VisualGLM 6B
1.0.0
?Repo HF • ⚒️ SwissArmyTransformer (sábado) • ?
• ?[CogView@NeurIPS 21] [GitHub] • [GLM@ACL 22] [GitHub]
Junte-se a nós no Slack e WeChat
[2023.10] Bem-vindo ao CogVLM (https://github.com/THUDM/CogVLM), um modelo de diálogo multimodal de nova geração da Zhipu AI. Ele adota a nova arquitetura de especialistas visuais e conquistou o primeiro lugar em 10. tarefas multimodais clássicas autorizadas. O atual modelo inglês CogVLM-17B de código aberto será baseado no modelo chinês de código aberto GLM.
VisualGLM-6B é um modelo de linguagem de diálogo multimodal de código aberto que suporta imagens, chinês e inglês . O modelo de linguagem é baseado em ChatGLM-6B com 6,2 bilhões de parâmetros, a parte da imagem constrói uma ponte entre o modelo visual e o modelo visual. modelo de linguagem através do treinamento do BLIP2-Qformer, com o modelo total compreendendo 7,8 bilhões de parâmetros Clique aqui para versão em inglês.
VisualGLM-6B é um modelo de linguagem de diálogo multimodal de código aberto que suporta imagens, chinês e inglês . O modelo de linguagem é baseado no ChatGLM-6B e possui 6,2 bilhões de parâmetros. A parte da imagem constrói uma ponte entre o modelo visual e o modelo de linguagem. treinando BLIP2-Qformer, o modelo geral tem um total de 7,8 bilhões de parâmetros.
VisualGLM-6B depende de 30 milhões de pares de imagens e textos chineses de alta qualidade do conjunto de dados CogView e é pré-treinado com 300 milhões de pares de imagens e textos em inglês. Este método de treinamento alinha melhor as informações visuais ao espaço semântico do ChatGLM. No estágio subsequente de ajuste fino, o modelo é treinado em longas perguntas visuais e dados de resposta para gerar respostas que estejam de acordo com as preferências humanas.
VisualGLM-6B é treinado pela biblioteca SwissArmyTransformer ( sat , abreviadamente), que é uma biblioteca de ferramentas que oferece suporte à modificação e treinamento flexíveis do Transformer e oferece suporte a métodos eficientes de ajuste fino de parâmetros, como Lora e P-tuning. Este projeto fornece uma interface huggingface que está em conformidade com os hábitos do usuário e também fornece uma interface baseada em sat.
Combinado com a tecnologia de quantização de modelo, os usuários podem implantá-lo localmente em placas gráficas de consumo (o mínimo necessário é 6,3 G de memória de vídeo no nível de quantização INT4).
O modelo de código aberto VisualGLM-6B visa promover o desenvolvimento de tecnologia de modelo grande junto com a comunidade de desenvolvedores de código aberto e todos são gentilmente solicitados a cumprir o acordo de código aberto e não usar este modelo de código aberto e código e derivados baseados nele. este projeto de código aberto para qualquer finalidade que possa trazer danos ao país e à sociedade. Usos prejudiciais e quaisquer serviços que não tenham sido avaliados e documentados em termos de segurança. Atualmente, este projeto não desenvolveu oficialmente nenhum aplicativo baseado em VisualGLM-6B, incluindo sites, aplicativos Android, aplicativos Apple iOS, aplicativos Windows, etc.
Como o VisualGLM-6B ainda está na versão v1, atualmente sabe-se que ele tem algumas limitações , como problemas de factualidade/alucinação do modelo na descrição da imagem, captura insuficiente de informações detalhadas da imagem e algumas limitações de modelos de linguagem. Embora o modelo se esforce para garantir a conformidade e a precisão dos dados em todas as fases do treinamento, devido à pequena escala do modelo VisualGLM-6B e ao fato de o modelo ser afetado por fatores probabilísticos e aleatórios, a precisão do conteúdo de saída não pode ser garantida , e o modelo é facilmente enganoso (consulte a seção Limitações para obter detalhes). Nas versões subsequentes do VisualGLM, serão feitos esforços para otimizar tais problemas. Este projeto não assume quaisquer riscos e responsabilidades decorrentes de riscos de segurança de dados e de opinião pública causados por modelos e códigos de código aberto, ou qualquer modelo que seja enganado, abusado, disseminado ou explorado indevidamente.
