçamos um mapa de calor da leitura, gravação e quando os arquivos são criados em cada etapa da operação de gravação durante um episódio na figura acima. Observamos que o L2MAC tem uma compreensão do código gerado existente que lhe permite atualizar arquivos de código existentes, mesmo aqueles originalmente criados há muitas etapas de instrução, e pode visualizar os arquivos quando não tiver certeza e atualizá-los escrevendo nos arquivos. Por outro lado, o AutoGPT geralmente grava em arquivos apenas uma vez, ao criá-los inicialmente, e só pode atualizar arquivos que ele conhece e que estão retidos em sua janela de contexto atual. Embora também tenha uma ferramenta de leitura de arquivo, muitas vezes ele se esquece dos arquivos que criou há muitas iterações devido à sua abordagem de manipulação de janela de contexto de resumir as mensagens de diálogo mais antigas em sua janela de contexto, ou seja, uma compactação contínua com perdas do progresso anterior feito durante a operação de conclusão da tarefa.
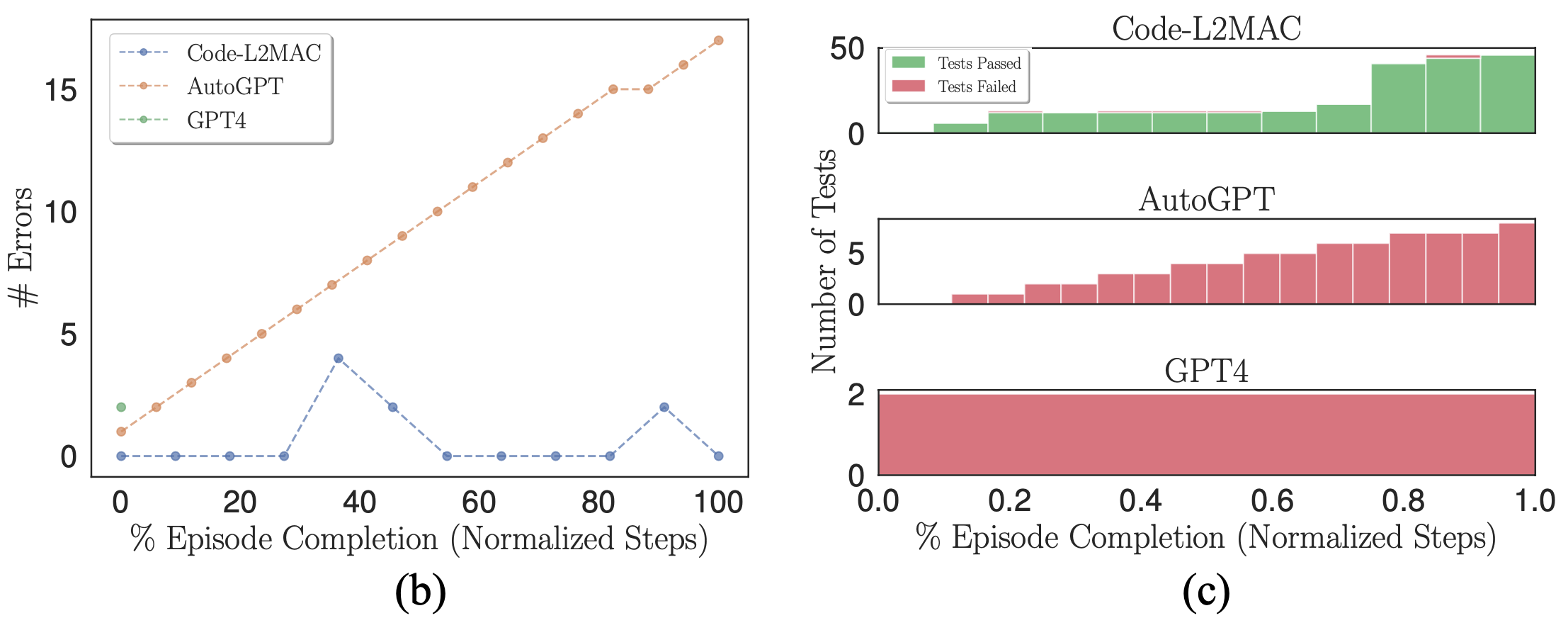
(b) Número de erros sintáticos na base de código. (c) Histogramas empilhados de aprovação e reprovação em testes de unidade autogerados.
