Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Estabeleça sua configuração com: accelerate config e então: accelerate launch train.py
KOSMOS-1 usa uma arquitetura Transformer somente decodificadora baseada em Magneto (Foundation Transformers), ou seja, uma arquitetura que emprega uma abordagem chamada sub-LN onde a normalização da camada é adicionada antes do módulo de atenção (pré-ln) e depois (pós- ln) combinar as vantagens que ambas as abordagens têm para modelagem de linguagem e compreensão de imagens, respectivamente. O modelo também é inicializado de acordo com uma métrica específica também descrita no artigo, permitindo um treinamento mais estável em taxas de aprendizado mais altas.
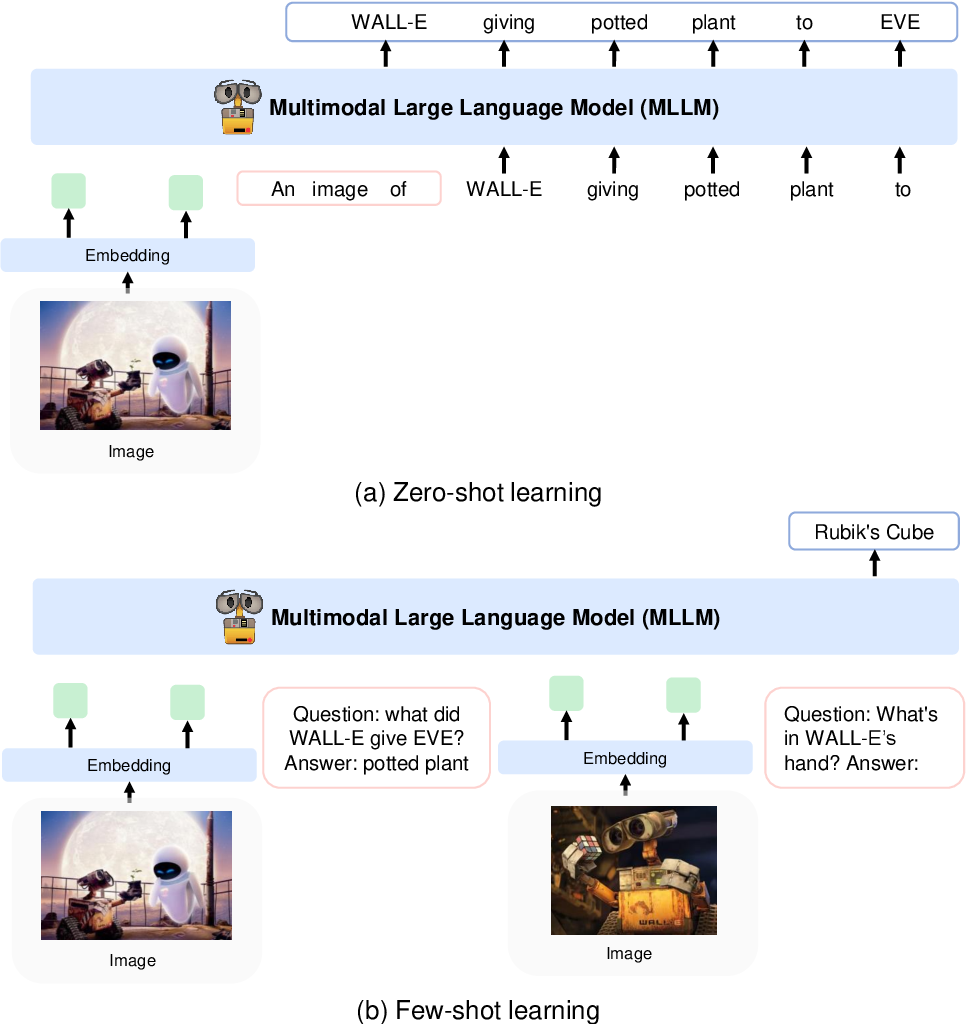
Eles codificam imagens em recursos de imagem usando um modelo CLIP VIT-L/14 e usam um reamostrador de percepção introduzido no Flamingo para agrupar os recursos de imagem de 256 -> 64 tokens. Os recursos de imagem são combinados com os embeddings de token, adicionando-os à sequência de entrada cercada por tokens especiais <image> e </image> . Um exemplo é <s> <image> image_features </image> text </s> . Isso permite que imagens sejam entrelaçadas com texto na mesma sequência.