VisualGLM-6B pode realizar perguntas e respostas relacionadas ao conhecimento da descrição da imagem. 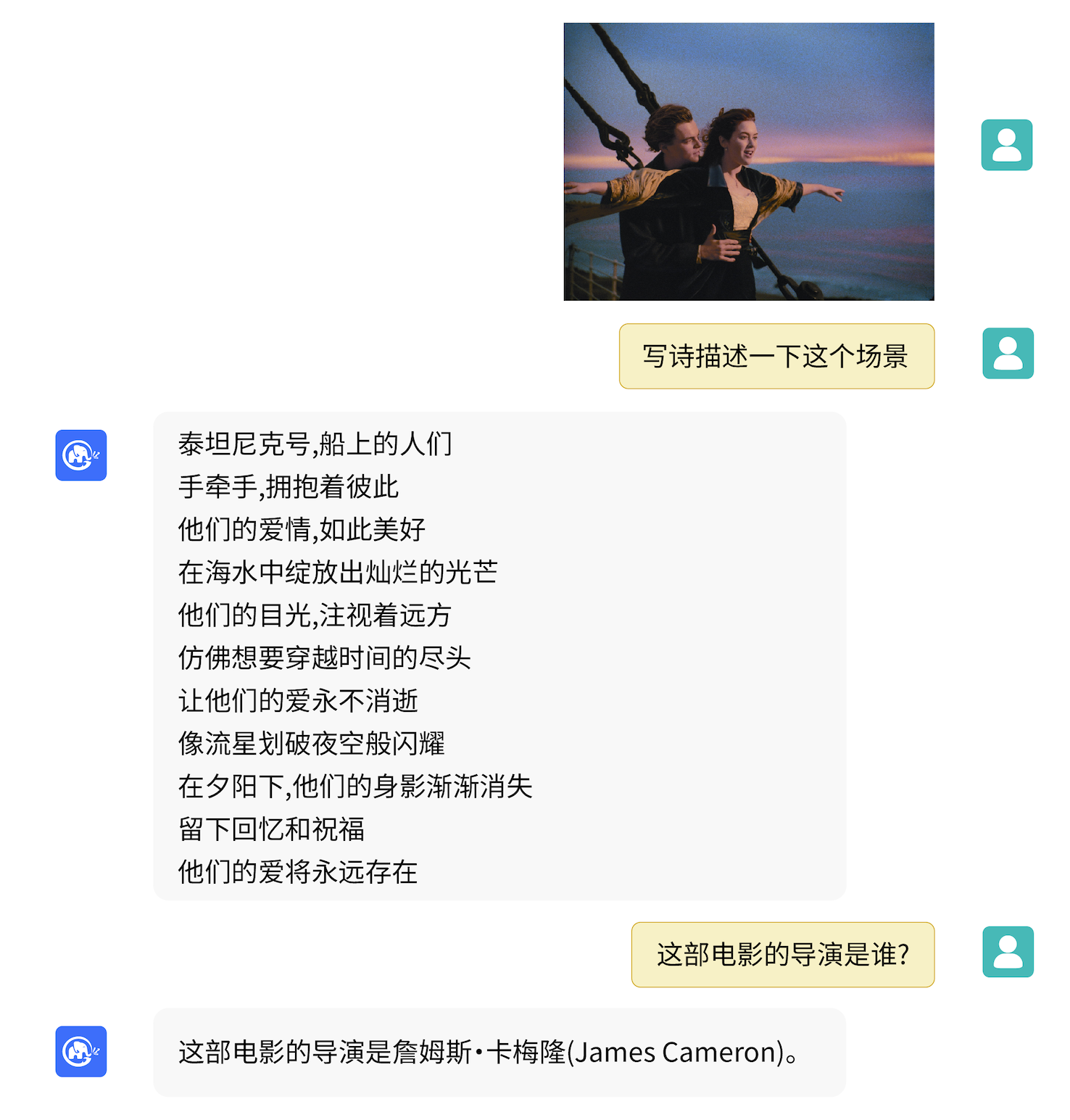


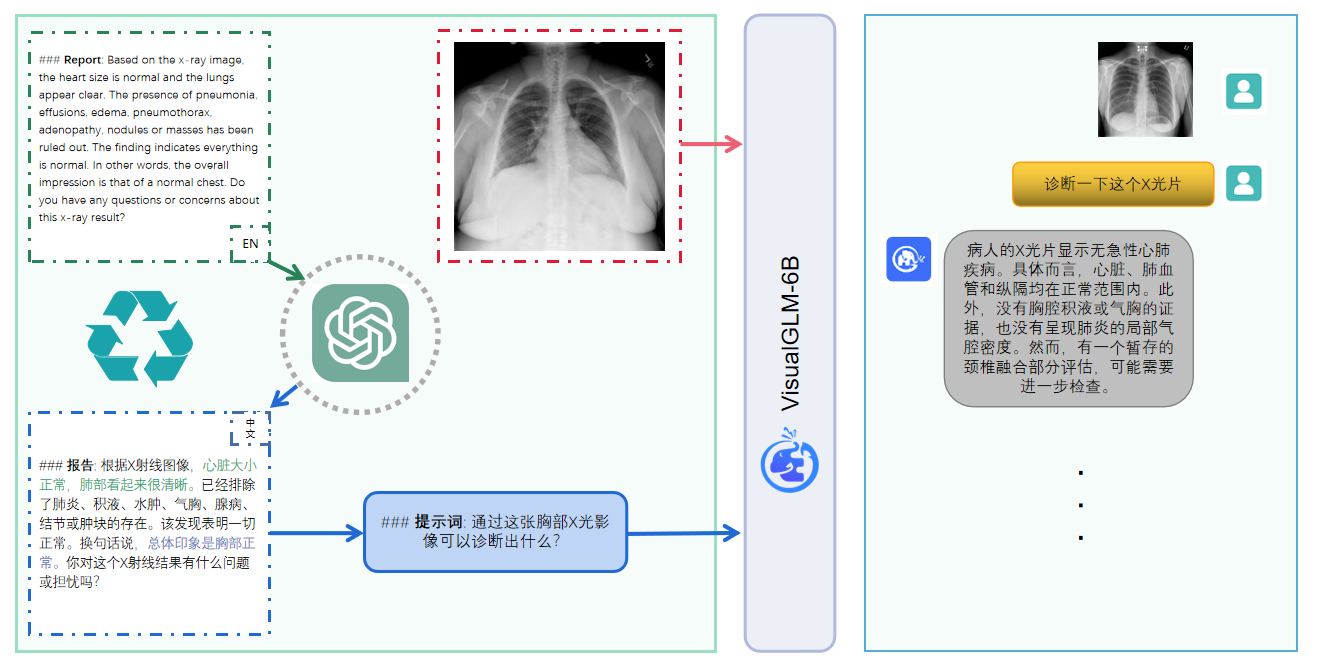

Use pip para instalar dependências
pip install -i https://pypi.org/simple -r requirements.txt
# 国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
Neste momento, deepspeed (que suporta treinamento de biblioteca sat ) será instalada por padrão. Esta biblioteca não é necessária para inferência de modelo. Ao mesmo tempo, alguns ambientes Windows encontrarão problemas ao instalar esta biblioteca. Se quisermos ignorar a instalação deepspeed , podemos alterar o comando para
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.4.4"
Se você usar a biblioteca de transformadores Huggingface para chamar o modelo ( você também precisa instalar o pacote de dependência acima! ), você pode passar o seguinte código (onde o caminho da imagem é o caminho local):
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True )
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). half (). cuda ()
image_path = "your image path"
response , history = model . chat ( tokenizer , image_path , "描述这张图片。" , history = [])
print ( response )
response , history = model . chat ( tokenizer , image_path , "这张图片可能是在什么场所拍摄的?" , history = history )
print ( response ) O código acima baixará automaticamente a implementação do modelo e os parâmetros dos transformers . A implementação completa do modelo pode ser encontrada em Hugging Face Hub. Se você demorar para baixar os parâmetros do modelo do Hugging Face Hub, poderá baixar manualmente o arquivo de parâmetros do modelo aqui e carregar o modelo localmente. Para métodos específicos, consulte Carregando o modelo do local. Para obter informações sobre quantificação, inferência de CPU, aceleração de backend Mac MPS, etc. com base no modelo de biblioteca de transformadores, consulte a implantação de baixo custo do ChatGLM-6B.