Ao usar um modelo probabilístico (LLM) como gerador de código de saída, erros podem ocorrer naturalmente em suas saídas. Portanto, desejamos verificar se, quando aparecem erros, os respectivos métodos de benchmark podem corrigir erros na base de código. Plotamos o número de erros sintáticos na base de código durante uma execução onde os erros são cometidos na figura (b) acima. Observamos que o L2MAC pode corrigir corretamente a base de código gerada anteriormente que contém erros, que podem surgir de erros sintáticos do último arquivo gravado ou de outros arquivos que dependem do arquivo gravado mais recentemente, que agora contêm erros. Ele faz isso sendo apresentado à saída do erro quando ele surge e modificando a base de código para resolver o erro enquanto ainda conclui a instrução atual. Por outro lado, o AutoGPT não consegue detectar quando um erro na base de código foi cometido e continua operando, o que pode aumentar o número de erros formados na base de código.
Além disso, L2MAC gera testes de unidade junto com o código funcional e os usa como um verificador de erros para inspecionar as funcionalidades da base de código conforme ela é gerada e pode usar esses erros para corrigir a base de código para passar em testes de unidade que agora falham após atualizar parte de um existente arquivo. Mostramos isso na figura (c) acima e observamos que o AutoGPT, embora solicitado a escrever também testes unitários para todo o código gerado, é incapaz de usar esses testes como uma verificação de erro de integridade, o que poderia ser agravado pela observação de que o AutoGPT esquece qual arquivos que ele criou anteriormente e, portanto, incapaz de modificar os arquivos de código esquecidos existentes à medida que novas modificações são feitas, levando a arquivos de código incompatíveis.
Apresentamos L2MAC, a primeira estrutura de computador de programa armazenado de uso geral baseada em LLM que aumenta LLMs de maneira eficaz e escalonável com um armazenamento de memória para tarefas longas de geração de saída onde isso não foi alcançado anteriormente com sucesso. Especificamente, o L2MAC, quando aplicado para tarefas longas de geração de código, supera as soluções existentes – e é uma ferramenta imensamente útil para desenvolvimento rápido. Agradecemos contribuições e encorajamos você a usar e citar o projeto. Clique aqui para começar.
Incluímos uma galeria de exemplos de aplicativos inteiramente produzidos pelo LLM Automatic Computer (L2MAC) a partir de um único prompt de entrada. L2MAC se destaca na resolução de grandes tarefas complexas, como ser o estado da arte para gerar grandes bases de código, ou pode até escrever livros inteiros, todos os quais contornando as restrições tradicionais da restrição de janela de contexto fixa do LLM.
Basta digitar l2mac "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." , você obteria uma base de código completa para um jogo totalmente jogável, conforme mostrado aqui.