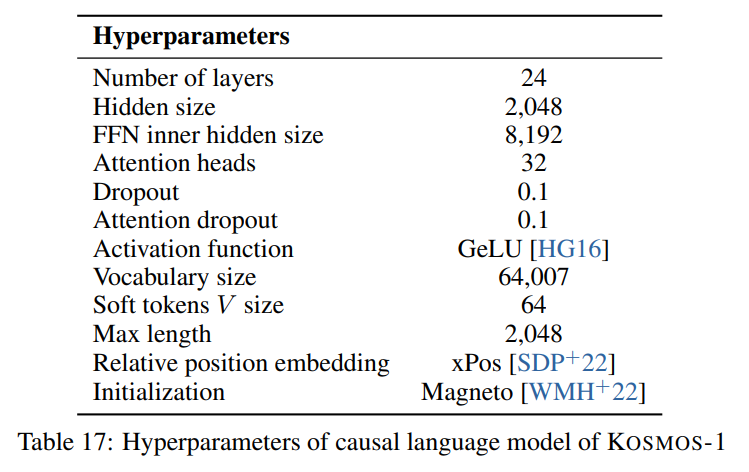
Seguimos os hiperparâmetros descritos no artigo visíveis na imagem a seguir:
Usamos a implementação em escala de tocha da arquitetura Transformer somente decodificador da Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Para o modelo de imagem (CLIP VIT-L/14) usamos um modelo OpenClip pré-treinado:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Seguimos os hiperparâmetros padrão para o reamostrador do percebedor, pois nenhum hiperparâmetro é fornecido no artigo:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Como o modelo espera uma dimensão oculta de 2048 , usamos uma camada nn.Linear para projetar os recursos da imagem na dimensão correta e inicializá-la de acordo com o esquema de inicialização do Magneto:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) O artigo descreve uma SentencePiece com um vocabulário de 64007 tokens. Para simplificar (já que não temos o corpus de treinamento disponível), usamos a próxima melhor alternativa de código aberto, que é o tokenizer T5-grande pré-treinado da HuggingFace. Este tokenizer possui um vocabulário de 32002 tokens.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Em seguida, incorporamos os tokens com uma camada nn.Embedding . Na verdade, usamos um bnb.nn.Embedding de bitandbytes que nos permite usar AdamW de 8 bits posteriormente.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Para incorporações posicionais, usamos:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Além disso, adicionamos uma camada de projeção de saída para projetar a dimensão oculta no tamanho do vocabulário e inicializá-la de acordo com o esquema de inicialização do Magneto:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) Tive que fazer algumas pequenas alterações no decodificador para permitir que ele aceitasse recursos já incorporados no passe direto. Isto foi necessário para permitir a sequência de entrada mais complexa descrita acima. As alterações são visíveis na seguinte comparação na linha 391 de torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Aqui está uma tabela de descontos com metadados para os conjuntos de dados mencionados no artigo:
| Conjunto de dados | Descrição | Tamanho | Link |
|---|---|---|---|
| A pilha | Corpus diversificado de textos em inglês | 800GB | Abraçando cara |
| Rastreamento comum | Dados de rastreamento da Web | - | Rastreamento comum |
| LAION-400M | Pares imagem-texto do rastreamento comum | 400 milhões de pares | Abraçando cara |
| LAION-2B | Pares imagem-texto do rastreamento comum | Pares 2B | ArXiv |
| COYO | Pares imagem-texto do rastreamento comum | 700 milhões de pares | GitHub |
| Legendas conceituais | Pares imagem-texto alternativo | 15 milhões de pares | ArXiv |
| Dados CC intercalados | Texto e imagens do Common Crawl | 71 milhões de documentos | Conjunto de dados personalizado |
| HistóriaCloze | Raciocínio de bom senso | 16 mil exemplos | Antologia ACL |
| HellaSwag | NLI de bom senso | 70 mil exemplos | ArXiv |
| Esquema Winograd | Ambigüidade de palavras | 273 exemplos | PKRR 2012 |
| Winogrande | Ambigüidade de palavras | 1,7 mil exemplos | AAAI 2020 |
| PIQA | Controle de qualidade de bom senso físico | 16 mil exemplos | AAAI 2020 |
| BoolQ | Controle de qualidade | 15 mil exemplos | ACL 2019 |
| CB | Inferência de linguagem natural | 250 exemplos | Sinn e Bedeutung 2019 |
| COPA | Raciocínio causal | 1k exemplos | Simpósio AAAI Primavera 2011 |
| Tamanho relativo | Raciocínio de bom senso | 486 pares | ArXiv 2016 |
| MemóriaCor | Raciocínio de bom senso | 720 exemplos | ArXiv 2021 |
| Termos de cores | Raciocínio de bom senso | 320 exemplos | ACL 2012 |
| Teste de QI | Raciocínio não verbal | 50 exemplos | Conjunto de dados personalizado |
| Legendas COCO | Legendagem de imagens | 413 mil imagens | PAMI 2015 |
| Flickr30k | Legendagem de imagens | 31 mil imagens | TACL 2014 |
| VQAv2 | Controle de qualidade visual | 1 milhão de pares de controle de qualidade | CVPR 2017 |
| VizWiz | Controle de qualidade visual | 31 mil pares de controle de qualidade | CVPR 2018 |
| WebSRC | Controle de qualidade da Web | 1,4 mil exemplos | EMNLP 2021 |
| ImageNet | Classificação de imagens | 1,28 milhões de imagens | CVPR 2009 |
| FILHOTE | Classificação de imagens | 200 espécies de aves | TOG 2011 |
APACHE