Se você usar a biblioteca SwissArmyTransformer para chamar o modelo, o método será semelhante. Você pode usar a variável de ambiente SAT_HOME para determinar o local de download do modelo. Neste diretório do warehouse:
import argparse
from transformers import AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/chatglm-6b" , trust_remote_code = True )
from model import chat , VisualGLMModel
model , model_args = VisualGLMModel . from_pretrained ( 'visualglm-6b' , args = argparse . Namespace ( fp16 = True , skip_init = True ))
from sat . model . mixins import CachedAutoregressiveMixin
model . add_mixin ( 'auto-regressive' , CachedAutoregressiveMixin ())
image_path = "your image path or URL"
response , history , cache_image = chat ( image_path , model , tokenizer , "描述这张图片。" , history = [])
print ( response )
response , history , cache_image = chat ( None , model , tokenizer , "这张图片可能是在什么场所拍摄的?" , history = history , image = cache_image )
print ( response ) O ajuste fino eficiente dos parâmetros também pode ser facilmente realizado usando a biblioteca sat .
As tarefas multimodais são amplamente distribuídas e de vários tipos, e a pré-formação muitas vezes não consegue abranger tudo. Aqui fornecemos um exemplo de ajuste fino de pequenas amostras, usando 20 imagens anotadas para aprimorar a capacidade do modelo de responder a perguntas "de fundo".
Descompacte fewshot-data.zip e execute o seguinte comando:
bash finetune/finetune_visualglm.sh
Atualmente, são suportados três métodos de ajuste fino:
--layer_range e --lora_rank podem ser ajustados de acordo com o cenário específico e o volume de dados.bash finetune/finetune_visualglm_qlora.sh . QLoRA quantiza a camada linear do ChatGLM com 4 bits e requer apenas 9,8 GB de memória de vídeo para ajuste fino.--use_lora por --use_ptuning , mas não é recomendado, a menos que o cenário de aplicação do modelo seja muito fixo.Após o treinamento, você pode usar o seguinte comando para inferência:
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
Antes do ajuste fino:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:人们总是被生活琐事所困扰,无法摆脱束缚.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一张狗的图片,它躺在木地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一台电脑键盘和两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
Após o ajuste fino:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是雨天,
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了雨天的情景,雨水淅淅沥沥地落在地面上。人们穿着雨衣或雨伞,走在雨中,似乎在寻找着什么.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是木质地板。
用户:什么颜色的地板
VisualGLM-6B:这张图片的背景是蓝色的。
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了一只棕色的小狗躺在蓝色的木质地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是电脑键盘。
用户:描述一下这张图片。
VisualGLM-6B:这张图片的特点是电脑键盘和护照。
用户:有几张护照
VisualGLM-6B:两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
Se quiser mesclar os parâmetros da parte LoRA nos pesos originais, você pode chamar merge_lora() , por exemplo:
from finetune_visualglm import FineTuneVisualGLMModel
import argparse
model , args = FineTuneVisualGLMModel . from_pretrained ( 'checkpoints/finetune-visualglm-6b-05-19-07-36' ,
args = argparse . Namespace (
fp16 = True ,
skip_init = True ,
use_gpu_initialization = True ,
device = 'cuda' ,
))
model . get_mixin ( 'lora' ). merge_lora ()
args . layer_range = []
args . save = 'merge_lora'
args . mode = 'inference'
from sat . training . model_io import save_checkpoint
save_checkpoint ( 1 , model , None , None , args ) O ajuste fino requer a instalação da biblioteca deepspeed . Atualmente, este processo suporta apenas sistemas Linux. Mais instruções de amostra e instruções de processo para sistemas Windows serão concluídas em um futuro próximo.
python cli_demo.py O programa baixará automaticamente o modelo sat e conduzirá uma conversa interativa na linha de comando e pressione Enter para gerar uma resposta. Enter clear para limpar o histórico da conversa.