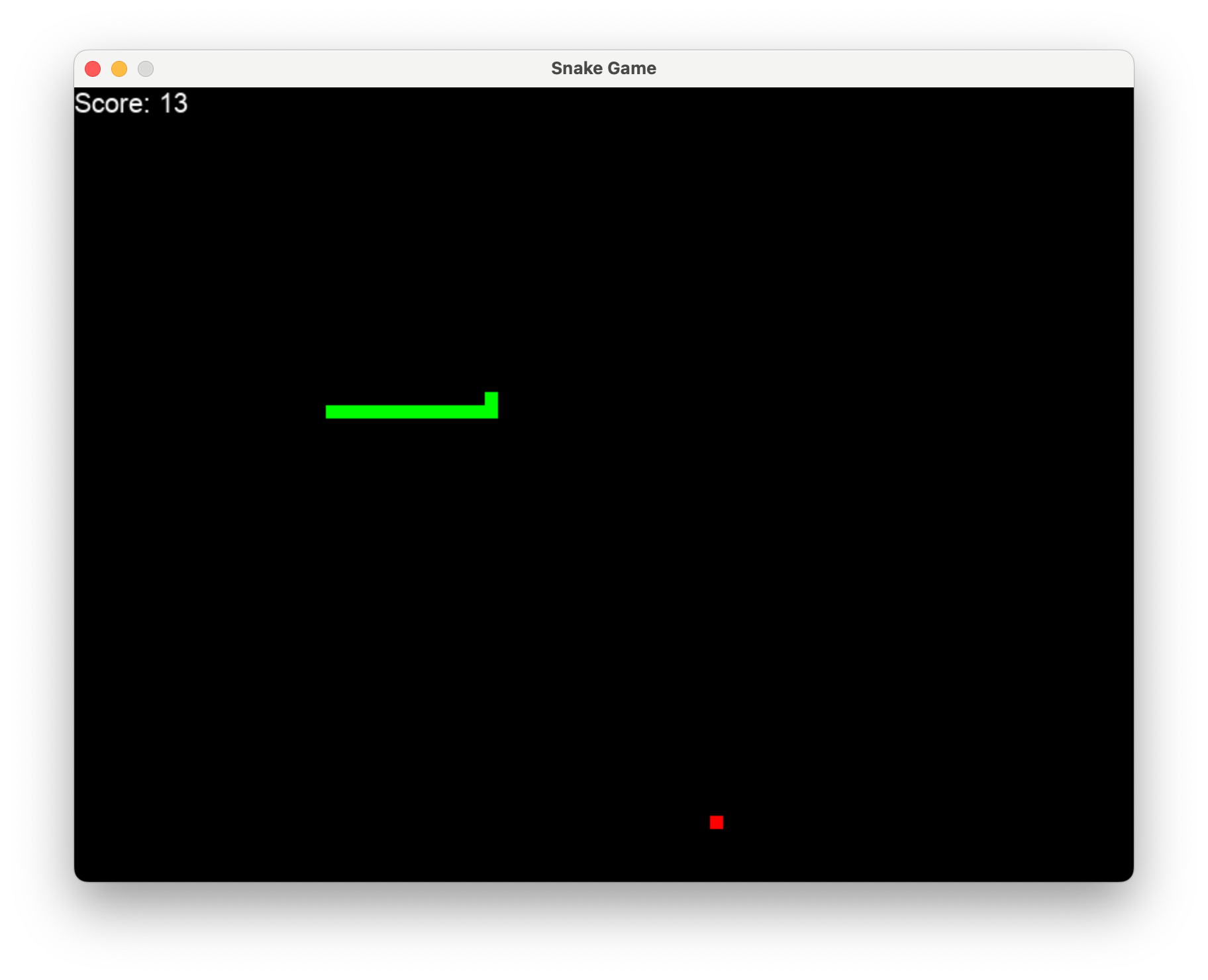
Clique aqui para ver os arquivos completos no github ou baixe-os aqui. O código e o prompt para gerar isso estão aqui.