 O programa fornece os seguintes hiperparâmetros para controlar o processo de geração e a precisão da quantização:
O programa fornece os seguintes hiperparâmetros para controlar o processo de geração e a precisão da quantização:
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
optional arguments:
-h, --help show this help message and exit
--max_length MAX_LENGTH
max length of the total sequence
--top_p TOP_P top p for nucleus sampling
--top_k TOP_K top k for top k sampling
--temperature TEMPERATURE
temperature for sampling
--english only output English
--quant {8,4} quantization bits
Deve-se observar que durante o treinamento, as palavras de prompt para pares de perguntas e respostas em inglês são Q: A: :, enquanto as instruções em chinês são问:答: As instruções em chinês são usadas na demonstração da web, portanto, as respostas em inglês serão piores. e misturado com chinês, se necessário. Para responder em inglês, use a opção --english em cli_demo.py .
Também fornecemos uma ferramenta de linha de comando com efeito de máquina de escrever herdada do ChatGLM-6B . Esta ferramenta usa o modelo Huggingface:
python cli_demo_hf.pyTambém oferecemos suporte ao modelo de implantação paralela de vários cartões: (Você precisa atualizar a versão mais recente do sat. Se você baixou o ponto de verificação antes, também precisa excluí-lo manualmente e baixá-lo novamente)
torchrun --nnode 1 --nproc-per-node 2 cli_demo_mp.py
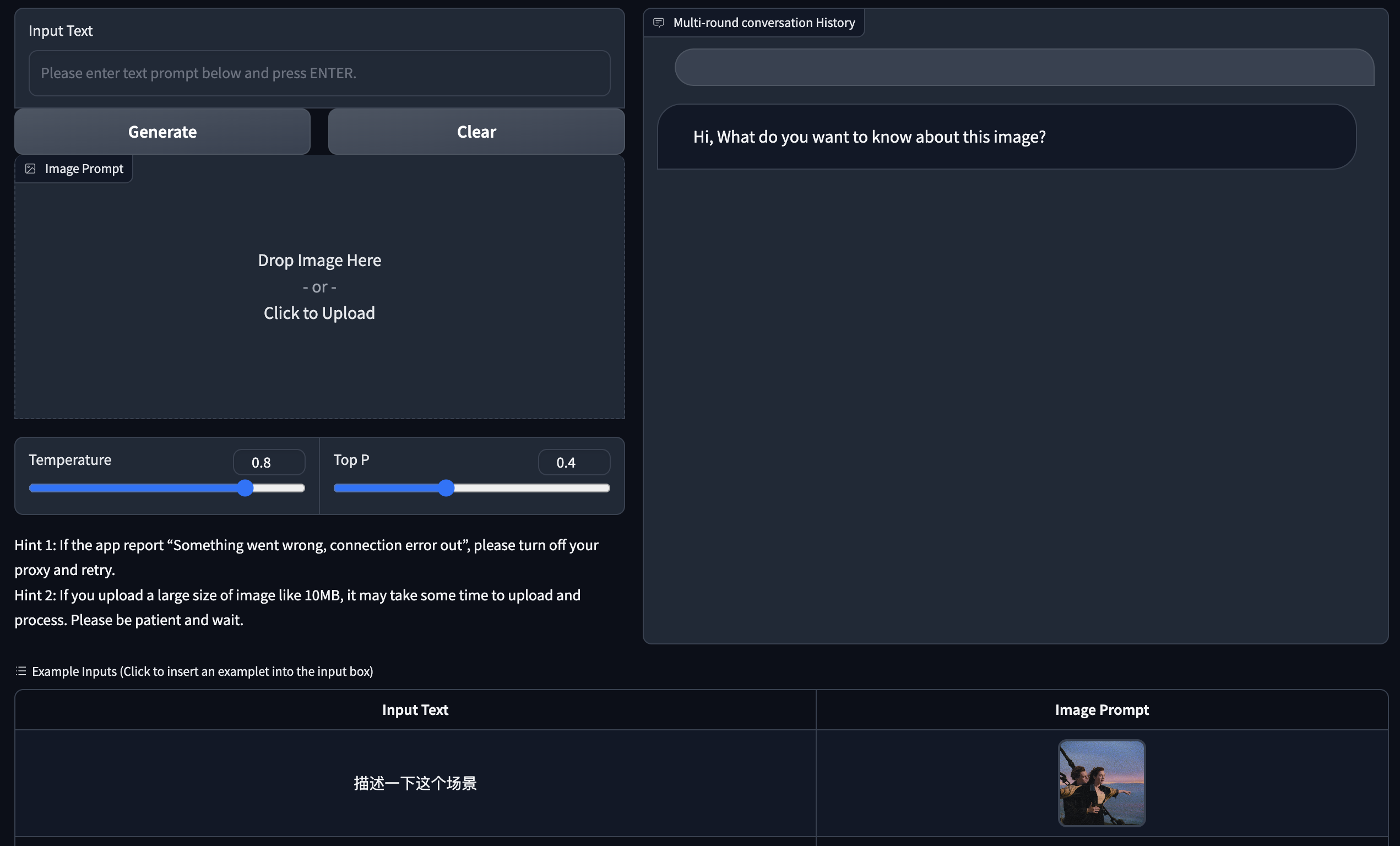
Fornecemos uma versão web Demo baseada no Gradio. Primeiro instale o Gradio: pip install gradio . Em seguida, baixe e entre neste warehouse para executar web_demo.py :
git clone https://github.com/THUDM/VisualGLM-6B
cd VisualGLM-6B
python web_demo.py
O programa baixará automaticamente o modelo sat, executará um servidor Web e gerará o endereço. Abra o endereço de saída em um navegador para usá-lo.