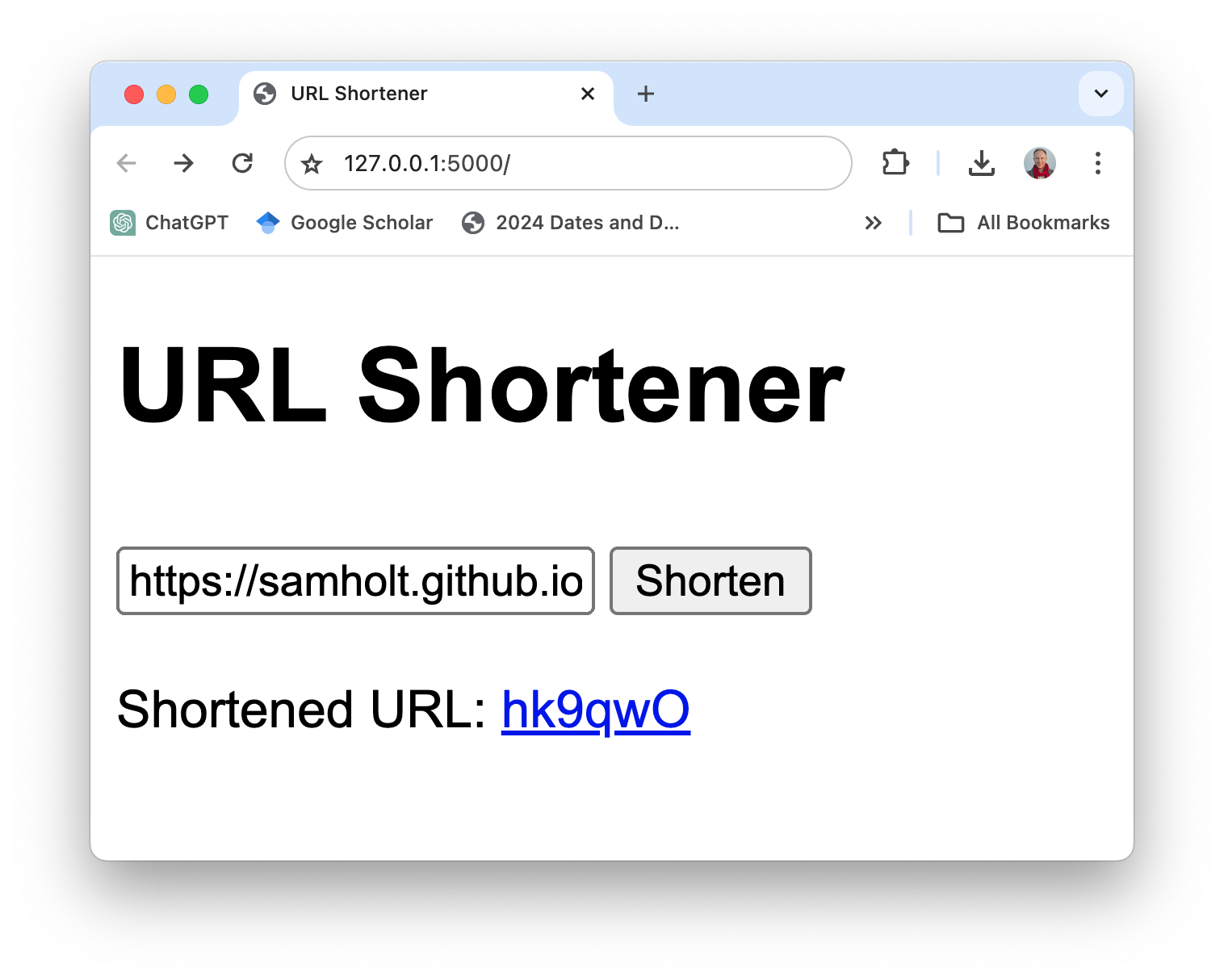
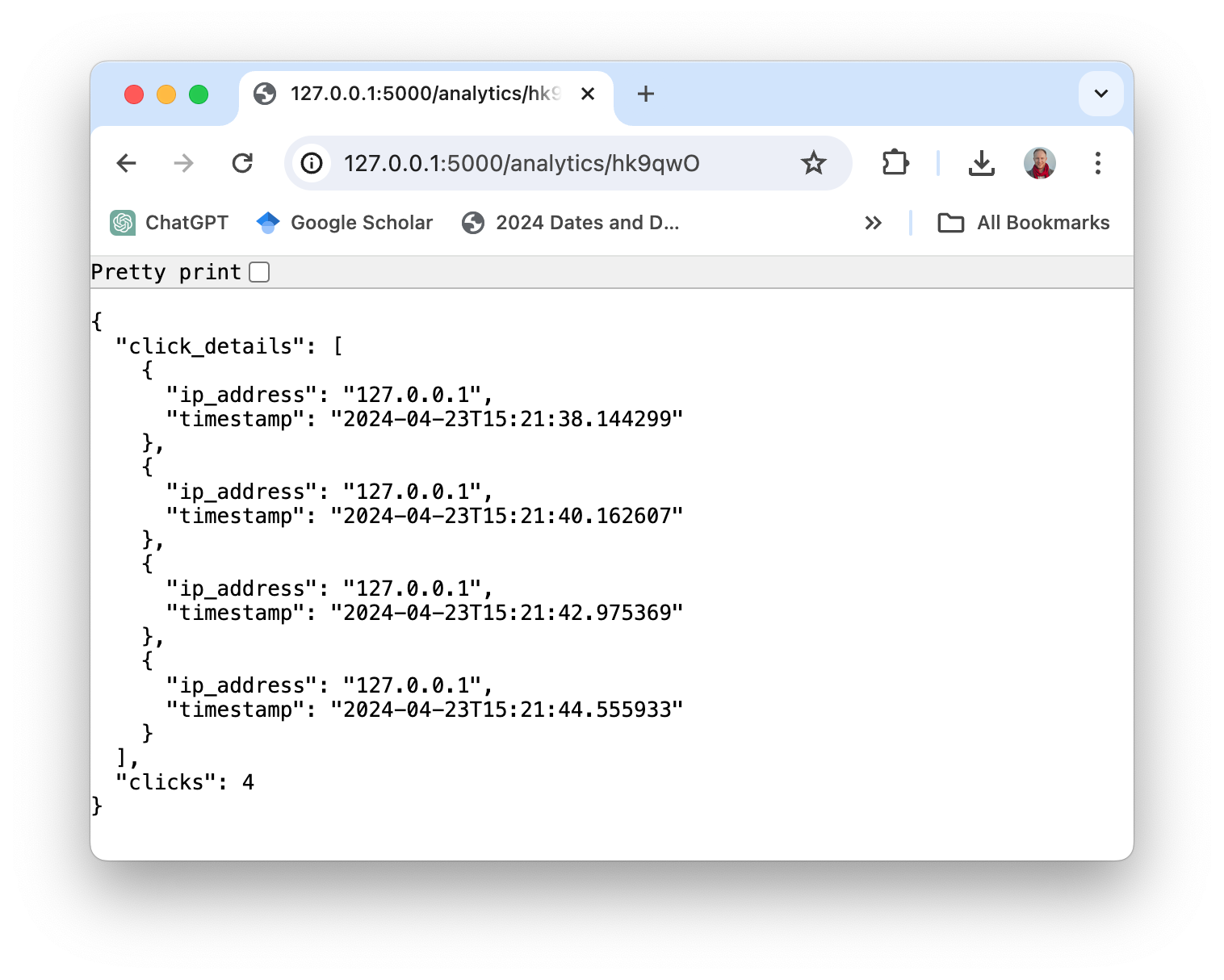
Clique aqui para ver os arquivos completos no github ou baixe-os aqui. O código e o prompt para gerar isso estão aqui.
Basta dar ao L2MAC a solicitação de Write a complete recipe book for the following book title of "Twirls & Tastes: A Journey Through Italian Pasta". Description: "Twirls & Tastes" invites you on a flavorful expedition across Italy, exploring the diverse pasta landscape from the sun-drenched hills of Tuscany to the bustling streets of Naples. Discover regional specialties, learn the stories behind each dish, and master the art of pasta making with easy-to-follow recipes that promise to delight your senses. e pode gerar um livro completo de 26 páginas automaticamente.

Clique aqui para o livro completo; L2MAC produziu todo o texto do livro e todas as imagens foram criadas com DALLE.
Os arquivos de texto de saída completos estão no github; você pode baixá-los aqui. O código e o prompt para gerar isso estão aqui.
Clique aqui para ver os arquivos completos no github ou baixe-os aqui. O código e o prompt para gerar isso estão aqui.
Estamos procurando ativamente que você carregue seus próprios aplicativos incríveis aqui, enviando um PR com o aplicativo que você criou, compartilhando-o com um problema do GitHub ou compartilhando-o no canal Discord.