Também fornecemos uma ferramenta de versão web com efeito de máquina de escrever herdada do ChatGLM-6B . Esta ferramenta usa o modelo Huggingface e será executada na porta :8080 após a inicialização:
python web_demo_hf.py Ambas as demos da versão web aceitam o parâmetro de linha de comando --share para gerar links públicos gradio e aceitam --quant 4 e --quant 8 para usar quantização de 4 bits/quantização de 8 bits, respectivamente, para reduzir o uso de memória de vídeo.
Primeiro, você precisa instalar dependências adicionais pip install fastapi uvicorn e, em seguida, executar api.py no warehouse:
python api.py O programa baixará automaticamente o modelo sat, que é implantado na porta local 8080 por padrão e chamado através do método POST. A seguir está um exemplo de uso de curl para solicitação. De modo geral, você também pode usar o método de código para executar POST.
echo " { " image " : " $( base64 path/to/example.jpg ) " , " text " : "描述这张图片" , " history " :[]} " > temp.json
curl -X POST -H " Content-Type: application/json " -d @temp.json http://127.0.0.1:8080O valor de retorno obtido é
{
"response":"这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。",
"history":[('描述这张图片', '这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。')],
"status":200,
"time":"2023-05-16 20:20:10"
}
Também fornecemos api_hf.py que usa o modelo Huggingface. O uso é consistente com a API do modelo sat:
python api_hf.pyNa implementação do Huggingface, o modelo é carregado com precisão FP16 por padrão e a execução do código acima requer aproximadamente 15 GB de memória de vídeo. Se sua GPU tiver memória limitada, você pode tentar carregar o modelo no modo quantizado. Como usar:
# 按需修改,目前只支持 4/8 bit 量化。下面将只量化ChatGLM,ViT 量化时误差较大
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). quantize ( 8 ). half (). cuda () Na implementação sat, você precisa primeiro passar o parâmetro para alterar o local de carregamento para cpu e, em seguida, realizar a quantificação. O método é o seguinte, consulte cli_demo.py para obter detalhes:
from sat . quantization . kernels import quantize
quantize ( model , args . quant ). cuda ()
# 只需要 7GB 显存即可推理Este projeto está na versão V1. Os parâmetros e o volume de cálculo dos modelos visuais e de linguagem são relativamente pequenos. Resumimos as principais direções de melhoria:
O código deste repositório é open source de acordo com o acordo Apache-2.0. O uso dos pesos do modelo VisualGLM-6B precisa estar em conformidade com a Licença do Modelo.
Se você achar nosso trabalho útil, considere citar os seguintes artigos
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
@article{ding2021cogview,
title={Cogview: Mastering text-to-image generation via transformers},
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={19822--19835},
year={2021}
}
O conjunto de dados na fase de ajuste fino de instruções do VisualGLM-6B contém parte dos dados gráficos e de texto em inglês dos projetos MiniGPT-4 e LLAVA, bem como muitos conjuntos de dados de trabalho cross-modais clássicos. contribuições.


